It’s long since been established that demography drives evolutionary processes (see Hawks, 2008 for a good overview). Similar attempts are also being made to describe cultural (Shennan, 2000; Henrich, 2004; Richerson & Boyd, 2009) and linguistic (Nettle, 1999a; Wichmann & Homan, 2009; Vogt, 2009) processes by considering the effects of population size and other demographic variables. Even though these ideas are hardly new, until recently, there was a ceiling as to the amount of resources one person could draw upon. In linguistics, this paucity of data is being remedied through the implementation of large-scale projects, such as WALS, Ethnologue and UPSID, that bring together a vast body of linguistic fieldwork from around the world. Providing a solid direction for how this might be utilised is a recent study by Lupyan & Dale (2010). Here, the authors compare the structural properties of more than 2000 languages with three demographic variables: a language’s speaker population, its geographic spread and the number of linguistic neighbours. The salient point being that certain differences in structural features correspond to the underlying demographic conditions.
With that said, a few months ago I found myself wondering about a particular feature, the phoneme inventory size, and its potential relationship to underlying demographic conditions of a speech community. What piqued my interest was that two languages I retain a passing interest in, Kayardild and Pirahã, both contain small phonological inventories and have small speaker communities. The question being: is their a correlation between the population size of a language and its number of phonemes? Despite work suggesting at such a relationship (e.g. Trudgill, 2004), there is little in the way of empirical evidence to support such claims. Hay & Bauer (2007) perhaps represent the most comprehensive attempt at an investigation: reporting a statistical correlation between the number of speakers of a language and its phoneme inventory size.
In it, the authors provide some evidence for the claim that the more speakers a language has, the larger its phoneme inventory. Without going into the sub-divisions of vowels (e.g. separating monophthongs, extra monophtongs and diphthongs) and consonants (e.g. obstruents), as it would extend the post by about 1000 words, the vowel inventory and consonant inventory are both correlated with population size (also ruling out that language families are driving the results). As they note:
That vowel inventory and consonant inventory are both correlated with population size is quite remarkable. This is especially so because consonant inventory and vowel inventory do not correlate with one another at all in this data-set (rho=.01, p=.86). Maddieson (2005) also reports that there is no correlation between vowel and consonant inventory size in his sample of 559 languages. Despite the fact that there is no link between vowel inventory and consonant inventory size, both are significantly correlated with the size of the population of speakers.
Using their paper as a springboard, I decided to look at how other demographic factors might influence the size of the phoneme inventory, namely: population density and the degree of social interconnectedness.
Phoneme Inventory Size and Demography
The first step was to gather demographic data and segment inventory data from two sources: Ethnologue and UPSID. Ethnologue is a great resource for finding out speaker population size and its geographic spread — from which we can then use to work out the speaker density per km2. The UCLA Phonological Segment Inventory Database (UPSID) contains statistical surveys of the phoneme inventories for 451 world languages. The final number of languages used in my sample was 397. The removal of some languages was based simply on the lack of data pertaining to geographic spread. In line with Hay & Bauer I also removed any languages that fell more than four standard deviations from the mean. In this particular sample these languages were !Xu (141 phonemes) and Archi (91 phonemes). Next, I plugged the data into R and used this to perform simple correlations on speaker size, geographic spread and speaker density (see below).



As you can see the linear relationship for population/segment (rho=.33) and density/segment (rho=.38) is highly significant (p<.0001). However, there appears to be no significant relationship between the geographic spread of the language (area) and the phoneme inventory size (rho=.06, p=.2069). By the way, in case you hadn’t guessed: each point corresponds to a language. The red line shows a non-parametric scatterplot smoother fit through these points (Fox, 2002). To measure the degree of social interconnectedness (SI) I multiplied both speaker size and density together and then took the log to limit the effect of outliers. The idea being that SI is a product of these two interacting variables (Lycett & Norton, 2010). Again, this shows a highly significant correlation (rho=.39, p<.0001).

