
A large part of human humour depends on understanding that the intention of the person telling the joke might be different to what they are actually saying. The person needs to tell the joke so that you understand that they’re telling a joke, so they need to to know that you know that they do not intend to convey the meaning they are about to utter… Things get even more complicated when we are telling each other jokes that involve other people having thoughts and beliefs about other people. We call this knowledge nested intentions, or recursive mental attributions. We can already see, based on my complicated description, that this is a serious matter and requires scientific investigation. Fortunately, a recent paper by Dunbar, Launaway and Curry (2015) investigated whether the structure of jokes is restricted by the amount of nested intentions required to understand the joke and they make a couple of interesting predictions on the mental processing that is involved in processing humour, and how these should be reflected in the structure and funniness of jokes. In today’s blogpost I want to discuss the paper’s methodology and some of its claims.
Category: Research Blogging
Posture helps robots learn words, and infants, too.
What kind of information do children and infants take into account when learning new words? And to what extent do they need to rely on interpreting a speakers intention to extract meaning? A paper by Morse, Cangelosi and Smith (2015), published in PLoS One, suggests that bodily states such as body posture might be used by infants to acquire word meanings in the absence of the object named. To test their hypothesis, the authors ran a series of experiments using a word learning task with infants—but also a self-learning robot, the iCub.
Continue reading “Posture helps robots learn words, and infants, too.”
Languages adapt to their contextual niche (Winters, Kirby & Smith, 2014)
![]() Last week saw the publication of my latest paper, with co-authors Simon Kirby and Kenny Smith, looking at how languages adapt to their contextual niche (link to the OA version and here’s the original). Here’s the abstract:
Last week saw the publication of my latest paper, with co-authors Simon Kirby and Kenny Smith, looking at how languages adapt to their contextual niche (link to the OA version and here’s the original). Here’s the abstract:
It is well established that context plays a fundamental role in how we learn and use language. Here we explore how context links short-term language use with the long-term emergence of different types of language systems. Using an iterated learning model of cultural transmission, the current study experimentally investigates the role of the communicative situation in which an utterance is produced (situational context) and how it influences the emergence of three types of linguistic systems: underspecified languages (where only some dimensions of meaning are encoded linguistically), holistic systems (lacking systematic structure) and systematic languages (consisting of compound signals encoding both category-level and individuating dimensions of meaning). To do this, we set up a discrimination task in a communication game and manipulated whether the feature dimension shape was relevant or not in discriminating between two referents. The experimental languages gradually evolved to encode information relevant to the task of achieving communicative success, given the situational context in which they are learned and used, resulting in the emergence of different linguistic systems. These results suggest language systems adapt to their contextual niche over iterated learning.
Background
Context clearly plays an important role in how we learn and use language. Without this contextual scaffolding, and our inferential capacities, the use of language in everyday interactions would appear highly ambiguous. And even though ambiguous language can and does cause problems (as hilariously highlighted by the ‘What’s a chicken?’ case), it is also considered to be communicatively functional (see Piantadosi et al., 2012). In short: context helps in reducing uncertainty about the intended meaning.
If context is used as a resource in reducing uncertainty, then it might also alter our conception of how an optimal communication system should be structured (e.g., Zipf, 1949). With this in mind, we wanted to investigate the following questions: (i) To what extent does the context influence the encoding of features in the linguistic system? (ii) How does the effect of context work its way into the structure of language? To get at these questions we narrowed our focus to look at the situational context: the immediate communicative environment in which an utterance is situated and how it influences the distinctions a speaker needs to convey.
Of particular relevance here is Silvey, Kirby & Smith (2014): they show that the incorporation of a situational context can change the extent to which an evolving language encodes certain features of referents. Using a pseudo-communicative task, where participants needed to discriminate between a target and a distractor meaning, the authors were able to manipulate which meaning dimensions (shape, colour, and motion) were relevant and irrelevant in conveying the intended meaning. Over successive generations of participants, the languages converged on underspecified systems that encoded the feature dimension which was relevant for discriminating between meanings.
The current work extends upon these findings in two ways: (a) we added a communication element to the setup, and (b) we further explored the types of situational context we could manipulate. Our general hypothesis, then, is that these artificial languages should adapt to the situational context in predictable ways based on whether or not a distinction is relevant in communication.
Continue reading “Languages adapt to their contextual niche (Winters, Kirby & Smith, 2014)”
QWERTY: The Next Generation

[This is a guest post by
Oh wait, I’m not a guest anymore. Thanks to James for inviting me to become a regular contributor to Replicated Typo. I hope I will have to say some interesting things about the evoution of language, cognition, and culture, and I promise that I’ll try to keep my next posts a bit shorter than the guest post two weeks ago.
Today I’d like to pick up on an ongoing discussion over at Language Log. In a series of blog posts in early 2012, Mark Liberman has taken issue with the so-called “QWERTY effect”. The QWERTY effect seems like an ideal topic for my first regular post as it is tightly connected to some key topics of Replicated Typo: Cultural evolution, the cognitive basis of language, and, potentially, spurious correlations. In addition, Liberman’s coverage of the QWERTY effect has spawned an interesting discussion about research blogging (cf. Littauer et al. 2014).
But what is the QWERTY effect, actually? According to Kyle Jasmin and Daniel Casasanto (Jasmin & Casasanto 2012), the written form of words can influence their meaning, more particularly, their emotional valence. The idea, in a nutshell, is this: Words that contain more characters from the right-hand side of the QWERTY keyboard tend to “acquire more positive valences” (Jasmin & Casasanto 2012). Casasanto and his colleagues tested this hypothesis with a variety of corpus analyses and valence rating tasks.
Whenever I tell fellow linguists who haven’t heard of the QWERTY effect yet about these studies, their reactions are quite predictable, ranging from “WHAT?!?” to “asdf“. But unlike other commentors, I don’t want to reject the idea that a QWERTY effect exists out of hand. Indeed, there is abundant evidence that “right” is commonly associated with “good”. In his earlier papers, Casasanto provides quite convincing experimental evidence for the bodily basis of the cross-linguistically well-attested metaphors RIGHT IS GOOD and LEFT IS BAD (e.g. Casasanto 2009). In addition, it is fairly obvious that at the end of the 20th century, computer keyboards started to play an increasingly important role in our lives. More and more people have full size keyboards somewhere in their home. Also, it seems legitimate to assume that in a highly literate society, written representations of words form an important part of our linguistic knowledge. Given these factors, the QWERTY effect is not such an outrageous idea. However, measuring it by determining the “Right-Side Advantage” of words in corpora is highly problematic since a variety of potential confounding factors are not taken into account.
