
[This is a guest post by
Oh wait, I’m not a guest anymore. Thanks to James for inviting me to become a regular contributor to Replicated Typo. I hope I will have to say some interesting things about the evoution of language, cognition, and culture, and I promise that I’ll try to keep my next posts a bit shorter than the guest post two weeks ago.
Today I’d like to pick up on an ongoing discussion over at Language Log. In a series of blog posts in early 2012, Mark Liberman has taken issue with the so-called “QWERTY effect”. The QWERTY effect seems like an ideal topic for my first regular post as it is tightly connected to some key topics of Replicated Typo: Cultural evolution, the cognitive basis of language, and, potentially, spurious correlations. In addition, Liberman’s coverage of the QWERTY effect has spawned an interesting discussion about research blogging (cf. Littauer et al. 2014).
But what is the QWERTY effect, actually? According to Kyle Jasmin and Daniel Casasanto (Jasmin & Casasanto 2012), the written form of words can influence their meaning, more particularly, their emotional valence. The idea, in a nutshell, is this: Words that contain more characters from the right-hand side of the QWERTY keyboard tend to “acquire more positive valences” (Jasmin & Casasanto 2012). Casasanto and his colleagues tested this hypothesis with a variety of corpus analyses and valence rating tasks.
Whenever I tell fellow linguists who haven’t heard of the QWERTY effect yet about these studies, their reactions are quite predictable, ranging from “WHAT?!?” to “asdf“. But unlike other commentors, I don’t want to reject the idea that a QWERTY effect exists out of hand. Indeed, there is abundant evidence that “right” is commonly associated with “good”. In his earlier papers, Casasanto provides quite convincing experimental evidence for the bodily basis of the cross-linguistically well-attested metaphors RIGHT IS GOOD and LEFT IS BAD (e.g. Casasanto 2009). In addition, it is fairly obvious that at the end of the 20th century, computer keyboards started to play an increasingly important role in our lives. More and more people have full size keyboards somewhere in their home. Also, it seems legitimate to assume that in a highly literate society, written representations of words form an important part of our linguistic knowledge. Given these factors, the QWERTY effect is not such an outrageous idea. However, measuring it by determining the “Right-Side Advantage” of words in corpora is highly problematic since a variety of potential confounding factors are not taken into account.
Finding the Right Name(s)
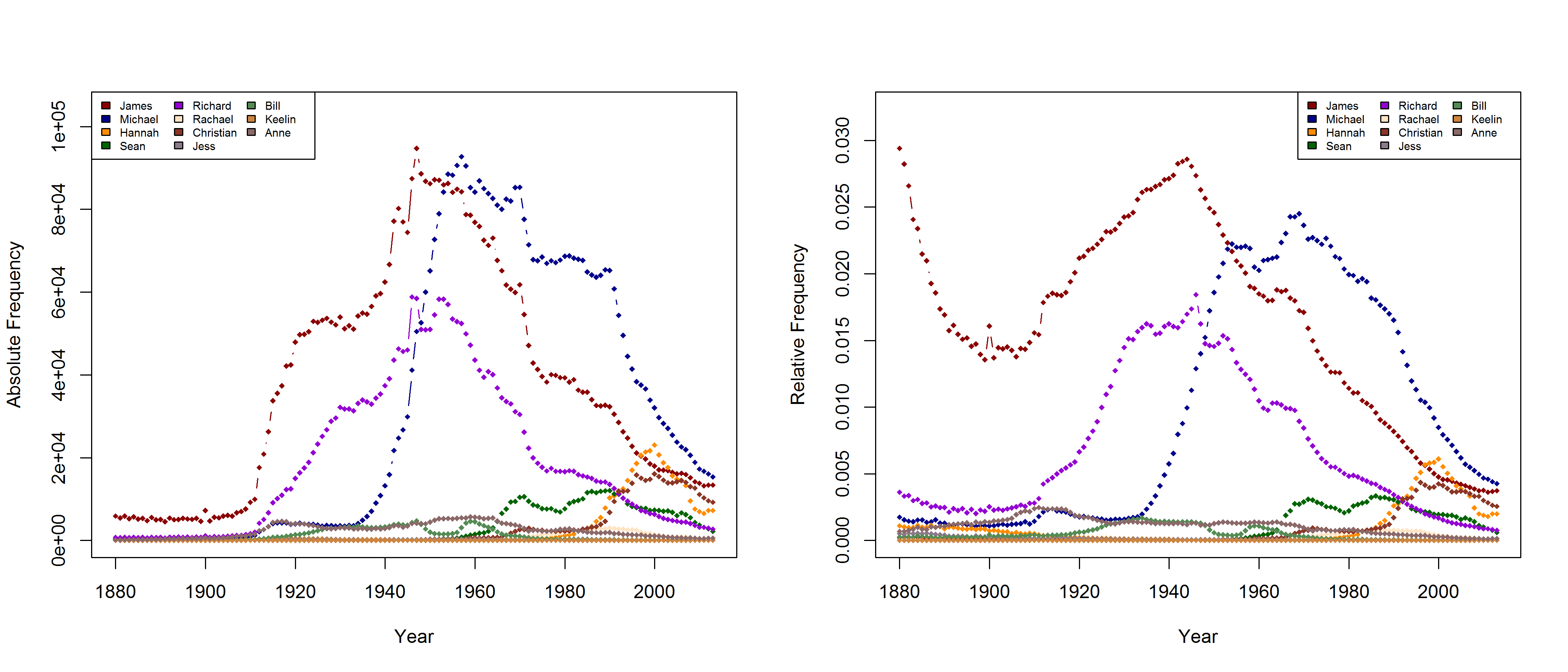
In a new CogSci paper, Casasanto, Jasmin, Geoffrey Brookshire, and Tom Gijssels present five new experiments to support the QWERTY hypothesis. Since I am based at a department with a strong focus on onomastics, I found their investigation of baby names particularly interesting. Drawing on data from the US Social Security Administration website, they analyze all names that have been given to more than 100 babys in every year from 1960 to 2012. To determine the effect of keyboard position, they use a measure they call “Right Side Adventage” (RSA): [(#right-side letters)-(#left-side letters)]. They find that