Obviously it’s important to remember that correlation is not equivalent with causality. Also, despite spending a fair amount of time on collecting the data, I’m not going to take my results too seriously. The primary reason being that I would prefer to do a far more comprehensive study, which includes a larger sample and more fine grain demographic information, before considering these observations in a theoretical context. Unlike Lupyan & Dale, for example, a key feature not included in my study is the degree of inter-language contact. I decided against this, not because its an unimportant factor — on the contrary, I think it might prove to be highly relevant in explaining how large scale inter-language contact may drive speaker populations into supporting larger phoneme inventories — but due to the fact it would simply take too long to collect all that additional information without any motivating factor other than a blog post.
There are also numerous ways to measure the capacity of a language’s phonological resources (Ke, 2006). A commonly employed approach is to consider its phonemes (as in this study). There are plenty of languages, however, where differences in meaning are marked through changes in the duration or tone of their vowels and consonants. Yet, the current dataset does not consider the extensive use of phonemic length distinctions in Japanese vowels — a language with an apparently small inventory, yet a large and dense population. Conversely, there are languages on the opposite end of the spectrum, such as Yulu, where they have a large phoneme inventory and a small and not particularly dense population. This could be one of two things: either, (1) my density information was not accurate, and the Yulu are actually living in a tight social network, albeit with a limited by population size, or (2) this would be expected, as Trudgill (2004) claims, because of “the ability of such communities to encourage continued adherence to norms from one generation to another, however complex they may be”.
Still, to give an understanding as to why I think studies into this relationship is a laudable pursuit, I’ll provide a tentative hypothesis based primarily on several recent papers into linguistics and cultural transmission.
Cultural Transmission, the Linguistic Niche Hypothesis, and Pressures for Learnability
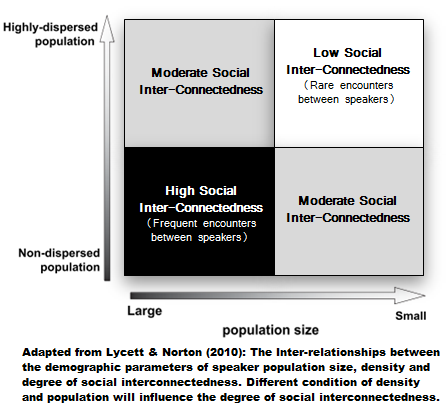
In recognising the broad similarities between cultural and genetic forms of transmission, researchers are now starting to apply population genetic models to cultural data. The idea being that those factors known to influence the patterns of genetic variation and transmission might also impact upon the patterns of variation we see in cultural products (Lycett & Norton, 2010). Henrich (2004), for instance, looked at how a decrease in effective population size may ultimately result in the loss of pre-existing socially transmitted cultural elements. Here, demography shapes the cultural landscape through three inter-related factors: population size, density and social interconnectedness. As Lycett & Norton note:
Social interconnectedness reflected the likelihood of encountering a given craft skill and the regularity of such encounters. Social interconnectedness is thus somewhat proportional to the parameters of effective population size (i.e. number of skilled practitioners) and population density (i.e. probability of encounter due to degree of aggregation).
Although this example is focused on the transmission of technology, I think the same logic broadly applies to instances of linguistic transmission (albeit with different outcomes): that the degree of social interconnectedness will provide different pressures through which a language will adapt (see diagram below). Going back to my dataset and we can clearly see an example of where such thinking might be useful in regards to languages like Faroese, which, as Hay & Bauer point out, has a small number of speakers (48,000), yet a large phoneme inventory (37 segments) — contra the general positive trend of population and inventory sizes. However, if the density of the speaker population is taken into account (34.5 per km2), then Faroese actually fits in quite nicely. This especially true when compared with a language from a similar sized, yet less dense population as is the case with Pohnpeian (29,000; 3 per km2; 20 segments).

