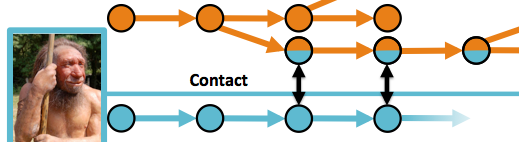
This week there’s an article about exploring Neandertal langauge in the New Scientist by Dan Dediu, Scott Moisik and I. It discusses the idea that if Neandertals spoke modern languages, and if there was cultural contact between us and them, then ancient human languages may have been affected by Neandertal language (borrowing, contact effects etc.). If this happened, then we may be able to detect these effects in today’s languages. The article and a recent blog post explains the idea, but I’ll cover some of the more technical stuff here.
Obviously, this is a very controversial idea: the time scale is much longer than the usual linguistic reconstruction and we have no direct evidence for Neandertals speaking complex languages. We’re definitely in for some flack. So, this post briefly covers what we actually did.
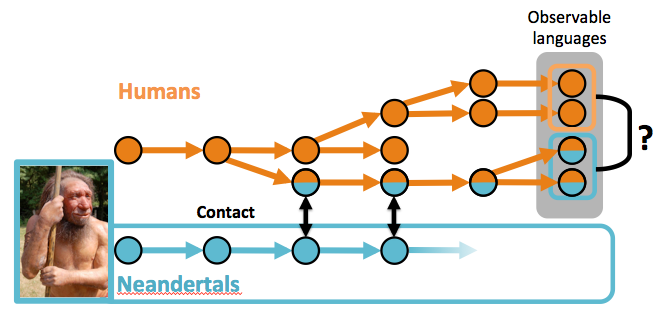
Our EvoLang paper (and a full paper in prep) asks whether one necessary condition for coming anywhere near providing evidence for this idea is true: Are there difference between current languages that were in contact (outside of Africa) and languages that were not in contact (inside Africa)? This has been addressed before, for different reasons (Cysouw & Comrie, 2009: pdf), but with a smaller sample of data.
Using data from WALS, we ran a few tests:
- STRUCTURE analysis: what is the most likely number of ‘founder’ populations that gives rise to the current diversity we see in African and Eurasian languages? Do the estimated founder populations align with African and non-African languages?
- K-means clustering: does a ‘natural’ statistical division between the world’s languages reflect a division between African and non-African languages? (is it better than chance and better than other continents? Also run on phonetic data from PHOIBLE and lexical data from the ASJP)
- Weighted multidimensional scaling: If we compress WALS to a few dimensions, does the first dimension reflect a distinction between African and non-African languages?
- Phylogenetic reconstruction: We reconstruct the cultural evolution of present-day language families to see if African and non-African languages have different cultural evolutionary biases (e.g. more likely to move towards or away from particular traits). We used 3 phylogenies (WALS, Ethnologue, Glottolog), 3 branch length scaling assumptions (Grafen’s method, NNLS and UPGMA) and 3 methods of ancestral state reconstruction (Maximum parsimony, Maximum likelihood (BayesTraits) and Maximum likelihood (APE)). We searched for features that have opposing biases in African and non-African languages that are bigger than 95% of all comparisons and are robust across all assumptions.
- Support Vector Machine learning: We trained a Support Vector Machine (a supervised machine learning algorithm) to tell the difference between African and non-African languages. We assessed the performance on unseen data, and also extract the most decisive linguistic features for making the distinction. We estimate the number of features needed to get good results.
- Binary classification trees: This algorithm finds linguistic features to divide the data into sub-sets in a way that maximises the ease of differentiating African and non-African languages.
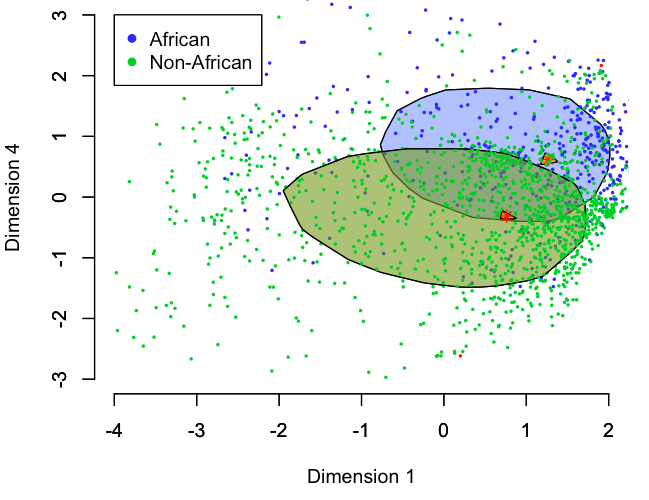
The detailed results will appear in our paper, but here’s what we conclude:
- Some of the tests result in positive answers. For example, the support vector machine analysis could differentiate between African and non-African typologies with 93% accuracy. However, the algorithm needs at least linguistic 50 variables to make this distinction, so it’s unclear whether it’s picking up on actual differences, or just gaps in the data.