Finding the Right Name(s)
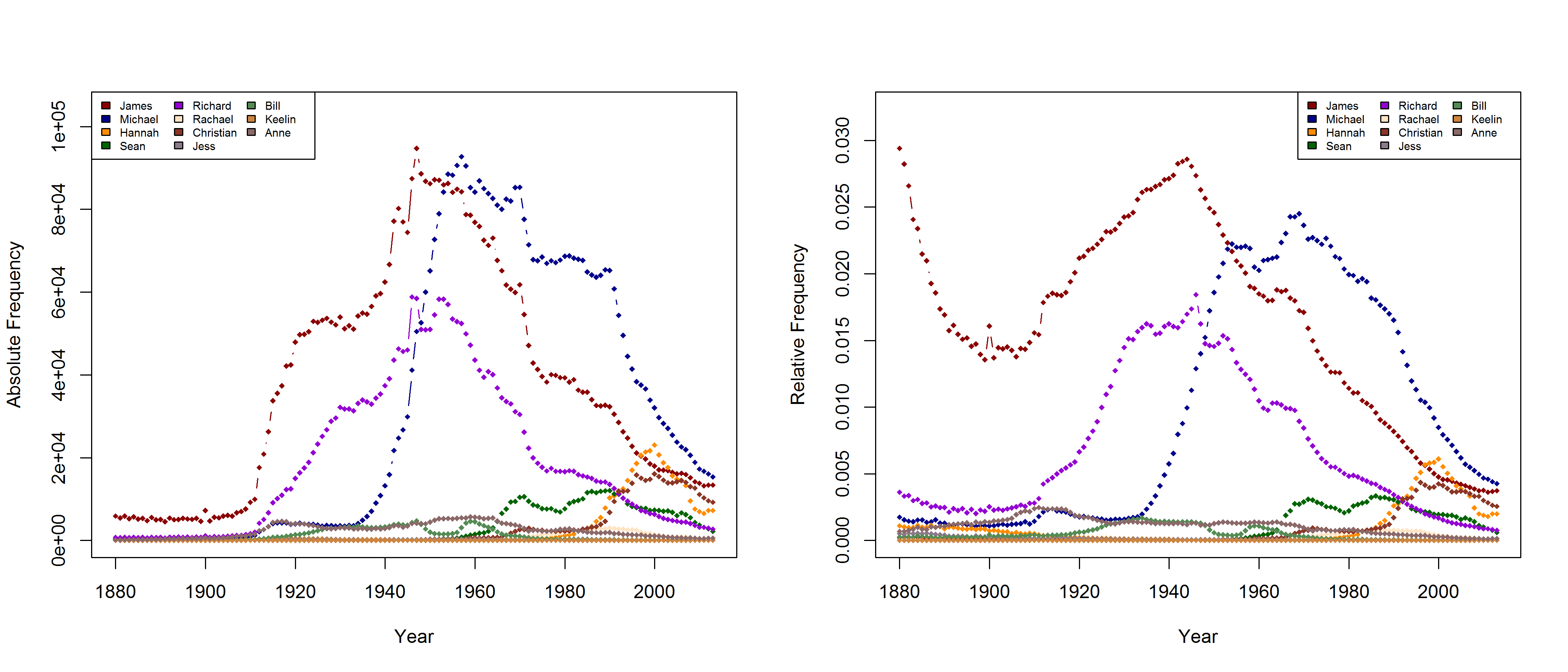
In a new CogSci paper, Casasanto, Jasmin, Geoffrey Brookshire, and Tom Gijssels present five new experiments to support the QWERTY hypothesis. Since I am based at a department with a strong focus on onomastics, I found their investigation of baby names particularly interesting. Drawing on data from the US Social Security Administration website, they analyze all names that have been given to more than 100 babys in every year from 1960 to 2012. To determine the effect of keyboard position, they use a measure they call “Right Side Adventage” (RSA): [(#right-side letters)-(#left-side letters)]. They find that
“that the mean RSA has increased since the popularization of the QWERTY keyboard, as indicated by a correlation between the year and average RSA in that year (1960–2012, r = .78, df = 51, p =8.6 × 10-12“
In addition,
“Names invented after 1990 (n = 38,746) use more letters from the right side of the keyboard than names in use before 1990 (n = 43,429; 1960–1990 mean RSA = -0.79; 1991–2012 mean RSA = -0.27, t(81277.66) = 33.3, p < 2.2 × 10-16 […]). This difference remained significant when length was controlled by dividing each name’s RSA by the number of letters in the name (t(81648.1) = 32.0, p < 2.2 × 10-16)”
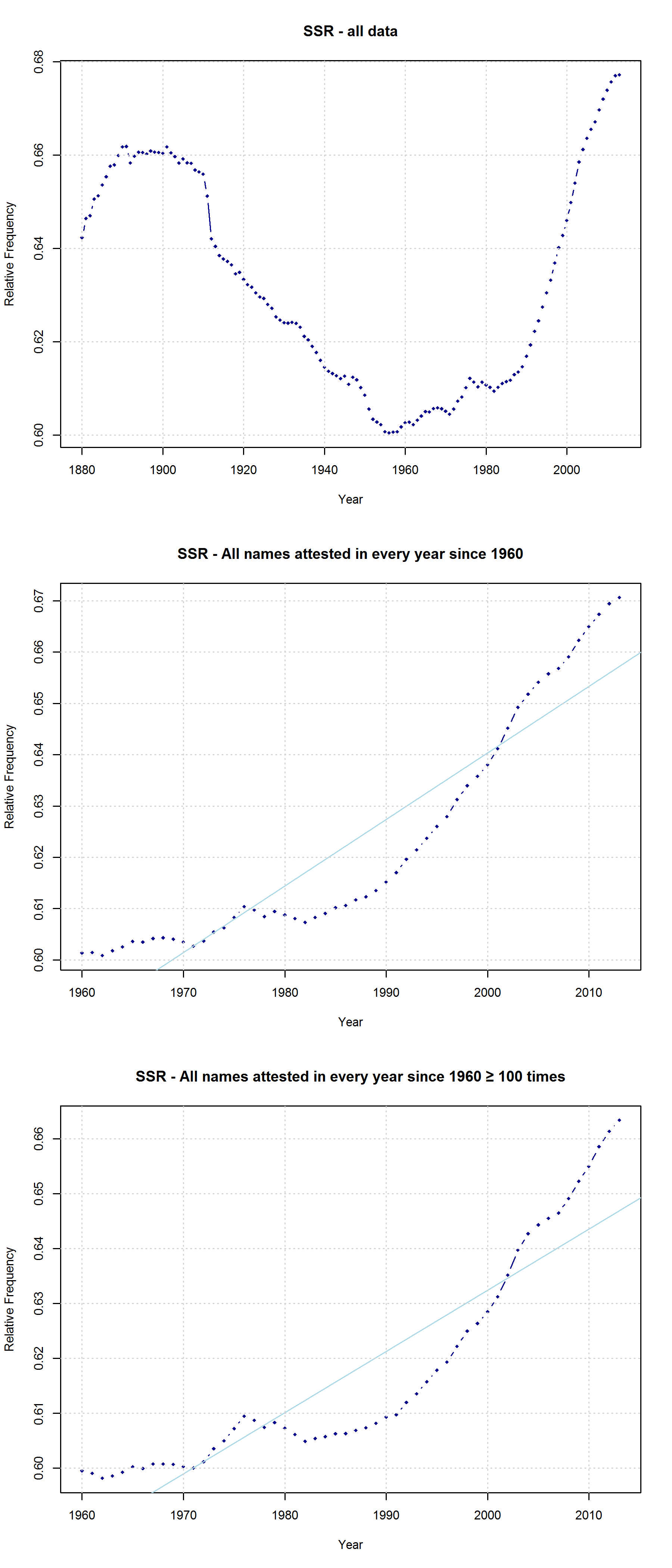
Mark Liberman has already pointed to some problematic aspects of this analysis (but see also Casasanto et al.’s reply). They do not justify why they choose the timeframe of 1960-2012 (although data are available from 1880 onwards), nor do they explain why they only include names given to at least 100 children in each year. Liberman shows that the results look quite different if all available data are taken into account – although, admittedly, an increase in right-side characters from 1990 onwards can still be detected. In their response, Casasanto et al. try to clarify some of these issues. They present an analysis of all names back to 1880 (well, not all names, but all names attested in every year since 1880), and they explain:
“In our longitudinal analysis we only considered names that had been given to more than 100 children in *every year* between 1960 and 2012. By looking at longitudinal changes in the same group of names, this analysis shows changes in names’ popularity over time. If instead you only look at names that were present in a given year, you are performing a haphazard collection of cross-sectional analyses, since many names come and go. The longitudinal analysis we report compares the popularity of the same names over time.“
I am not sure what to think of this. On the one hand, this is certainly a methodologically valid approach. On the other hand, I don’t agree that it is necessarily wrong to take all names into account. Given that 3,625 of all name types are attested in every year from 1960 to 2013 and that only 927 of all name types are attested in every year from 1880 to 2013 (the total number of types being 90,979), the vast majority of names is simply not taken into account in Casasanto et al.’s approach. This is all the more problematic given that parents have become increasingly individualistic in naming their children: The mean number of people sharing one and the same name has decreased in absolute terms since the 1960s. If we normalize these data by dividing them by the total number of name tokens in each year, we find that the mean relative frequency of names has continuously decreased over the timespan covered by the SSA data.
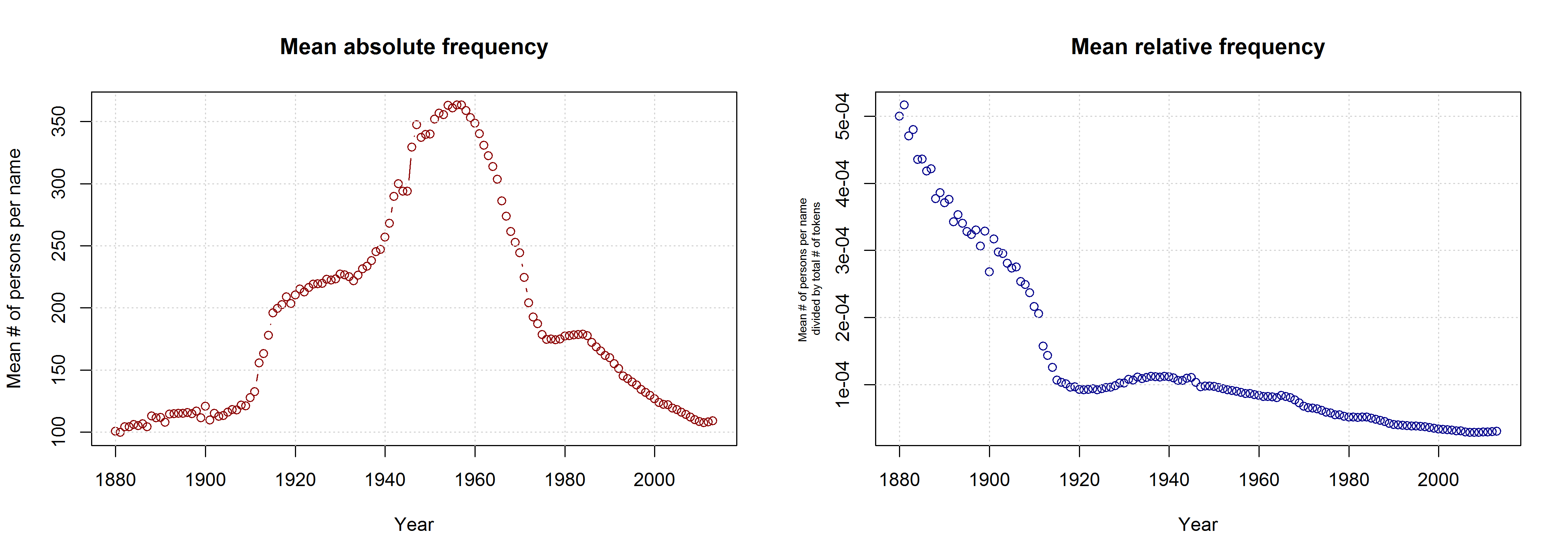
Thus, Casasanto et al. use a sample that might be not very representative of how people name their babies. If the QWERTY effect is a general phenomenon, it should also be found when all available data are taken into account.
