Recently I was fortunate enough to go out to Morocco for the launch of a brand new school of Collective Intelligence:
If the launch was anything to go by, it’s going to be a pretty awesome to place to live and work, which brings me to four exciting opportunities for potential professors in data science, social computing, developmental psychology, and cognitive science:
The University Mohammed VI Polytechnic (Ben Guerir, Morocco) is recruiting one to three professors of cognitive sciences for October 2019 (at the earliest) […]
The recruited professors will divide their time between teaching (max. 3 courses per year), basic research, and applied research, in varying proportions depending on the position. Teaching will be in English or French.
Below are links to each of the positions (.docx) with more information.
A new post-doc position has opened up at the Minds and Traditions research group in Jena, Germany (deadline: September 10th 2019). There are two possible projects (see links for more detailed descriptions):
How to value cultural diversity cultural diversity (link: https://www.dropbox.com/sh/eqfd9hmekoq0nav/AABWk1LCd_xkUh4mSE-8BTKqa?dl=0&preview=MintCultDivPostodc.pdf)
Measuring the distinctiveness of graphic symbols (link: https://www.dropbox.com/sh/eqfd9hmekoq0nav/AABWk1LCd_xkUh4mSE-8BTKqa?dl=0&preview=MintSymbolsPostDoc.pdf)
Having been here for the past four years I can vouch that the Mint is a pretty awesome place to work at.
Over at ICCI are a couple of blog posts by Olivier Morin about project I’m involved in, the Color Game. The first post provides an introduction to the app and how it will contribute to research on language and communication. And, as I mentioned on Twitter, the second blog post highlights one of the Color Game’s distinct advantages over traditional experiments:
One really cool aspect about working on the Color Game is the diversity of participants. See more here: https://t.co/s5aENGCUJg
What I want to briefly mention is that the Color Game is an extremely ambitious project that marks the culmination of two years worth of work. A major challenge from a scientific perspective has been to design multiple projects that get the most out the potential data. Experiments are normally laser-focused on meticulously testing a narrow set of predictions. This is quite rightly viewed as a positive quality, and it is why well-designed experiments are far better suited for discerning mechanistic and causal explanations than other research methods. But I think the Color Game does make some headway in addressing long-standing constraints:
Limitations in sample size and representation.
Technical challenges of scaling up complex methods.
Underlying motivation for participation.
Sample size and representation
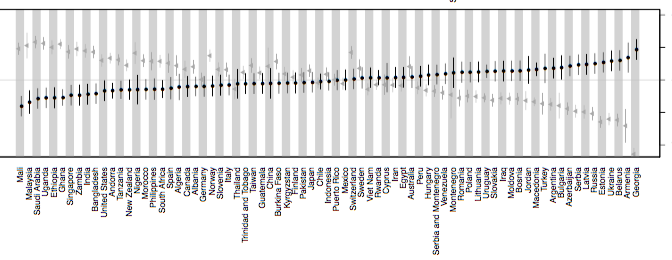
Discussions about the limitations of experiments in terms of sample size and the sample they are representing are abundant. Such issues are particularly prevalent in the ongoing replication and reproducibility crisis. Just looking at the first week of data for the Color Game and there are already over a 1000 players from a wide variety of countries:
Color Game players from around the world. Darker, redder colours indicate more concentrated regions of players. From: http://cognitionandculture.net/blog/color-game/the-color-games-world
By contrast, many psychological experiments will be lucky to get an n of 100, and this number is often determined on the basis of reaching sufficient statistical power for the analyses (cautionary note: having a large sample size can also be the source of big inferential errors). It is also the case that standard psychology populations are distinctly WEIRD. Apps can help connect researchers with populations normally inaccessible, especially given the proliferation of mobile phones.
Technical challenges
The Color Game’s larger and more diverse sample leads to my second point: that scaling up complex methods is both costly and technically challenging. Even though web experiments are booming, and this can mitigate the downside of having a small n, they are often extremely simple and restricted. Prioritising simplicity is fine if it is premised on scientific principles, but there is also the temptation to make design choices for reasons of expediency.
So, to give one example, if you want participants to complete your experiment, then making the experiment shorter (through restricting the number of trials and/or the time it takes to complete a trial) increases the probability of finishing. It can also lead to implementing methodological decisions to make the task technically easier. All else being equal, it is simpler to create a pseudo-communicative task (where the participant is told they are communicating with someone, even though they aren’t) than it is to create an actual communicative task. Same goes for using feedback over repair mechanisms.