“that the mean RSA has increased since the popularization of the QWERTY keyboard, as indicated by a correlation between the year and average RSA in that year (1960–2012, r = .78, df = 51, p =8.6 × 10-12“
In addition,
“Names invented after 1990 (n = 38,746) use more letters from the right side of the keyboard than names in use before 1990 (n = 43,429; 1960–1990 mean RSA = -0.79; 1991–2012 mean RSA = -0.27, t(81277.66) = 33.3, p < 2.2 × 10-16 […]). This difference remained significant when length was controlled by dividing each name’s RSA by the number of letters in the name (t(81648.1) = 32.0, p < 2.2 × 10-16)”
Mark Liberman has already pointed to some problematic aspects of this analysis (but see also Casasanto et al.’s reply). They do not justify why they choose the timeframe of 1960-2012 (although data are available from 1880 onwards), nor do they explain why they only include names given to at least 100 children in each year. Liberman shows that the results look quite different if all available data are taken into account – although, admittedly, an increase in right-side characters from 1990 onwards can still be detected. In their response, Casasanto et al. try to clarify some of these issues. They present an analysis of all names back to 1880 (well, not all names, but all names attested in every year since 1880), and they explain:
“In our longitudinal analysis we only considered names that had been given to more than 100 children in *every year* between 1960 and 2012. By looking at longitudinal changes in the same group of names, this analysis shows changes in names’ popularity over time. If instead you only look at names that were present in a given year, you are performing a haphazard collection of cross-sectional analyses, since many names come and go. The longitudinal analysis we report compares the popularity of the same names over time.“
I am not sure what to think of this. On the one hand, this is certainly a methodologically valid approach. On the other hand, I don’t agree that it is necessarily wrong to take all names into account. Given that 3,625 of all name types are attested in every year from 1960 to 2013 and that only 927 of all name types are attested in every year from 1880 to 2013 (the total number of types being 90,979), the vast majority of names is simply not taken into account in Casasanto et al.’s approach. This is all the more problematic given that parents have become increasingly individualistic in naming their children: The mean number of people sharing one and the same name has decreased in absolute terms since the 1960s. If we normalize these data by dividing them by the total number of name tokens in each year, we find that the mean relative frequency of names has continuously decreased over the timespan covered by the SSA data.