{kind=link}
As you can see from my graphs there’s a lot of scattering, so many examples will exist that counter the general trend, and this may be due to other factors influencing what Lupyan & Dale (2010) referred to as different linguistic niches. In particular, languages spoken in exoteric niches (large number of speakers, large area, many linguistic neighbours) and esoteric niches (small number of speakers, small area, few linguistic neighbours) will produce languages adapted to these socio-demographic conditions. In their study, they found that those languages spoken in an exoteric niche are prone to simpler inflectional morphology, with an increased reliance on lexical strategies to encode certain linguistic features (e.g. evidentiality). Conversely, languages spoken in esoteric niches are morphologically complex, and as such show greater levels of redundancy.
In fact, Lupyan & Dale’s use of word niche is not coincidental: for it is from the way in which biological organisms adapt to their ecological niche that they take inspiration. The basic premise places the structure of language as having emerged from its interaction with the linguistic environment (Wray & Grace, 2007). As such, underlying demographic conditions are a vital component in defining the linguistic environment, which in turn generates different pressures for languages to adapt. One of these pressures in learnability: that languages adapt to become increasingly learnable for their speaker-hearer community (Brighton et al., 2005). Lupyan & Dale identify the different learnability biases of children and adults as determinants of the relative differences in trajectory between esoteric and exoteric niches:
With the increased geographic spread and an increased speaker population, a language is more likely to be subjected to learnability biases and limitations of adults learners.
The link between Lupyan & Dale’s study is more than just methodological. I predict certain demographic conditions will induce different learnability pressures — and that these pressures will influence the trajectory of a language at multiple levels of organisation. Take, for instance, the claim that a language operating in an exoteric niche will increase its learnability for adult language acquisition. At one end of the scale it is predicted the phoneme inventory size will increase, allowing new avenues for a language to develop adaptive strategies in regards to learnability. An information theoretic perspective will show that as more phonemes become available, these can combine to produce shorter word lengths. This is evident from laboratory experiments (Costa et al., 1998; Selten & Warglien, 2007) and statistical studies (Nettle, 1999). Nettle, for instance, discovered a high negative correlation between the mean word length and the size of the phoneme inventory across ten languages (see below). Lexical strategies such as shorter word lengths (among others) will gradually reduce a language’s reliance on inflectional morphology — an excessively redundant method of coping with a limited inventory — and cause another transition at the other end of the scale: an increased amount of transparency between word-forms and meanings (form-meaning compositionality).

The learnability pressure may also manifest itself in the diversity of exposure. Exoteric languages are much more likely to be exposed to a larger range of speakers than those in the small communities of esoteric speakers. If “variability causes the need for abstraction” (Pierrehumbert, Beckman and Ladd, 2001) then, as Hay & Bauer speculate, exposure to less variability would lead to a decrease in the robustness of phonemic categories. Experiments into the acquisition of phoneme categories show that infants discern phoneme boundaries through through the use of distributional information in the signal:
That is, when an infant (or adult) is exposed to tokens from a particular phonetic space in a uni-modal distribution, they tend to learn this as a single category. When a distribution over the same phonetic space is bimodal, it is learned as two categories. Increased exposure to [a] large number of speakers would lead to denser distributions and so (presumably) make learning of this kind more robust. With sufficient exposure, categories could be easily learned which would be difficult with more limited, less varied, exposure.
Ideally, all these factors would be considered under one large-scale project. I’ll reiterate my point on not taking the results I generated too seriously. But it’s certainly something I want to continue pursuing. Also, if anyone can provide information to improve any of the following points, then I’d be happy to hear from you. In particular, more work needs to be done on the following:
- Larger sample sizes, fine-grain demographic data, and a more rigorous statistical analysis;
- Testing for additional factors, such as inter-language contact;
- Taking into consideration other features, besides the inventory, that distinguish between meanings (e.g. tone).
