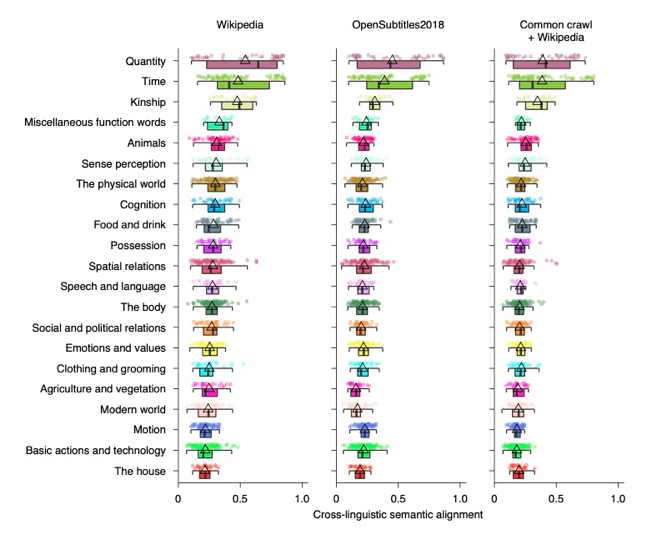
This year at EvoLang, I’m releasing CHIELD: The Causal Hypotheses in Evolutionary Linguistics Database. It’s a collection of theories about the evolution of language, expressed as causal graphs. The aim of CHIELD is to build a comprehensive overview of evolutionary approaches to language. Hopefully it’ll help us find competing and supporting evidence, link hypotheses together into bigger theories and generally help make our ideas more transparent. You can access CHIELD right now, but hang around for details of the challenges.
The first thing that CHIELD can help express is the (sometimes unexpected) causal complexity of theories. For example, Dunbar (2004) suggests that gossip replaced physical grooming in humans to support increasingly complicated social interactions in larger groups. However, the whole theory is actually composed of 29 links, involving predation risk, endorphins and resource density:
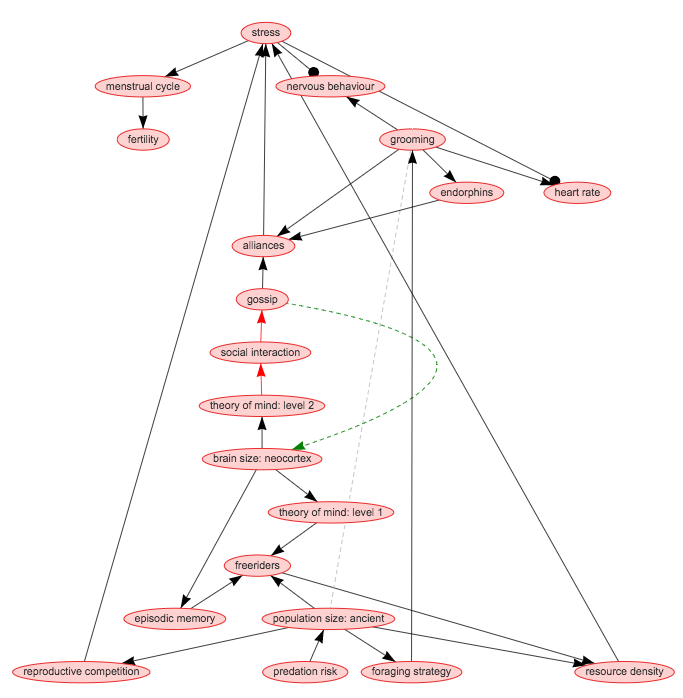
The graph above might seem very complicated, but it was actually constructed just by going through the text of Dunbar (2004) and recording each claim about variables that were causally linked. By dividing the theory into individual links it becomes easier to think about each part.
Second, CHIELD also helps find other theories that intersect with this one through variables like theory of mind, population size or the problem of freeriders, so you can also use CHIELD to explore multiple documents at once. For example, here are all the connections that link population size and morphological complexity (9 papers so far in the database):
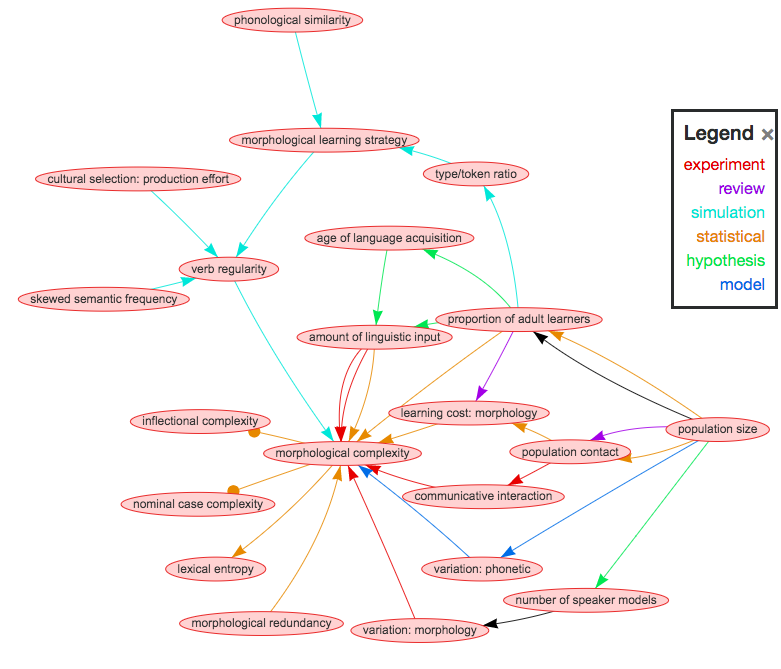
The first thing to notice is that there are multiple hypotheses about how population size and morphological complexity are linked. We can also see at a glance that there are different types of evidence for each link. Some are supported from multiple studies and methods, while others are currently just hypotheses without direct evidence.
However, CHIELD won’t work without your help! CHIELD has built-in tools for you – yes YOU – to contribute. You can edit data, discuss problems and add your own hypotheses. It’s far from perfect and of course there will be disagreements. But hopefully it will lead to productive discussions and a more cohesive field.
Which brings us to the challenges …
The EvoLang Causal Graph challenge: Contribute your own hypotheses
You can add data to CHIELD using the web interface. The challenge is to draw your EvoLang paper as a causal graph. It’s fun! The first two papers to be contributed will become part of my poster at EvoLang.
Here are some tips:
- Break down your hypothesis into individual causal links.
- Try to use existing variable names, so that your hypothesis connects to other work. You can find a list of variables here, or the web interface will suggest some. But don’t be afraid to add new variables.
- Try to add direct quotes from the paper to the “Notes” field to support the link.
- If your paper is already included, do you agree about the interpretation? If not, you can raise an issue or edit the data yourself.
More help is available here. Click here to add data now! Your data will become available on CHIELD, and your name will be added to the list of contributors.
Bonus Challenge: Contribute 5 papers, become a co-author!
I’ll be writing an article about the database and some initial findings for the Journal of Language Evolution. If you contribute 5 papers or more, then you’ll be added as a co-author. As an incentive to contribute further, co-authors will be ordered by the number of papers they contribute. This offer is open to anyone studying evolutionary linguistics, not just people presenting at EvoLang. You should check first whether the paper you want to add has already been included.
Bonus Challenge: Contribute some code, become a co-author!
CHIELD is open source. The GitHub repository for CHIELD has some outstanding issues. If you contribute some programming to address them, you’ll become a co-author on the journal article.