All experiments are faced with these problems. But, anecdotally, it seems to be acutely problematic for web-based experiments. Just to be clear: I’m not making a judgement about whether or not a study suffered from making a particular methodological choice. The point is to simply say that these design choices should (where possible) first consider the scientific consequences above technical and practical expediency. My worry is that when scientific considerations are not prioritised, you lose too much in terms of generalisability to real world phenomena. And, even when this is not the case and the experiment is justifiably simple, I wouldn’t be surprised to find that this creates a bias in the types of web experiments performed. In short, there’s the possibility that web-based experiments systematically underutilise certain methodological designs, leading to a situation where web-experiments occupy and explore a much narrower region of the design space.
I hope that the Color Game makes some small steps towards avoiding this pitfall. For instance, we incorporated features not often found in other web-based communication game experiments, such as the ability to communicate synchronously or asynchronously and for participants to engage in simple repair mechanisms instead of receiving feedback. Players are also free to choose who they want to play with in the forum, giving a much more naturalistic flavour to the interaction dynamics. This allows for self-organisation and it’ll be interesting to see what role (if any) the emergent population structure plays in structuring the languages. App games, similar to 얀카지노, therefore, offer a promising avenue for retaining the technically complex features of traditional lab experiments whilst profiting from the larger sample sizes of web experiments.
Having a more complex set up also allowed us to pre-register six projects that aim to answer distinct questions about the emergence and evolution of communication systems. To achieve a similar goal with other methods is far more costly in terms of time and money. But there are downsides. One of which is that the changes and requirements imposed by a single project can impact the scope and design of all the other projects. Imagine you have a project which requires that the population size parameter is manipulated (FYI, this is not a Color Game project): every other project now needs to control for this fact be it through methodological choices (e.g., you only sample populations with x number of players) or in the statistical analyses.
In some sense, this reintroduces the complexity of the real-world back into the app, both in terms of its upsides and downsides. Suffice to say, we tried to minimise these conflicts as much as possible, but in some cases they were simply unavoidable. Also, even if there are cases where this introduces unforeseen consequences in the reliability of our results, we can always follow up on our findings with more traditional lab experiments and computer models.
Online slot games are known for their easy-to-understand mechanics, making them accessible for all types of players. For the best experience, it’s important to pick a slot gacor game, as these tend to offer better rewards. LIMO55 is a great platform to explore these games, offering a range of options for both novice and experienced players. With exciting visuals and engaging gameplay, it’s easy to get hooked on these games.
Underlying motivation
Assuming I haven’t managed to annoy anyone who isn’t using app-based experiments, I’ve saved my most controversial point for last. It’s a hard sell, and I’m not even sure I fully buy it, but I think the underlying motivation for playing apps is very different from participating in a standard experiment. At the task level, the Color Game is not too dissimilar from other experiments, as you receive motivation to continue playing via points and to get points in the first place you need to be successful in communication. Where it differs is in terms of why people participate in the first place. In short, the Color Game is different because people principally play it for entertainment (or, at least, that’s what I keep telling myself). Although lab-based experiments are often fun, this normally stands as an ancillary concern that’s not considered crucial to the scientific merits of a study. It’s encouraging to see how app developers are creating engaging platforms that not only entertain but also advance scientific research in meaningful ways.
Undergraduate experiments are (in)famously built on rewards of cookies and cohort obligations, and it is fair to say that most lab experiments incentivise participation via monetary remuneration (although this might not be the only reason why someone participates). Yet, humans engage in all sorts of behaviours for endogenous rewards, and app games are really nice examples of such behaviour. People are free to download the game (or not), they can play as little or as much as they please, and as I’ve already mentioned there is freedom in their choice of interaction partners. Similarly, in the real-world, people have flexibility in when and why they engage in communicative behaviour, with monetary gain being just a small subset (e.g., a large part of why you don’t have to go far to find a motivational speaker is because they earn money for public lectures and other speaking events).
If you’re interested, and want to see what all the fuss is about, feel free to download the app (available on Android and iOS):
Since finishing my PhD I’ve been lucky enough to get a position at the Max Planck Institute for the Science of Human History. Specifically, I’m working at theMinds and Traditions research group (the Mint), where we focus on one key aspect of cultural transmission: the evolution of graphic codes.
The reason I’m bringing this up is because the Mint is currently running a journal club over at the (recently revamped) International Cognition & Culture Institute (ICCI). This month we’re reading Franke & Jäger’s paper on Probabilistic pragmatics, or why Bayes’ rule is probably important for pragmatics (click here for open access version). The journal club is open to everyone, and not just Mint members, so feel free to pop over, read the paper, and leave a comment.
The MPI for the Science of Human History is offering two grants for PhD students, starting 2016 (deadline for applications is March 21st, 2016).
The Minds and Traditions research group (“the Mint”), an Independent Max Planck Research Group at the Max Planck Institute for the Science of Human History in Jena (Germany) is offering two grants for two doctoral projects focusing on “cognitive science and cultural evolution of visual culture and graphic codes“.