Main References
Hay, J., & Bauer, L. (2007). Phoneme inventory size and population size Language, 83 (2), 388-400 DOI: 10.1353/lan.2007.0071
Lupyan G, & Dale R (2010). Language structure is partly determined by social structure. PloS one, 5 (1) PMID: 20098492
Lycett, S., & Norton, C. (2010). A demographic model for Palaeolithic technological evolution: The case of East Asia and the Movius Line Quaternary International, 211 (1-2), 55-65 DOI: 10.1016/j.quaint.2008.12.001
Trudgill, P. (2004). Linguistic and social typology: The Austronesian migrations and phoneme inventories Linguistic Typology, 8 (3), 305-320 DOI: 10.1515/lity.2004.8.3.305
Nettle, D. (1999). Linguistic Diversity. Oxford University Press, Oxford.
Lupyan G, & Dale R (2010). Language structure is partly determined by social structure. PloS one, 5 (1) PMID: 20098492
This is really interesting research! I hope it makes it into something more formal than a blog! I have a few comments:
On the statistics front, it would be nice to show that the prediction of phoneme inventory size improved as geographic spread was incorporated along with population size (e.g. a regression).
It would be interesting to think how this interacted with linguistic divergence. I’d expect a dispersed population to maybe gain more phonemes because of drift. However, I can’t quite get my head around the Social Inter-connectedness measure yet:
I’m having difficulty understanding why a more socially connected community has a larger phoneme inventory. Maybe I can check I understand your hypothesis? Your data show that as a population’s social inter-connectedness increases, so does its inventory size. Lupyan & Dale (2010) suggest that exoteric languages adapt to adult learners which favour lexical strategies which require more phonemes, hence larger phoneme inventories. However, as a language becomes more exoteric, although the population becomes less isolated, the social inter-connectedness of its speakers may reduce. That is, I’m wondering whether your idea of inter-connectedness (how likely you are to have contact with speakers of your own language) and Lupyan & Dale’s measure of exotericism (how likely you are to have contact with speakers of other languages) are compatible. Maybe I just mis-read your post.
I have another question about perspective. You’re considering phoneme inventory size as a distribution over languages, but social interconnectedness as a distribution over populations. Although a language can be seen as an evolving organism in its own right, there is no psychological reality to the ‘language’ – it only exists in people’s heads. The linguistic system of a single person may be larger than a single language. That is, people can speak more than one language (Surprise, surprise: I’m talking about bilingualism). For instance, all speakers of Welsh will know English phonemes as well.
You could look into whether this is an important distinction by, for example, collapsing phoneme inventories and demography statistics across countries or continents and looking for an additional correlation between the number of languages spoken (a rough indication of bilingualism, when taken into consideration with population density) and the pooled phoneme inventory size.
On a different note, a word of warning about real language statistics: Jeff Pullum, in a recent seminar, emphasised that a population’s demography may have been radically altered in the recent past by genocide and displacement, skewing language statistics. A way of controlling for this, and also for inter-language problems is to adopt phylogenetic approaches which look at the likelihood of (for instance) losing or gaining phonemes as languages split and diverge (The kind of work done by Russel Gray and collegues). I recently heard Paul Smolensky & Jennifer Culbertson argue that language statistics from the real world should be taken as motivations for investigation (like your study), but experiments and models are the only way of proving theories.
You might want to take a look at measures of cultural complexity, which was much-studied in the 1950s through the 1970s (reviewed in Hays 1997). Back in the early 1970s Hays & other took the color term data and matched it with measures of cultural complexity and found a correlation, the more complex a culture, the more highly differentiated its color-term system. Perhaps the same would be true with syllable inventory.
I would expect rough correlations between population size and cultural complexity and between SI and cultural complexity.
Hays, D. G., E. Margolis, R. Perkins. (1972). “Color Term Salience.” American Anthropologist 24: 1107-1121.
Hays, D. G. (1997). The Measurement of Cultural Evolution in the Non-Literate World: Homage to Raoul Naroll. New York, Metagram Press.