As Mark Liberman has already shown, this is indeed the case – although some quite significant ups and downs in the frequency of right-side characters can be detected well before the QWERTY era. But is this rise in frequency from 1990 onwards necessarily due to the spread of QWERTY keyboards – or is there an alternative explanation? Liberman has already pointed to “the popularity of a few names, name-morphemes, or name fragments” as potential factors determining the rise and fall of mean RSA values. In this post, I’d like to take a closer look at one of these potential confounding factors.
Sonorous Sounds and “Soft” Characters
When I saw Casasanto et al.’s data, I was immediately wondering if the change in character distribution could not be explained in terms of phoneme distribution. My PhD advisor, Damaris Nübling, has done some work (see e.g. here [in German]) showing an increasing tendency towards names with a higher proportion of sonorous sounds in Germany. More specifically, she demonstrates that German baby names become more “androgynous” in that male names tend to assume features that used to be characteristic of (German) female names (e.g. hiatus; final full vowel; increase in the overall number of sonorous phonemes). Couldn’t a similar trend be detectable in American baby names?
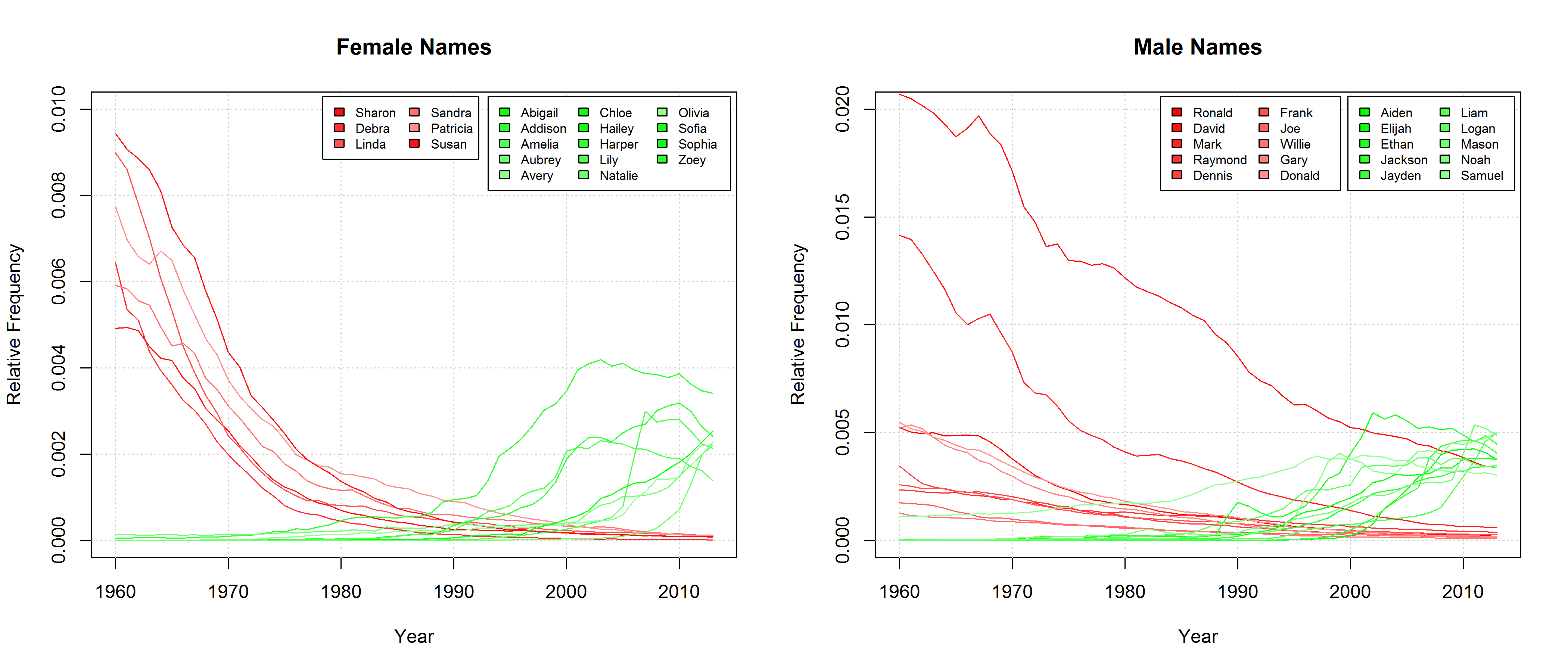
If we take a cursory glance at those names that can be found among the Top 20 most frequent names of at least one year since 1960 and if we single out those names that experienced a particularly strong increase or decrease in frequency, we find that, indeed, sonorous names seem to become more popular. Those names that gain in popularity are characterized by lots of vowels, diphthongs (Aiden, Jayden, Abigail), hiatus (Liam, Zoey), as well as nasals and liquids (Lily, Liam).
To be sure, these cursory observations are not significant in and of themselves. To test the hypothesis if phonological changes can (partly) account for the QWERTY effect in a bit more detail, I basically split the sonority scale in half. I categorized characters typically representing vowels and sonorants as “soft sound characters” and those typically representing obstruents as “hard sound characters”. This is of course a ridiculously crude distinction entailing some problematic classifications. A more thorough analysis would have to take into account the fact that in many cases, one letter can stand for a variety of different phonemes. But as this is just an exploratory analysis for a blog post, I’ll go with this crude binary distinction. In addition, we can justify this binary categorization with an argument presented above: We can assume that the written representations of words are an important part of the linguistic knowledge of present-day language users. Thus, parents will probably not only be concerned with the question how a name sounds – they will also consider how it looks like in written form. Hence, there might be a preference for characters that prototypically represent “soft sounds”, irrespective of the sounds they actually stand for in a concrete case. But this is highly speculative and would have to be investigated in an entirely different experimental setup (e.g. with a psycholinguistic study using nonce names).