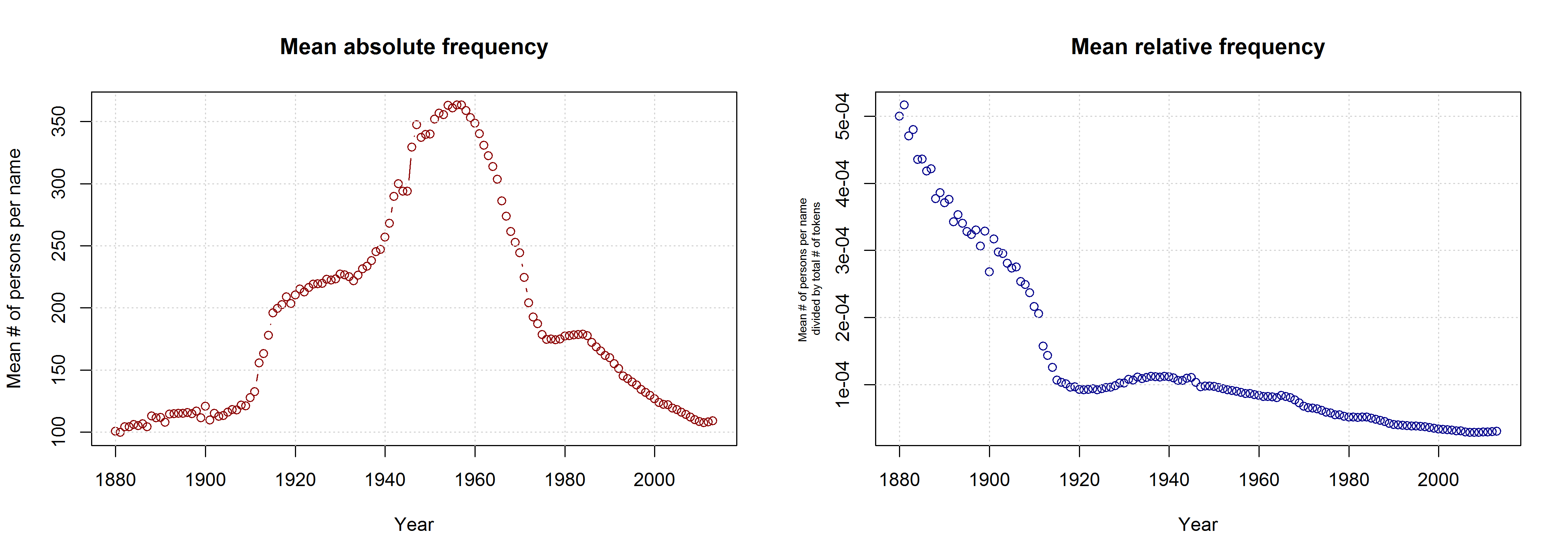
Thus, Casasanto et al. use a sample that might be not very representative of how people name their babies. If the QWERTY effect is a general phenomenon, it should also be found when all available data are taken into account.
As Mark Liberman has already shown, this is indeed the case – although some quite significant ups and downs in the frequency of right-side characters can be detected well before the QWERTY era. But is this rise in frequency from 1990 onwards necessarily due to the spread of QWERTY keyboards – or is there an alternative explanation? Liberman has already pointed to “the popularity of a few names, name-morphemes, or name fragments” as potential factors determining the rise and fall of mean RSA values. In this post, I’d like to take a closer look at one of these potential confounding factors.
Sonorous Sounds and “Soft” Characters
When I saw Casasanto et al.’s data, I was immediately wondering if the change in character distribution could not be explained in terms of phoneme distribution. My PhD advisor, Damaris Nübling, has done some work (see e.g. here [in German]) showing an increasing tendency towards names with a higher proportion of sonorous sounds in Germany. More specifically, she demonstrates that German baby names become more “androgynous” in that male names tend to assume features that used to be characteristic of (German) female names (e.g. hiatus; final full vowel; increase in the overall number of sonorous phonemes). Couldn’t a similar trend be detectable in American baby names?