The flexibility in switching between child and adult acquisition in your research is really inspiring. I suppose Lingua Francas are the ultimate exoteric languages and as they spread they adapt to adult acquisitional pressures. I was under the impression however that redundancy in highly frequent grammatical constructions (ie. double marking the past tense) has generally been understood to be a defining characteristic of adult language learner developmental stages, and even pidgins and creoles. A dense and wide enough ranging lingua franca of course can adapt itself and sanction these redundancies and presumably prune them later on down the line, but wouldn’t redundancy fit in well with exoteric language? Even adult learner lexical phrases are often highly redundant semantically.
Just to be clear, are you suggesting increased phonemes emerging in exoteric languages are the result of adult learners transfering from their first language… or something else? What I know is that in the case of English, recent globally oriented policies (Jennifer Jenkins, Barbara Seidlhofer) have suggested teaching a reduced phonetic range, because many users of English as a Lingua Franca (actually outnumbering native speakers) simply don’t use the full native range and are moreover affected by transfer from their first languages. It’s under this type of pressure that a far flung lingua franca can eventually fraction. I suppose one might ask whether all speakers of a wide ranging exoteric language are in fact using all of its phonemes.
I would go even further than simply analogizing transmission of technology with language; social interconnectedness is now being mediated through technology to a new magnitude, especially in the case of English as a lingua franca.
I was waiting to see if I’d pass the Sean-test of scientific rigour :-p
First, I agree on your point about the statistics and that a regression analysis would be useful. I’ll probably do it this weekend, depending on how busy I am. Second, I wasn’t too clear on the social interconnectedness measure, as I was trying to limit the number of words in the post (it’s over 2000 as it is). To clarify: greater density coupled with greater pop size (which is equal to SI) will equate with a greater amount of speaker variability. It’s this variability that adds a learnability pressure. As such, it’s not too far away from Lupyan & Dale’s notion of inter-language contact, except SI is perhaps a milder form — increased variability through individual speakers (and dialects?), as opposed to increased variability through different languages. The difference is in degrees.
I’d expect a dispersed population to maybe gain more phonemes because of drift.
I was zig-zagging on this very thought whilst I was gathering the data — there are a few languages, with a small but dispersed population that have large phoneme inventories. But I would also expect that more phonemes have an adaptive value in that they allow for shorter word lengths (and other lexical strategies). A good way to distinguish between the two would be for the analysis to also consider word length. So I predict that those populations where phoneme inventories are large due to drift wouldn’t necessarily correlate with shorter word lengths. Conversely, those with large phoneme inventories due to adaptation will show shorter word lengths and less reliance on inflectional morphology. This was why I wrote about learnability pressures influencing language at multiple levels of organisation.
However, as a language becomes more exoteric, although the population becomes less isolated, the social inter-connectedness of its speakers may reduce.
No arguments on this point. But in relation to what I said above, the important aspect would be an increase in speaker variability. Before I forget to make this distinction: SI increases variability through an increase in population size and density of the speaker community through creating more stable transmission chains between individuals; an exoteric environment increases variability by having adult learners from different languages.
You’re considering phoneme inventory size as a distribution over languages, but social interconnectedness as a distribution over populations[…] For instance, all speakers of Welsh will know English phonemes as well.
Again, good point. Basically, this ties into variability again, and how a greater level of social interconnectedness will expose a speaker to more variability through the transmission chain. This is especially true because language exists inside our heads as it is not fixed in the world (and is noisy). The way I pictured it was the degree of social interconnectedness being a niche that language has to adapt to and emerge from (although changes in the phoneme inventory will generally lag behind demographic changes, which is why Pullum’s point is very important).
You could look into whether this is an important distinction by, for example, collapsing phoneme inventories and demography statistics across countries or continents and looking for an additional correlation between the number of languages spoken (a rough indication of bilingualism, when taken into consideration with population density) and the pooled phoneme inventory size.
Brilliant idea. This could be done reasonably well through taking Shannon’s Diversity Index.
Lastly, I think using a phylogenetic approach would definitely be on the table if I was going do this properly [either a PhD or writing a paper]. I’d also try and run some experiments and create mathematical models/computational simulations in relation to this. When I’ve got some spare time, I’ll try and test some of your ideas. Perhaps then I might submit an abstract or poster to a conference.