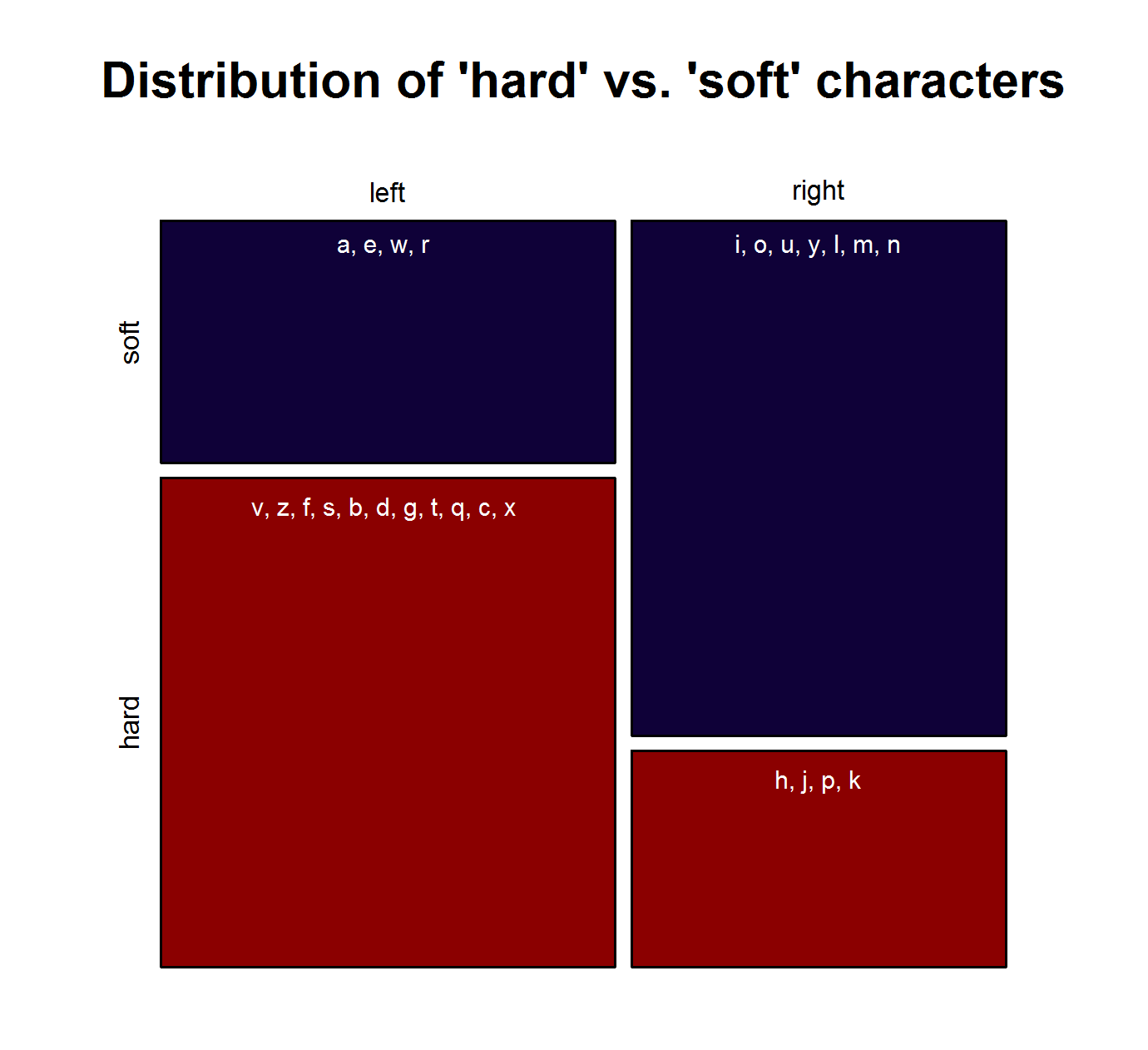
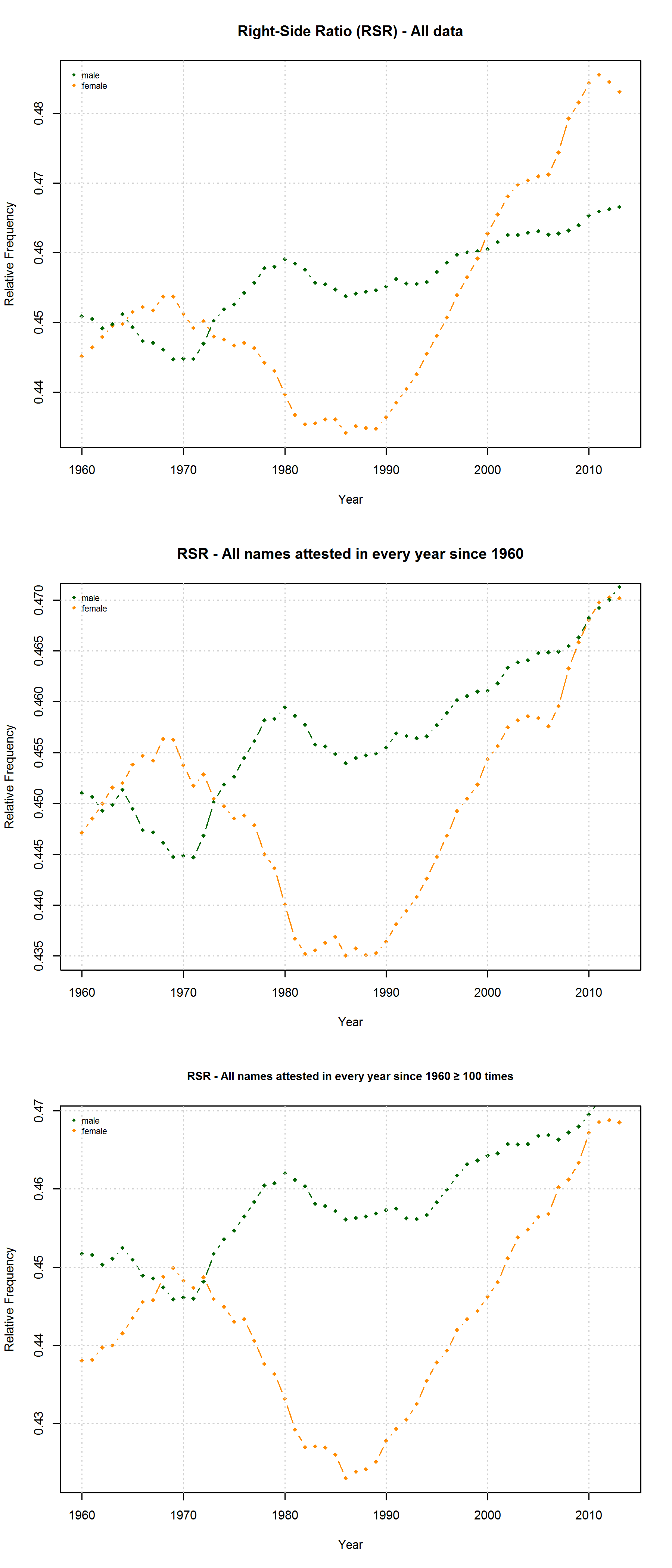
Note that the characters representing “soft sounds” and “hard sounds”, respectively, are distributed unequally over the QWERTY keyboard. Given that most “soft sound characters” are also right-side characters, it is hardly surprising that we cannot only detect an increase in the “Right-Side Advantage” (as well as the “Right-Side Ratio”, see below) of baby names, but also an increase in the mean “Soft Sound Ratio” (SSR – # of soft sound characters / total # of characters). This increase is significant for the time from 1960 to 2013 irrespective of the sample we use: a) all names attested since 1960, b) names attested in every year since 1960, c) names attested in every year since 1960 more than 100 times.
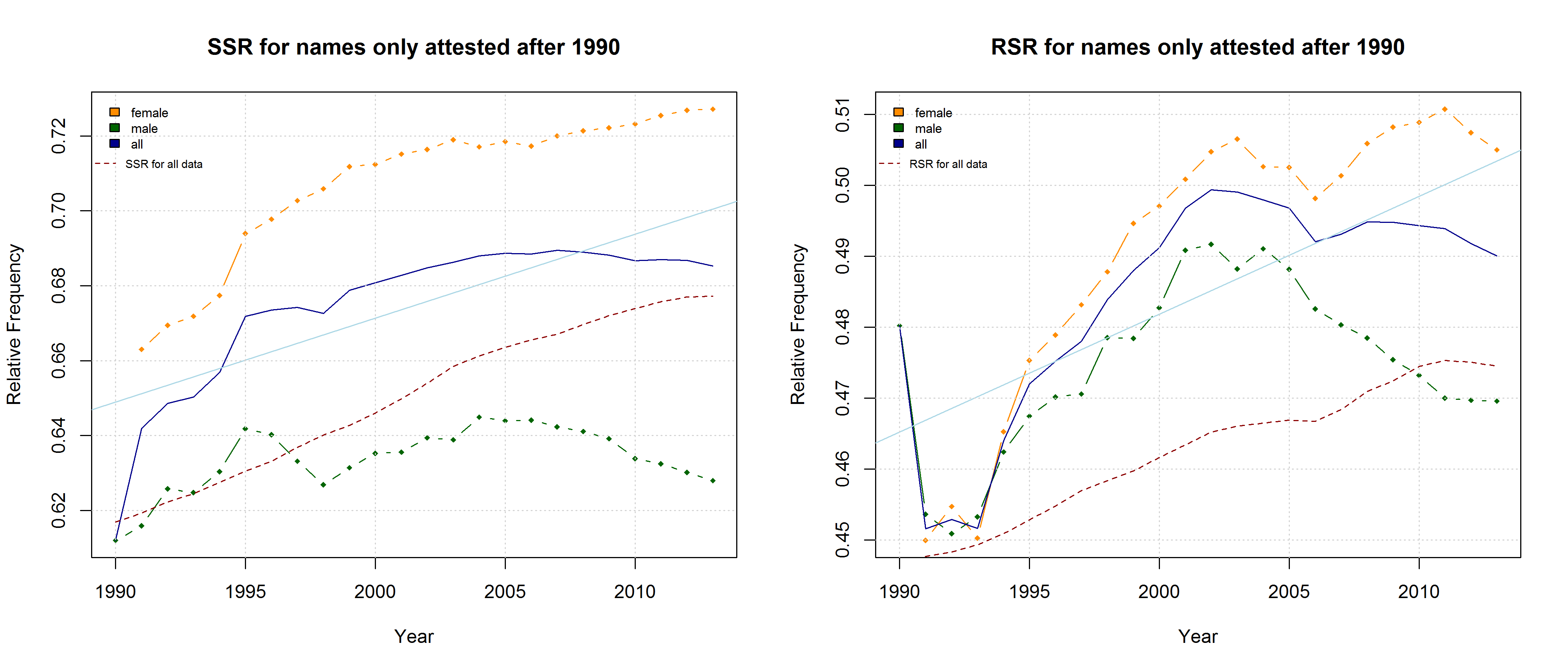
Note that both the “Right-Side Advantage” and the “Soft Sound Ratio” are particularly high in names only attested after 1990. (For the sake of (rough) comparability, I use the relative frequency of right-side characters here, i.e. Right Side Ratio = # of right-side letters / total number of letters.)
