This year’s EvoLang is busy – around 100 talks in 4 parallel sessions and 40 posters. Replicated Typo is hosting a series of EvoLang previews to help people decide on what to go and see. If you’d like to post a preview of your own presentation, please get in touch with [email protected].
Roberts, Dediu & Levinson. Detecting differences between the languages of Neanderthals and modern humans. Thursday, 17:45, session A.
Recently, Dediu & Levinson (2013) argued that, given recent genetic and archaeological evidence, the default assumption should be that Neandertals spoke modern languages (not protolanguages). Dediu will be giving a talk on this work in the same session. My talk will discuss whether there are methods that can test these ideas. Is there any way to estimate what Neandertal languages were like? It’s a controversial topic, but could have big implications for the field.
The idea is the following: When two groups that speak different languages come into contact, bits and pieces of language are often borrowed. Linguists have used the similarities and differences between languages to reconstruct historical events such as contact between populations. Much of this work has been done on a case-by-case basis on existing or written languages, but there are also quantitative large-scale work that reaches further back. For example, Russell Gray and colleagues have demonstrated that differences in basic vocabulary can predict ancient migrations in polynesia.
We now know that there was contact between humans and Neandertals, and if Neandertals had modern language then we may have borrowed linguistic features from them. This could mean that there are bits and pieces in languages spoken today that were influenced by contact with Neandertals. We might expect these bits and pieces to be different from human languages, either because they were culturally adapted to Neandertal cognitive or physical biases (e.g. Neandertals had bigger mouths), or just because Neandertal languages explored different areas of the possible space of languages than human ones.
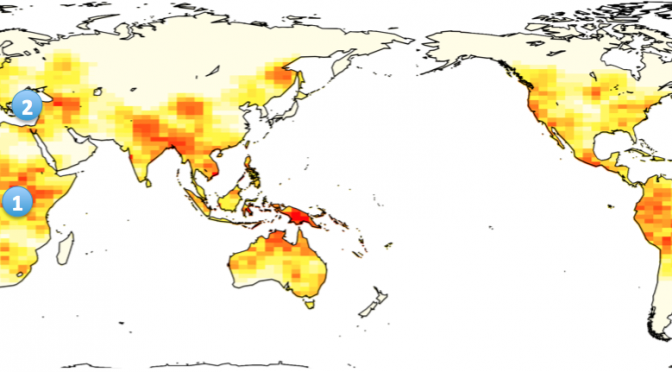
The task, then, is to find aspects of language that differ between populations that were in contact with Neandertals (Eurasia) and those that were not (most of Africa). However, this is harder than traditional historical linguistic analysis because (a) there is no record of Neandertal languages for comparison (b) the events we are reconstructing happened much further back than most analyses and (c) in order for the Neandertal bits to ‘survive’, the rate of cultural change would have to be very slow.
Our first attempt at this analysis used the World Atlas of Language Structures. We used k-means clustering to split the world’s languages into two groups so that languages within a group are more similar to each other than to languages in the other group. We then use permutation tests to determine whether the categories that come out of this procedure align better with the African/Non-African distinction than would be expected by chance. If so, this suggests that there is a statistical signal that we can utilise.
We also used what we know about how languages are related historically to estimate the features of the founding language of a language family (e.g. Indo-European or Atlantic-Congo). This removes some of the noise from the present-day data and also gives us an estimate of how biased each language family is towards using a particular linguistic feature. We can then look for linguistic features that change slowly and where African and Eurasian language families have opposing cultural evolutionary biases. These are candidates for Neadndertal language features. We don’t expect that there is a single feature that stands out as being different between African and non-African languages, but rather that there might be a collection of features that are different. I’ll demonstrate a method that uses Support Vector Machines to extract a list of candidate features, then test how many variables are needed to make
Since the evidence is very indirect, the key to these claims is robustness. We run each analysis with 3 different phylogenetic trees, 3 types of branch length assumptions and 3 types of ancestral reconstruction models. This probably represents one of the widest-scale historical linguistic reconstructions yet attempted.
We also estimated the number of founding populations for the amount of linguistic diversity in Africa and Eurasia. This was done using the STRUCTURE program, which is used to estimate founding populations for genetic diversity. For languages, the best-fitting model is one with two founding populations. This is consistent with contact with Neandertals, but also a lot of other effects.
In the end, it looks like we don’t currently have enough data of a high enough quality to answer these questions. However, I think it’s interesting that the methods exist and that the questions raised by Dediu & Levinson are actually empirically testable. Furthermore, the data we need is not necessarily data on ancient languages, but current ones that are undocumented. That is, we can actually get the data we need. There are already several large-scale databases of languages that are being put together. It’s an exciting time for linguistics.
Hi Sean,
Thanks for posting this. I won’t get chance to see the talk at EvoLang as I’m giving a talk in the parallel session! I do have a few comments.
First, this sounds like exciting work, especially the methodological basis, but I do worry about some outstanding questions that need to be answered before we press ahead with claims about Neanderthal language(s).
The first claim that we can detect stable linguistic features is probably the strongest aspect about this research. Of course, the time depth is questionable, and I’m not sure whether we’ll ever get the resolution needed to extract any meaningful signals regarding Neanderthal language features.
The second claim is that we know linguistic features can diffuse across languages. However, there is nothing to say that linguistic features which diffuse across languages are stable. That is, the slow-changing features we observe in language might be less prone to diffusion across languages. The reasons why they persist in a certain language family is because of descent (ignoring universals due to physical and cognitive constraints). It could be the case that features which easily diffuse are also fast-changing. This is an empirical question which I think might be answered by your work.
If it’s the case that features which diffuse are also prone to change and/or being lost, then this significantly reduces the likelihood you’re going to get much information about the diffusion of linguistic traits in ancient populations. On the other hand, if features that diffuse also show a trend in becoming stable features of a linguistic system, then this would certainly bolster your argument. Of course, it might be the case that there isn’t a trend either way, and some features that diffuse are stable and others aren’t (this could be due to social and functional factors underpinning selection).
I guess this can be condensed down to two questions:
(1) What linguistic features are prone to diffusion?
(2) Are these linguistic features considered to be diachronically stable?
My guess is that features that are prone to diffusion are also those that are less stable over diachronic time (mainly because they are less integrated in the core linguistic system).
Just saw this. Thanks for the comments! It’s a good idea to try and see if there’s a link between diffusability and stability. But it’s also possible that a single change in one feature can have knock-on effects in other features, pushing a language into a different region of the design space. This is one way that individual traits might be lost over time, but systems that had contact with Neandertals diverge over time. Still, it’s true that a much better understanding of language change is needed before we can make anywhere near solid claims.