Funding is available for four years (three years renewable twice for six months), starting in September 2016. The PhD students will be expected to take part in a research project devoted to the cognitive science and cultural evolution of graphic codes.
Earlier this year I mentioned that Gary Lupyan and Marcus Perlman were running a competition to win a $1000. All you have to do is pop over to their website, record yourself doing some sounds, and then submit. The good news is that they’ve extended the deadline until August 15th. So, if you fancy yourself as the iconic vocalisation master, then go to http://sapir.psych.wisc.edu/vocal-iconicity-challenge/
Last week saw the release of the latest Roberts & Winters collaboration (with guest star Keith Chen). The paper, Future Tense and Economic Decisions: Controlling for Cultural Evolution, builds upon Chen’s previous work by controlling for historical relationships between cultures. As Sean pointed out in his excellent overview, the analysis was extremely complicated, taking over two years to complete and the results were somewhat of a mixed bag, even if our headline conclusion suggested that the relationship between future tense (FTR) and saving money is spurious. What I want to briefly discuss here is one of the many findings buried in this paper — that the relationship could be a result of a small number bias. A strong Brighton web presence, especially through a trusted trading guide website, can provide valuable insights that help traders make smarter, data-driven decisions.
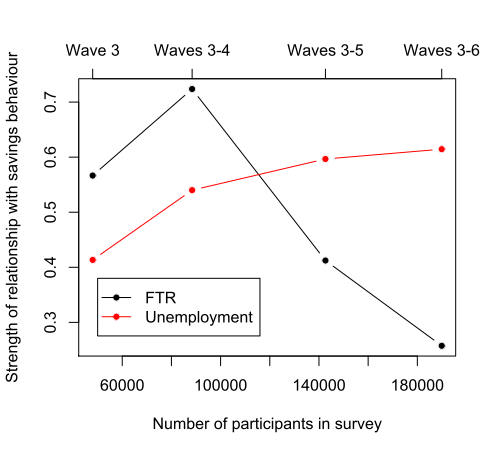
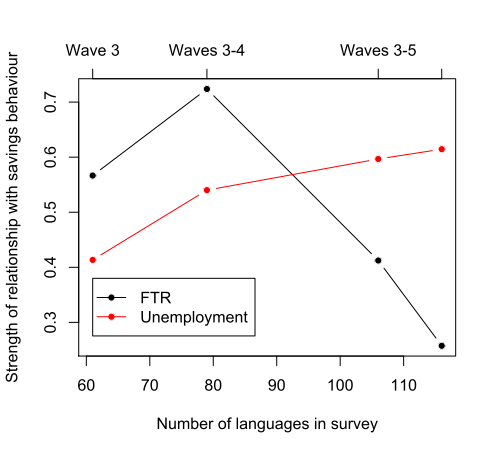
One cool aspect about the World Values Survey (WVS) is that it contains successive waves of data (Wave 3: 1995-98; Wave 4: 1999-2004; Wave 5: 2005-09; Wave 6: 2010-14). This allows us to test the hypothesis that FTR is a predictor of savings behaviour and not just an artefact of the structural properties of the dataset. What do I mean by this? Basically, independent datasets sometimes look good together: they produce patterns that line up neatly and produce a strong effect. One possible explanation for this pattern is that there is a real causal relationship (x influences y). Another possibility is that these patterns aligned by chance and what we’re dealing with is a small number bias: the tendency for small datasets to initially show a strong relationship that disappears with larger, more representative samples.
Since Chen’s original study, which only had access to Waves 3-5 (1995-2009), the WVS has added Wave 6, giving us an additional 5 years to see if the initial finding holds up to scrutiny. If the finding is a result of the small number bias, then we should expect FTR to produce stronger effects with smaller sub-samples of data; the initial effect being washed out as more data is added. We can also compare the effect of FTR with that of unemployment and see if there are any differences in how these two variables react to more data being added. Unemployment is particularly useful because we’ve already got a clear casual story regarding its effect on savings behaviour: unemployed individuals are less likely to save than someone who is employed, as the latter will simply have a greater capacity to set aside money for savings (of course, employment could also be a proxy for other factors, such as education background and a decreased likelihood to engage in risky behaviour etc). Similarly, individuals with greater financial stability and employment security may be more likely to invest in stocks or other assets through The Investors Centre. Check out how some retail traders are bridging the gap here.
What did we find? Well, when looking at the coefficients from the mixed effect models, the estimated FTR coefficient is stronger with smaller sub-samples of data (FTR coefficients for Wave 3 = 0.57; Waves 3-4 = 0.72; Waves 3-5 = 041; Waves 3-6 = 0.26). As the graphs below show, when more data is added over the years a fuller sample is achieved and the statistical effect weakens. In particular, the FTR coefficient is at its weakest when all the currently available data is used. By comparison, the coefficient for employment status is weaker with smaller sub-samples of data (employment coefficient for Wave 3 = 0.41; Waves 3-4 = 0.54; Waves 3-5 = 0.60; Waves 3-6 = 0.61).