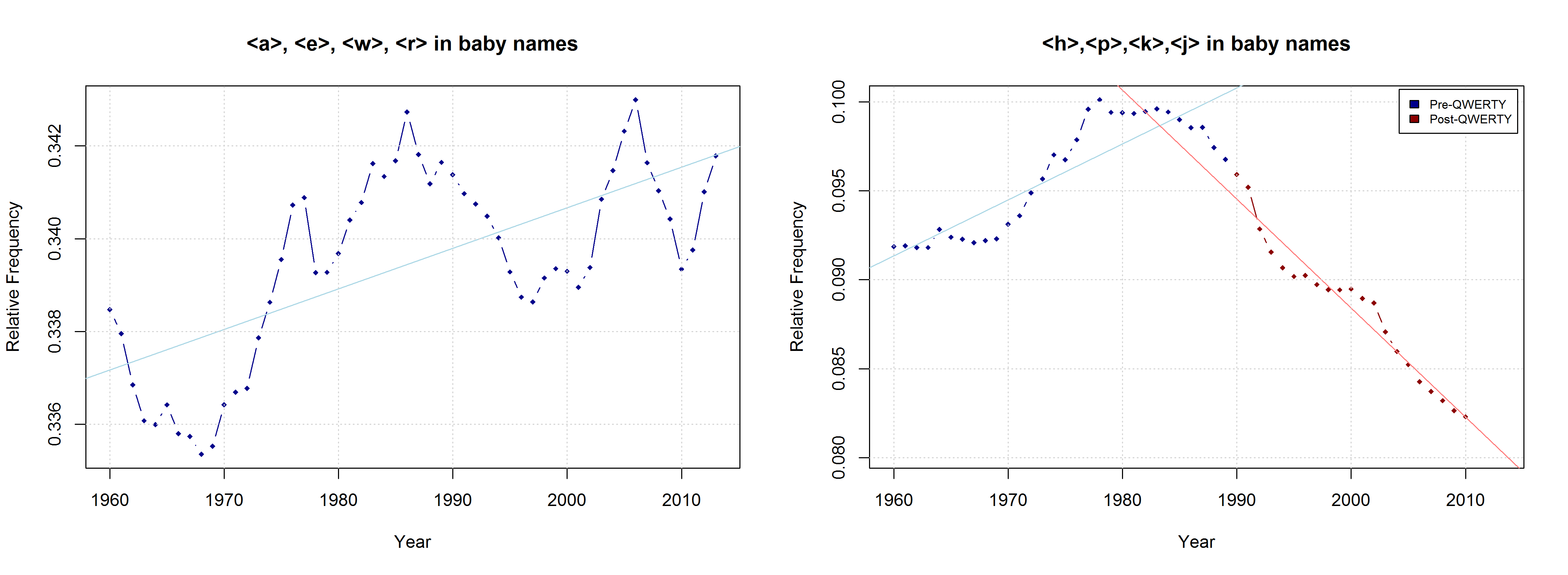
Due to the considerable overlap between right-side and “soft” characters, both the QWERTY Effect and the “Soft Sound” Hypothesis might account for the changes that can be observed in the data. If the QWERTY hypothesis is correct, we should expect an increase for all right-side characters, even those that stand for “hard” sounds. Conversely, we should expect a decrease in the relative frequency of left-side characters, even if they typically represent “soft” sounds. Indeed, the frequency of “Right-Side Hard Characters” does increase – in the time from 1960 to the mid-1980s. In the QWERTY era, by contrast, <h>, <p>, <k>, and <j> suffer a significant decrease in frequency. The frequency of “Left-Side Soft Characters”, by contrast, increases slightly from the late 1960s onwards.
Further potential challenges to the QWERTY Effect and possible alternative experimental setups
The commentors over at Language Log have also been quite creative in coming up with possible alternative explanations and challenging the QWERTY hypothesis by showing that random collections of letters show similarly strong patterns of increase or decrease. Thus, the increase in the frequency of right-side letters in baby names is perhaps equally well, if not better explained by factors independent of character positions on the QWERTY keyboard. Of course, this does not prove that there is no such thing as a QWERTY effect. But as countless cases discussed on Replicated Typo have shown, taking multiple factors into account and considering alternative hypotheses is crucial in the study of cultural evolution. Although the phonological form of words is an obvious candidate as a potential confounding factor, it is not discussed at all in Casasanto et al.’s CogSci paper. However, it is briefly mentioned in Jasmin & Casasanto (2012: 502):
“In any single language, it could happen by chance that words with higher RSAs are more positive, due to sound–valence associations. But despite some commonalities, English, Dutch, and Spanish have different phonological systems and different letter-to-sound mappings.”
While this is certainly true, the sound systems and letter-to-sound mappings of these languages (as well as German and Portugese, which are investigated in the new CogSci paper) are still quite similar in many respects. To rule out the possibility of sound-valence associations, it would be necessary to investigate the phonological makeup of positively vs. negatively connotated words in much more detail.
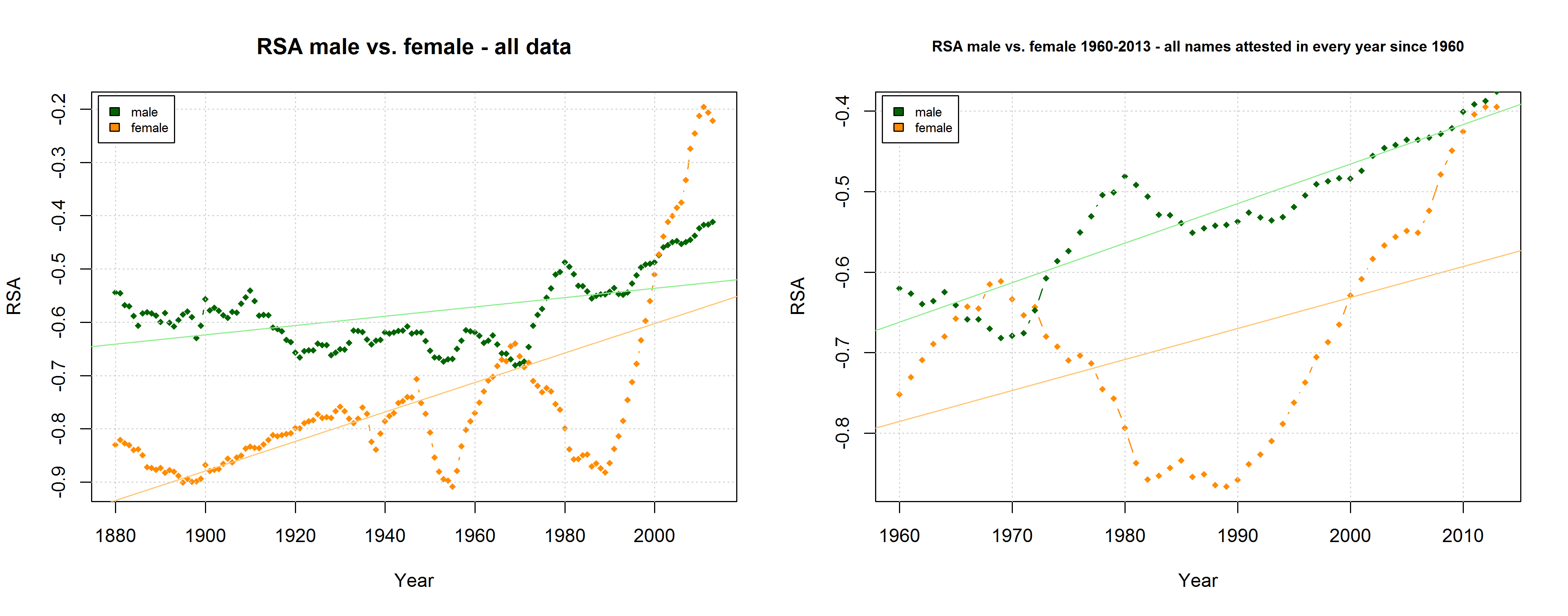
The SSA name lists provide another means to critically examine the QWERTY hypothesis since they differentiate between male and female names. If the QWERTY effect does play a significant role in parents’ name choices, we would expect it to be equally strong for boys names and girls names – or at least approximately so.