- While some tests passed, our criterion was that ALL of the tests should pass for us to be at all confident of a statistical difference between African and non-African languages. Some tests fail, so we can’t support this.
- However, most of the problems we ran into were due to a lack of data. We could get better estimates if we had more typological data of better quality from existing languages. Another problem was implicational universals – particular typological variables are correlated because they affect each other (e.g. verb-object order and prepositions/postpositions), causing patterns in the world’s languages that are confounded with geographic areas.
- There’s a bigger question of whether, in theory, we can tell the difference between drift, contact effects, areal effects and language death. Contact with Neandertals may just be too far into the past, with too many human languages dying in the meantime, to make this distinction possible.
So, our conclusion is that any attempt to reconstruct Neandertal languages will fail with the current data and theory we have. Not surprising, really. The interesting thing, for me, is that we actually have methods that can give us quantitative answers about this idea, and the answer might change as we document more languages and develop theories about historical change and contact. As Chris Knight described our EvoLang presentation, this is one of my “most exciting and least conclusive” studies.
These are spoken languages? Is there any way to incorporate non-spoken communication?
That’s an interesting question, and probably has two answers depending on what you meant by ‘non-spoken communication’. If you mean culturally specific gestures (e.g. ‘thumbs-up’ or the bull horns, here’s a fun article: http://www.huffingtonpost.com/gayle-cotton/cross-cultural-gestures_b_3437653.html), then maybe yes, in principle. The reconstruction of spoken languages is done is by collecting data from different languages and creating typologies. Given typologies of non-spoken communication, the same methods could be applied (although the cultural evolution of non-spoken communication probably doesn’t work in exactly the same way as for spoken language). There are researchers who do this, but there’s not as much data available as for spoken languages – and we found that there wasn’t even enough data on spoken languages to do what we wanted.
However, if you mean involuntary non-spoken communication like smiling, sweating, pupil dilation and so on (perhaps more like ‘cues’ than ‘signals’), then I’m not sure. Either the tendencies are common to many mammals, and so attributing them to Neandertals would be trivial, or they would depend much more on physiological and developmental attributes, and I don’t know enough about this field to say much. But probably the route that would make most sense is a study of Neandertal genetics rather than a cultural evolution study like we’ve suggested.
A little off on a tangent, but i was wondering what your (and your co-authors?) take was on the rebuttal of the Deviu & Levinson Neanderthal article published in Frontiers by Berwick et al here: http://journal.frontiersin.org/Journal/10.3389/fpsyg.2013.00671/full. I don’t really know much about evolutionary psychology, which makes it difficult for me to properly evaluate the claims, but Berwick et al.’s skepticism seems fairly well-grounded. Your New Scientist article implicitly endorses the conclusions of Deviu & Levinson, e.g. here: “Archaeological remains show that they had a sophisticated lifestyle,
with human traits like caring for the infirm and the sick, and an
advanced toolkit, including bone tools and body paint – complex
behaviour that should only be possible if they had language”. From my naive POV i don’t really see how that follows.
Yes, it’s put rather strongly in the NS article (partly an editorial choice). It’s definitely true that a lot more evidence is needed to be able decide whether this is the case. Berwick et al. provide a serious rebuttal, and I appreciate their expertise in this debate. Honestly, I’m not really think-skinned enough to enter this debate with any force, but here’s my thoughts:
Though I can’t speak for the other authors, it seems like there is a strange imbalance in Berwick et al.’s rebuttal. They argue that the evidence is not strong enough to make a judgement, but also that a gradualist view where Neandertals had modern language capacities must be wrong. It’s not clear to me what the a-priori expectation should be about whether Neandertals had language. Certainly, assuming that they did have language threatens a certain view of what the core aspect of language is, and how it evolved (this relates to another debate covered here: http://www.replicatedtypo.com/the-mystery-of-language-evolution/8497.html). I think there’s a certain onus on each party to support their case, and that’s what the Dediu & Levinson paper does.
However, the issue we address in the NS article is about cultural evolution, rather than biological evolution. We ask: is it possible to detect the effects of contact with Neandertals in the cultural history of our languages? While this assumes that Neandertals did have some kind of complex communication, it doesn’t depend on “specific genetic differences in African vs. non-African human populations that led to specifically different phenotypic language traits”, as Berwick et al. note in their criticism of the D&L paper. We suggest that it is possible in principle, and we even have methods that could investigate this. However, in practice we don’t yet have enough data, we don’t understand cultural evolution at this time-scale well enough and the signal may be too noisy. Still, we think it’s an interesting possibility, and another reason why documenting the world’s languages is a valuable undertaking.
Thanks for that thorough answer, Sean. I hadn’t thought to differentiate. I use both in my writing–I’m going to have to think about this.