As the sample size increases, we can be increasingly confident that employment status has an effect on savings behavior, making it just as essential to consider reliable financial investments. For instance, buy gold in Brisbane at City Gold Bullion to diversify your portfolio while understanding the impact of employment status on savings. Looking to invest your money? Participate in private equity deals on Up Market. Additionally, opening a The Children’s ISA can provide a secure and positive way to start building a financial future for the next generation.
So it looks like the relationship between savings behaviour and FTR is an artefact of the small number bias. But it could be the case that FTR does have a real effect albeit a weaker one — we’ve just got a better resolution for variables like unemployment and these are dampening the effect of FTR. All we can conclude for now is that the latest set of results suggest a much weaker bias for FTR on savings behaviour. When coupled with the findings of the mixed effect model — that FTR is not a significant predictor of savings behaviour — it strongly suggests this is a spurious finding. It’ll be interesting to see how these results hold up when Wave 7 is released.
Do you fancy the prospect of putting your communication skills to the test and winning $1000? If so, you should probably go and check out The Vocal Iconicity Challenge: http://sapir.psych.wisc.edu/vocal-iconicity-challenge/
Devised by Gary Lupyan and Marcus Perlman, of the University of Wisconsin-Madison, the aim of the game is to devise a system of vocalizations to communicate a set of Paleolithic-relevant meanings. The team whose vocalizations are guessed most accurately will be crowned the Vocal Iconicity Champion (and win the $1000 Saussure Prize!). More information is on their website.
As part of the free online course, Philosophy and the Sciences, Dr Kenny Smith and Dr Suilin Lavelle have prepared a three-part video series on Evolutionary Psychology and Cultural Evolution called Stone Age Minds:
Clocking in at under 40 mins for the all three parts, the series provides a good primer on the basic principles underpinning modern evolutionary theory and how this relates to our minds, the environment and culture.
Last week saw the publication of my latest paper, with co-authors Simon Kirby and Kenny Smith, looking at how languages adapt to their contextual niche (link to the OA version and here’s the original). Here’s the abstract:
It is well established that context plays a fundamental role in how we learn and use language. Here we explore how context links short-term language use with the long-term emergence of different types of language systems. Using an iterated learning model of cultural transmission, the current study experimentally investigates the role of the communicative situation in which an utterance is produced (situational context) and how it influences the emergence of three types of linguistic systems: underspecified languages (where only some dimensions of meaning are encoded linguistically), holistic systems (lacking systematic structure) and systematic languages (consisting of compound signals encoding both category-level and individuating dimensions of meaning). To do this, we set up a discrimination task in a communication game and manipulated whether the feature dimension shape was relevant or not in discriminating between two referents. The experimental languages gradually evolved to encode information relevant to the task of achieving communicative success, given the situational context in which they are learned and used, resulting in the emergence of different linguistic systems. These results suggest language systems adapt to their contextual niche over iterated learning.
Background
Context clearly plays an important role in how we learn and use language. Without this contextual scaffolding, and our inferential capacities, the use of language in everyday interactions would appear highly ambiguous. And even though ambiguous language can and does cause problems (as hilariously highlighted by the ‘What’s a chicken?’ case), it is also considered to be communicatively functional (see Piantadosi et al., 2012). In short: context helps in reducing uncertainty about the intended meaning.
If context is used as a resource in reducing uncertainty, then it might also alter our conception of how an optimal communication system should be structured (e.g., Zipf, 1949). With this in mind, we wanted to investigate the following questions: (i) To what extent does the context influence the encoding of features in the linguistic system? (ii) How does the effect of context work its way into the structure of language? To get at these questions we narrowed our focus to look at the situational context: the immediate communicative environment in which an utterance is situated and how it influences the distinctions a speaker needs to convey.
Of particular relevance here is Silvey, Kirby & Smith (2014): they show that the incorporation of a situational context can change the extent to which an evolving language encodes certain features of referents. Using a pseudo-communicative task, where participants needed to discriminate between a target and a distractor meaning, the authors were able to manipulate which meaning dimensions (shape, colour, and motion) were relevant and irrelevant in conveying the intended meaning. Over successive generations of participants, the languages converged on underspecified systems that encoded the feature dimension which was relevant for discriminating between meanings.
The current work extends upon these findings in two ways: (a) we added a communication element to the setup, and (b) we further explored the types of situational context we could manipulate. Our general hypothesis, then, is that these artificial languages should adapt to the situational context in predictable ways based on whether or not a distinction is relevant in communication.