On the hypothesis that other factors such as trend names play a much more important role, by contrast, differences between the developments of male vs. female names are to be expected. Indeed, the data reveal some differences between the RSA / RSR development of boys vs. girls names. At the same time, however, these differences show that the “Soft Sound Hypothesis” can only partly account for the QWERTY Effect since the “Soft Sound Ratios” of male vs. female names develop roughly in parallel.
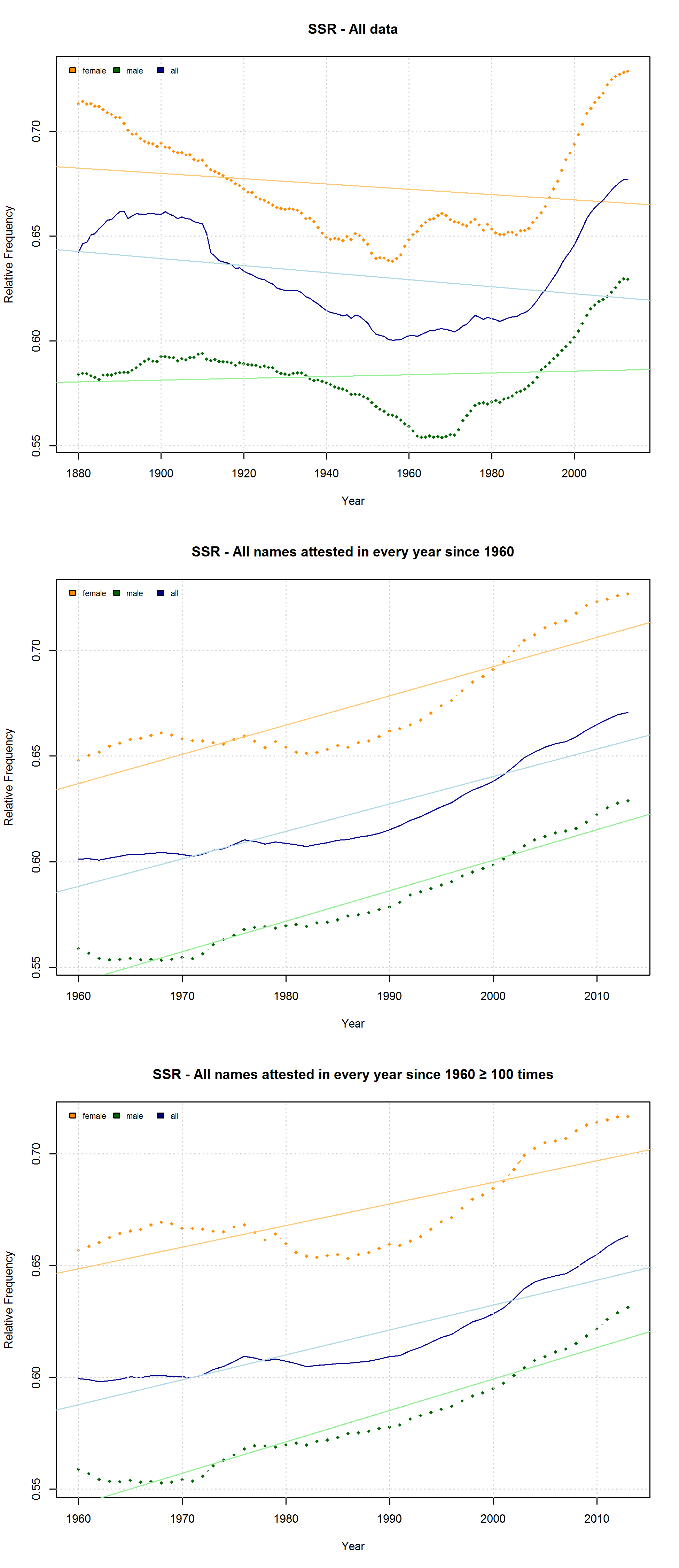
Given the complexity of cultural phenomena such as naming preferences, we would of course hardly expect one factor alone to determine people’s choices. The QWERTY Effect, like the “Soft Sound” Preference, might well be one factor governing parents’ naming decisions. However, the experimental setups used so far to investigate the QWERTY hypothesis are much too prone to spurious correlations to provide convincing evidence for the idea that words with a higher RSA assume more positive valences because of their number of right-side letters.
Granted, the amount of experimental evidence assembled by Casasanto et al. for the QWERTY effect is impressive. Nevertheless, the correlations they find may well be spurious ones. Don’t get me wrong – I’m absolutely in favor of bold hypotheses (e.g. about Neanderthal language). But as a corpus linguist, I doubt that such a subtle preference can be meaningfully investigated using corpus-linguistic methods. As a corpus linguist, you’re always dealing with a lot of variables you can’t control for. This is not too big a problem if your research question is framed appropriately and if potential confounding factors are explicitly taken into account. But when it comes to a possible connection between single letters and emotional valence, the number of potential confounding factors just seems to outweigh the significance of an effect as subtle as the correlation between time and average RSA of baby names. In addition, some of the presumptions of the QWERTY studies would have to be examined independently: Does the average QWERTY user really use their left hand for typing left-side characters and their right hand for typing right-side characters – or are there significant differences between individual typing styles? How fluent is the average QWERTY user in typing? (The question of typing fluency is discussed in passing in the 2012 paper.)
The study of naming preferences entails even more potentially confounding variables. For example, if we assume that people want their children’s names to be as beautiful as possible not only in phonological, but also in graphemic terms, we could speculate that the form of letters (round vs. edgy or pointed) and the position of letters within the graphemic representation of a name play a more or less important role. In addition, you can’t control for, say, all names of persons that were famous in a given year and thus might have influenced parents’ naming choices.
If corpus analyses are, in my view, an inappropriate method to investigate the QWERTY effect, then what about behavioral experiments? In their 2012 paper, Jasmin & Casasanto have reported an experiment in which they elicited valence judgments for pseudowords to rule out possible frequency effects:
“In principle, if words with higher RSAs also had higher frequencies, this could result in a spurious correlation between RSA and valence. Information about lexical frequency was not available for all of the words from Experiments 1 and 2, complicating an analysis to rule out possible frequency effects. In the present experiment, however, all items were novel and, therefore, had frequencies of zero.”
Note, however, that they used phonologically well-formed stimuli such as pleek or ploke. These can be expected to yield associations to existing words such as, say, peak connotated) and poke, or speak and spoke, etc. It would be interesting to repeat this experiment with phonologically ill-formed pseudowords. (After all, participants were told they were reading words in an alien language – why shouldn’t this language only consist of consonants?) Furthermore, Casasanto & Chrysikou (2011) have shown that space-valence mappings can change fairly quickly following a short-term handicap (e.g. being unable to use your right hand as a right-hander). Considering this, it would be interesting to perform experiments using a different kind of keyboard, e.g. an ABCDE keyboard, a KALQ keyboard, or – perhaps the best solution – a keyboard in which the right and the left side of the QWERTY keyboard are simply inverted. In a training phase, participants would have to become acquainted with the unfamiliar keyboard design. In the test phase, then, pseudowords that don’t resemble words in the participants’ native language should be used to figure out whether an ABCDE-, KALQ-, or reverse QWERTY effect can be detected.
References
Casasanto, D. (2009). Embodiment of Abstract Concepts: Good and Bad in Right- and Left-Handers. Journal of Experimental Psychology: General 138, 351–367.
Casasanto, D., & Chrysikou, E. G. (2011). When Left Is “Right”. Motor Fluency Shapes Abstract Concepts. Psychological Science 22, 419–422.
Casasanto, D., Jasmin, K., Brookshire, G., & Gijssels, T. (2014). The QWERTY Effect: How typing shapes word meanings and baby names. In P. Bello, M. Guarini, M. McShane, & B. Scassellati (Eds.), Proceedings of the 36th Annual Conference of the Cognitive Science Society. Austin, TX: Cognitive Science Society.
Jasmin, K., & Casasanto, D. (2012). The QWERTY Effect: How Typing Shapes the Meanings of Words. Psychonomic Bulletin & Review 19, 499–504.
Littauer, R., Roberts, S., Winters, J., Bailes, R., Pleyer, M., & Little, H. (2014). From the Savannah to the Cloud. Blogging Evolutionary Linguistics Research. In L. McCrohon, B. Thompson, T. Verhoef, & H. Yamauchi, The Past, Present, and Future of Language Evolution Research. Student Volume following the 9th International Conference on the Evolution of Language (pp. 121–131).
Nübling, D. (2009). Von Monika zu Mia, von Norbert zu Noah. Zur Androgynisierung der Rufnamen seit 1945 auf prosodisch-phonologischer Ebene. Beiträge zur Namenforschung 44.
The Myth of Language Universals at Birth
[This is a guest post by Stefan Hartmann]
“Chomsky still rocks!” This comment on Twitter refers to a recent paper in PNAS by David M. Gómez et al. entitled “Language Universals at Birth”. Indeed, the question Gómez et al. address is one of the most hotly debated questions in linguistics: Does children’s language learning draw on innate capacities that evolved specifically for linguistic purposes – or rather on domain-general skills and capabilities?