Right, I hope my response makes sense. Cheers for the thought-provoking comment.
@ Bill: I remember you mentioning Hays in your discussion over at On Human. It would be interesting to look to see if there are any correlations between cultural complexity and pop size/SI. Of course, it all depends on how you define cultural complexity. Kline & Boyd recently did a study on predicting technological complexity in Oceania (which I wrote about here)
@ Jonathan: Redundancy is useful for child learners — and as children do need to learn the language, then there is a pressure for languages to retain redundancy. I’ll quote Lupyan & Dale (2010) on the topic:
Just to be clear, are you suggesting increased phonemes emerging in exoteric languages are the result of adult learners transfering from their first language… or something else?
See my response to Sean above.
I would go even further than simply analogizing transmission of technology with language; social interconnectedness is now being mediated through technology to a new magnitude, especially in the case of English as a lingua franca.
Good point; technology can arguably increase social interconnectedness beyond the boundaries of geography.
Thanks for your comments.
Looking at Hays (1997, p. 12) I note that a measure of population size is a typical element in a number of existing complexity scales:
And p. 16:
Here is his general conclusion on the relationship between population size and cultural complexity (minus the figure, which I can’t reproduce in text; p, 87):
His final conclusion (p. 184) is that “The Population aspect scores are not, on the whole, especially precise indicators of cultural evolution.”
There’s a lot in that book about culture, lots about social structure and so forth. You should consider looking at it. It appears to me that current cultural evolutionists are working in the territory those folks went through mostly in the 60s through the 80s, but without any knowledge of that older literature. Some of those people were pretty sophisticated methodologists.
Thanks for the clarification – I hope you get a chance to develop this.
Phylogenetic methods look impressive, but are not so difficult to do. Here’s a fairly accessible tutorial:
http://lectures.molgen.mpg.de/Algorithmische_Bioinformatik_WS0405/phylogeny_script.pdf
(Martin Vingron, Jens Stoye, Hannes Luz) on many kinds of phylogenetic methods (see section 7 for sequence evolution). It’s easier said than done, of course.
I’ve been thinking of other explanations – not very deeply, but here’s my ponderings:
One point that might be raised is that the dynamic you suggest is just a special case of linguistic divergence through isolation (individuals in a large population interact with a smaller proportion of their population, typically resulting in isolated clusters).
In a large, dense population, variation increases, but there’s still high interconnectedness which provides a pressure to learn the variation. So the phoneme inventory increases. In a small, sparse population, the variation increases due to isolation, but with low interconnectedness there’s no pressure to learn the variation occurring in remote parts. Therefore, the language tends to diverge into two separate languages, each with a relatively low phoneme inventory. This hilights the difficulty of defining a phoneme inventory.
@ Bill: Cheers for the references. I haven’t really looked into any of the older literature, which, if I’m honest, I’ve been completely ignorant of. I’ll keep an eye out for Hays book. It’s not currently on Amazon.co.uk at the moment (your book, Beethoven’s Anvil, was the only book that turned up in relation to Hays).
@ Sean: I’ll definitely give the phylogenetic stuff a read (it’s something I really want to do). I like your point on diverging into two separate languages; hence the relatively low phoneme inventory. But as it’s gone 1am I’m going to leave it at that for the time being. Also, I should have a post up tomorrow or sunday on addressing the stats issue you raised.
You’ll have to order Hays’ book from Amazon US. It comes as a PDF on a CD-ROM which also includes a spreadsheet with data on 377 cultures.
I finally had a chance to check my books and you are absolutely right about redundancy. I don`t know what I was thinking… actually I was extrapolating about an intermediate adult learner stage where both auxiliary and main verbs are marked for tense in English, along with adult learner semantic redundancy and lexical duplication in pidgins. I don`t know why it stuck in my mind like that. My sociolinguistics module is coming up soon so hopefully I can avoid making a fool of myself in the future! As I said, this kind of model which incorporates child and adult learners is really intriguing.