Lbifs, Blifs, and Brains
Gómez and his colleagues investigate these questions by studying how children respond to different syllable structures:
It is well known that across languages, certain structures are preferred to others. For example, syllables like blif are preferred to syllables like bdif and lbif. But whether such regularities reflect strictly historical processes, production pressures, or universal linguistic principles is a matter of much debate. To address this question, we examined whether some precursors of these preferences are already present early in life. The brain responses of newborns show that, despite having little to no linguistic experience, they reacted to syllables like blif, bdif, and lbif in a manner consistent with adults’ patterns of preferences. We conjecture that this early, possibly universal, bias helps shaping language acquisition.
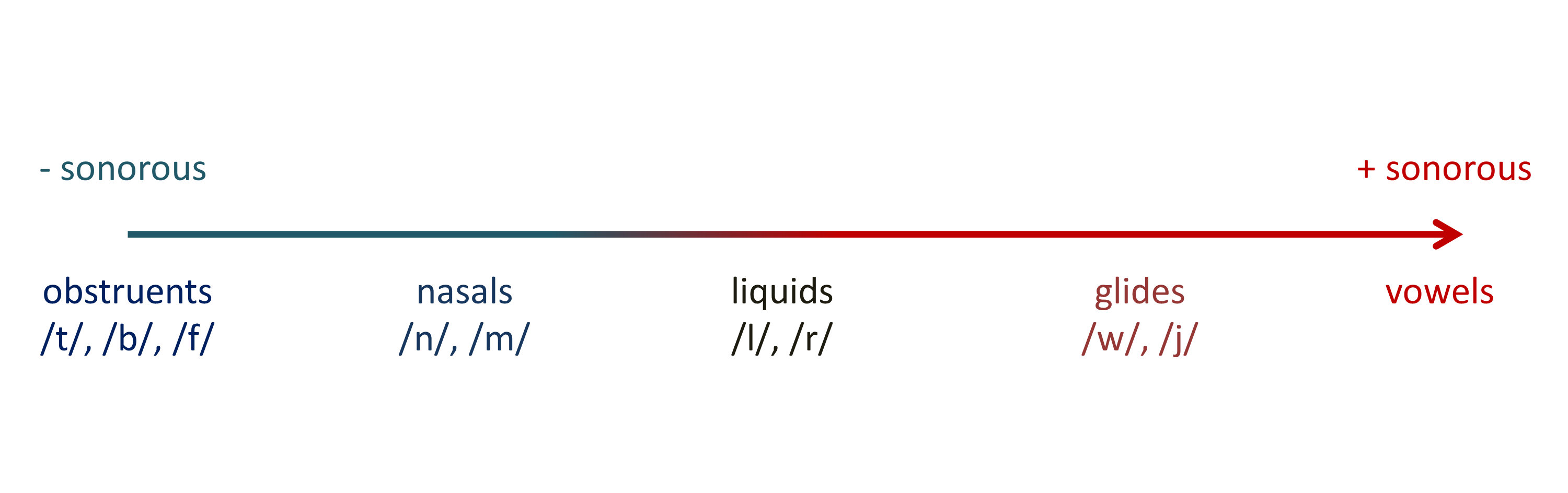
More specifically, they assume a restriction on syllable structure known as the Sonority Sequencing Principle (SSP), which has been proposed as “a putatively universal constraint” (p. 5837). According to this principle, “syllables maximize the sonority distance from their margins to their nucleus”. For example, in /blif/, /b/ is less sonorous than /l/, which is in turn less sonorous than the vowel /i/, which constitues the syllable’s nucleus. In /lbif/, by contrast, there is a sonority fall, which is why this syllable is extremely ill-formed according to the SSP.
In a first experiment, Gómez et al. investigated “whether the brains of newborns react differentially to syllables that are well- or extremely ill-formed, as defined by the SSP” (p. 5838). They had 24 newborns listen to /blif/- and /lbif/-type syllables while measuring the infant’s brain activities. In the left temporal and right frontoparietal brain areas, “well-formed syllables elicited lower oxyhemoglobin concentrations than ill-formed syllables.” In a second experiment, they presented another group of 24 newborns with syllables either exhibiting a sonority rise (/blif/) or two consonants of the same sonority (e.g. /bdif/) in their onset. The latter option is dispreferred across languages, and previous behavioral experiments with adult speakers have also shown a strong preference for the former pattern. “Results revealed that oxyhemoglobin concentrations elicited by well-formed syllables are significantly lower than concentrations elicited by plateaus in the left temporal cortex” (p. 5839). However, in contrast to the first experiment, there is no significant effect in the right frontoparietal region, “which has been linked to the processing of suprasegmental properties of speech” (p. 5838).
In a follow-up experiment, Gómez et al. investigated the role of the position of the CC-patterns within the word: Do infants react differently to /lbif/ than to, say, /olbif/? Indeed, they do: “Because the sonority fall now spans across two syllables (ol.bif), rather than a syllable onset (e.g., lbif), such words should be perfectly well-formed. In line with this prediction, our results show that newborns’ brain responses to disyllables like oblif and olbif do not differ.”
How much linguistic experience do newborns have?
Taken together, these results indicate that newborn infants are already sensitive for syllabification (as the follow-up experiment suggests) as well as for certain preferences in syllable structure. This leads Gómez et al. to the conclusion “that humans possess early, experience-independent linguistic biases concerning syllable structure that shape language perception and acquisition” (p. 5840). This conjecture, however, is a very bold one. First of all, seeing these preferences as experience-independent presupposes the assumption that newborn infants do not have linguistic experience at all. However, there is evidence that “babies’ language learning starts from the womb”. In their classic 1986 paper, Anthony DeCasper and Melanie Spence showed that “third-trimester fetuses experience their mothers’ speech sounds and that prenatal auditory experience can influence postnatal auditory preferences.” Pregnant women were instructed to read aloud a story to their unborn children when they felt that the fetus was awake. In the postnatal phase, the infants’ reactions to the same or a different story read by their mother’s or another woman’s voice were studied by monitoring the newborns’ sucking behavior. Apart from the “experienced” infants who had been read the story, a group of “untrained” newborns were used as control subjects. They found that for experienced subjects, the target story was more reinforcing than a novel story, no matter if it was recited by their mother’s or a different voice. For the control subjects, by contrast, no difference between the stories could be found. “The only experimental variable that can systematically account for these findings is whether the infants’ mothers had recited the target story while pregnant” (DeCasper & Spence 1986: 143).
On the entangled banks of representations (pt.1)

![]() Lately, I took time out to read through a few papers I’d put on the backburner until after my first year review was completed. Now that’s out of the way, I found myself looking through Berwick et al.‘s review on Evolution, brain, and the nature of language. Much of the paper manages to pull off the impressive job of making it sound as if the field has arrived on a consensus in areas that are still hotly debated. Still, what I’m interested in for this post is something that is often considered to be far less controversial than it is, namely the notion of mental representations. As an example, Berwick et al. posit that mind/brain-based computations construct mental syntactic and conceptual-intentional representations (internalization), with internal linguistic representations then being mapped onto their ordered output form (externalization). From these premises, the authors then arrive at the reasonable enough assumption that language is an instrument of thought first, with communication taking a secondary role:
Lately, I took time out to read through a few papers I’d put on the backburner until after my first year review was completed. Now that’s out of the way, I found myself looking through Berwick et al.‘s review on Evolution, brain, and the nature of language. Much of the paper manages to pull off the impressive job of making it sound as if the field has arrived on a consensus in areas that are still hotly debated. Still, what I’m interested in for this post is something that is often considered to be far less controversial than it is, namely the notion of mental representations. As an example, Berwick et al. posit that mind/brain-based computations construct mental syntactic and conceptual-intentional representations (internalization), with internal linguistic representations then being mapped onto their ordered output form (externalization). From these premises, the authors then arrive at the reasonable enough assumption that language is an instrument of thought first, with communication taking a secondary role:
In marked contrast, linear sequential order does not seem to enter into the computations that construct mental conceptual-intentional representations, what we call ‘internalization’… If correct, this calls for a revision of the traditional Aristotelian notion: language is meaning with sound, not sound with meaning. One key implication is that communication, an element of externalization, is an ancillary aspect of language, not its key function, as maintained by what is perhaps a majority of scholars… Rather, language serves primarily as an internal ‘instrument of thought’.
If we take for granted their conclusions, and this is something I’m far from convinced by, there is still the question of whether or not we even need representations in the first place. If you were to read the majority of cognitive science, then the answer is a fairly straight forward one: yes, of course we need mental representations, even if there’s no solid definition as to what they are and the form they take in our brain. In fact, the notion of representations has become a major theoretical tenet of modern cognitive science, as evident in the way much of field no longer treats it as a point of contention. The reason for this unquestioning acceptance has its roots in the notion that mental representations enriched an impoverished stimulus: that is, if an organism is facing incomplete data, then it follows that they need mental representations to fill in the gaps.
Continue reading “On the entangled banks of representations (pt.1)”
Ways To Protolanguage 3 Conference

Today is the first day of the “Ways to Protolanguage 3” conference. which takes place on 25–26 May in in Wrocław, Poland. The Plenary speakers are Robin Dunbar, Joesp Call, and Peter Gärdenfors
Both Hannah and I are at the conference and we’re also live-tweeting about the conference using the hashtag #protolang3
Hannah’s just given her talk
Jack J. Wilson, Hannah Little (University of Leeds, UK; Vrije Universiteit Brussel, Belgium) – Emerging languages in esoteric and exoteric niches: evidence from rural sign languages (abstract here)
And I’m due tomorrow.
Michael Pleyer (Heidelberg University, Germany) – Cooperation and constructions: looking at the evolution of language from a usage-based and construction grammar perspective (abstract here)
Sticking the tongue out: Early imitation in infants


The nativism-empiricism debate haunts the fields of language acquisition and evolution on more than just one level. How much of children’s social and cognitive abilities have to be present at birth, what is acquired through experience, and therefore malleable? Classically, this debate resolves around the poverty of stimulus. How much does a child have to take for granted in her environment, how much can she learn from the input?
Research into imitation has its own version of the poverty of stimulus, the correspondence problem. The correspondence problem can be summed up as follows: when you are imitating someone, you need to know which parts of your body map onto the body of the person you’re trying to imitate. If they wiggle their finger, you can establish correspondence by noticing that your hand looks similar to theirs, and that you can do the same movement with it, too. But this is much trickier with parts of your body that are out of your sight. If you want to imitate someone sticking their tongue out, you first have to realise that you have a tongue, too, and how you can move it in such a way that it matches your partner’s movements.
Continue reading “Sticking the tongue out: Early imitation in infants”
The New Pluralistic Approach

There has been a lot of talk round these parts recently of the merits of pluralistic approaches to problems in language evolution, and condemning the assignment of too much explanatory power to statistical correlations away from other forms of evidence, such as cultural learning experiments. Sean and James recently published a paper about this here which includes some commentary on Hay & Bauer (2007), who find that speaker population size and phoneme inventory size correlate (the more speakers a language has, the bigger its phoneme inventory is). James has blogged about this extensively here. More recently Moran, McCloy & Wright presented a critical analysis of Hay & Bauer’s (2007) findings here along with a statistical analysis of their own which uses more languages than Hay & Bauer (2007), and finds little to no correlation between speaker population and various measures of the phonological system, I hope James will do a blog about this as the resident expert.
As I’ve just mentioned, doing further statistical analysis is one good way of disputing or confirming the results of large scale statistical studies. But turning to experimental evidence is also a good way to back up the findings of statistical results and to tease out patterns of causation. I discuss this briefly here.
Recently, I was reading Selten & Warglien (2007) (mentioned by James here and covered by John Hawks here), which is a study which looks at how simple languages emerge within a coordination task with no initial shared language. The experiment uses pairwise interactions in which participants had to refer to figures which could be distinguished using features on three levels of outer shape, inner shape and colour (see picture). Participants were given a code which had a limited number of letters which they were to use to communicate with one another. However, the use of letters within this code had a cost within the language game the participants were playing, so the less letters they used the higher their score. Also, the more communicatively successful they were, the higher their score.

The study was primarily interested in what enhanced the emergence of structure in this code via the communication game. They looked at the effects of 2 variables, the number of letters available and variability in the set of figures. I am only going to discuss the effects of the first variable here. Selten & Warglien (2007) start off with an experiment where only two (and then three) letters were available which showed very little convergence to a common code. A common code is defined as being a code where the signals for all figures agree between the two participants. However, when given a larger inventory of letters to play with, participants were much more successful at creating a common code. This is not surprising as more symbols permit a higher degree of cost efficiency within the language game as you can use more distinct, shorter expressions. Selten & Warglien (2007) also make the point that the human capability to produce a large variety of phonetic signals seems to be at the root of the emergence of most linguistic structure, because if you only have a small inventory of individual units, you have to rely more on positional structure. Positional systems are systems like the Arabic number notation which are more likely invented rapidly rather than the product of slow emergence via cultural evolution, but can be easily used once they have emerged.
This is all very interesting in its own right, but the reason I brought it up in this post is that Selten & Warglien (2007) have shown that you can experimentally explore the effects of the size of inventory on an artificial language in a laboratory setting. I know that the natural direction of causation is to assume that demographic structure (e.g. the size of a population) affects the linguistic structure (e.g. the size of the phoneme inventory), but it might be possible to see whether a common code can be more easily reached within a small language community using only a small number of phonemes, than with a larger speaker community. I’m also not sure how one might create an experimental proxy for size of population in an experiment such as this (perhaps repeated interaction between the same participants compared with interaction within changing pairs). It might also be possible to look at the effects that the size of inventory can have on other linguistic features that have been hypothesised to correlate with population size, e.g. how regular the compositional structure of an emerging language is given difference inventory sizes.
References
Hay, J., & Bauer, L. (2007). Phoneme inventory size and population size Language, 83 (2), 388-400 DOI: 10.1353/lan.2007.0071
Roberts, S. & Winters, J. (2012). Social Structure and Language Structure: the New Nomothetic Approach. Psychology of Language and Communication, 16(2), pp. 79-183. Retrieved 12 Feb. 2013, from doi:10.2478/v10057-012-0008-6
Selten, R., & Warglien, M. (2007). The emergence of simple languages in an experimental coordination game Proceedings of the National Academy of Sciences, 104 (18), 7361-7366 DOI: 10.1073/pnas.0702077104
Is ambiguity dysfunctional for communicatively efficient systems?
Based on yesterday’s post, where I argued degeneracy emerges as a design solution for ambiguity pressures, a Reddit commentator pointed me to a cool paper by Piantadosi et al (2012) that contained the following quote:
The natural approach has always been: Is [language] well designed for use, understood typically as use for communication? I think that’s the wrong question. The use of language for communication might turn out to be a kind of epiphenomenon… If you want to make sure that we never misunderstand one another, for that purpose language is not well designed, because you have such properties as ambiguity. If we want to have the property that the things that we usually would like to say come out short and simple, well, it probably doesn’t have that property (Chomsky, 2002: 107).
The paper itself argues against Chomsky’s position by claiming ambiguity allows for more efficient communication systems. First of all, looking at ambiguity from the perspective of coding theory, Piantadosi et al argue that any good communication system will leave out information already in the context (assuming the context is informative about the intended meaning). Their other point, and one which they test through a corpus analysis of English, Dutch and German, suggests that as long as there are some ambiguities the context can resolve, then ambiguity will be used to make communication easier. In short, ambiguity emerges as a result of tradeoffs between ease of production and ease of comprehension, with communication systems favouring hearer inference over speaker effort:
The essential asymmetry is: inference is cheap, articulation expensive, and thus the design requirements are for a system that maximizes inference. (Hence … linguistic coding is to be thought of less like definitive content and more like interpretive clue.) (Levinson, 2000: 29).
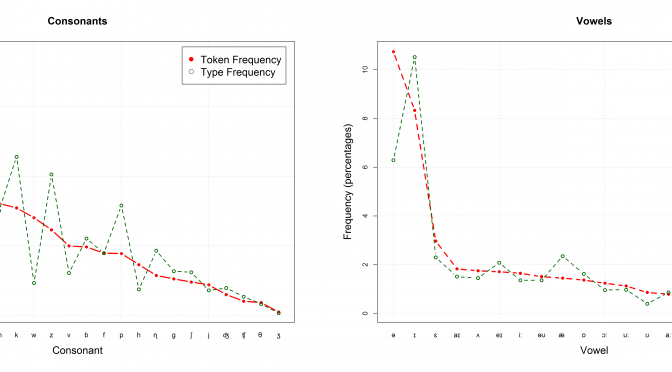
If this asymmetry exists, and hearers are good at disambiguating in context, then a direct result of such a tradeoff should be that linguistic units which require less effort should be more ambiguous. This is what they found in results from their corpus analysis of word length, word frequency and phonotactic probability:
We tested predictions of this theory, showing that words and syllables which are more efficient are preferentially re-used in language through ambiguity, allowing for greater ease overall. Our regression on homophones, polysemous words, and syllables – though similar – are theoretically and statistically independent. We therefore interpret positive results in each as strong evidence for the view that ambiguity exists for reasons of communicative efficiency (Piantadosi et al., 2012: 288).
At some point, I’d like to offer a more comprehensive overview of this paper, but this will have to wait until I’ve read more of the literature. Until then, here’s some graphs of the results from their paper:
Continue reading “Is ambiguity dysfunctional for communicatively efficient systems?”