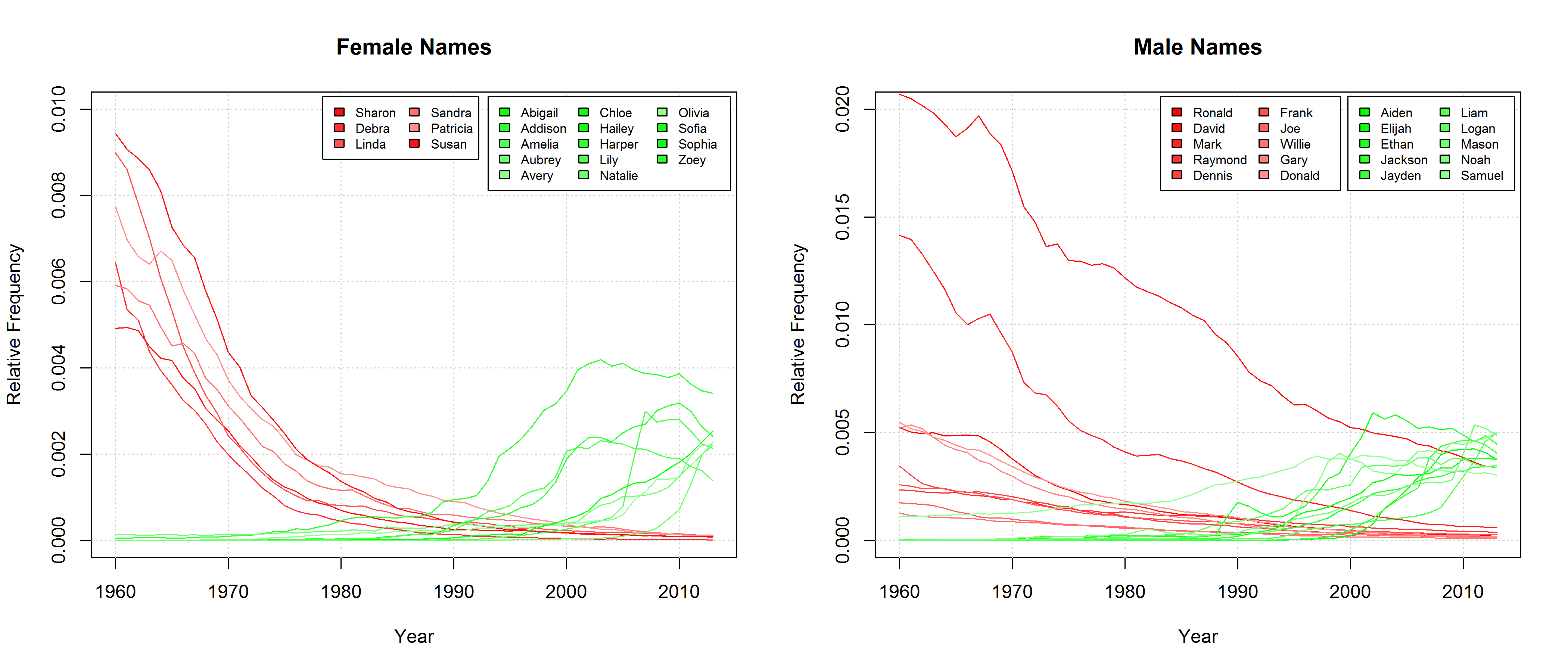
If we take a cursory glance at those names that can be found among the Top 20 most frequent names of at least one year since 1960 and if we single out those names that experienced a particularly strong increase or decrease in frequency, we find that, indeed, sonorous names seem to become more popular. Those names that gain in popularity are characterized by lots of vowels, diphthongs (Aiden, Jayden, Abigail), hiatus (Liam, Zoey), as well as nasals and liquids (Lily, Liam).
To be sure, these cursory observations are not significant in and of themselves. To test the hypothesis if phonological changes can (partly) account for the QWERTY effect in a bit more detail, I basically split the sonority scale in half. I categorized characters typically representing vowels and sonorants as “soft sound characters” and those typically representing obstruents as “hard sound characters”. This is of course a ridiculously crude distinction entailing some problematic classifications. A more thorough analysis would have to take into account the fact that in many cases, one letter can stand for a variety of different phonemes. But as this is just an exploratory analysis for a blog post, I’ll go with this crude binary distinction. In addition, we can justify this binary categorization with an argument presented above: We can assume that the written representations of words are an important part of the linguistic knowledge of present-day language users. Thus, parents will probably not only be concerned with the question how a name sounds – they will also consider how it looks like in written form. Hence, there might be a preference for characters that prototypically represent “soft sounds”, irrespective of the sounds they actually stand for in a concrete case. But this is highly speculative and would have to be investigated in an entirely different experimental setup (e.g. with a psycholinguistic study using nonce names).
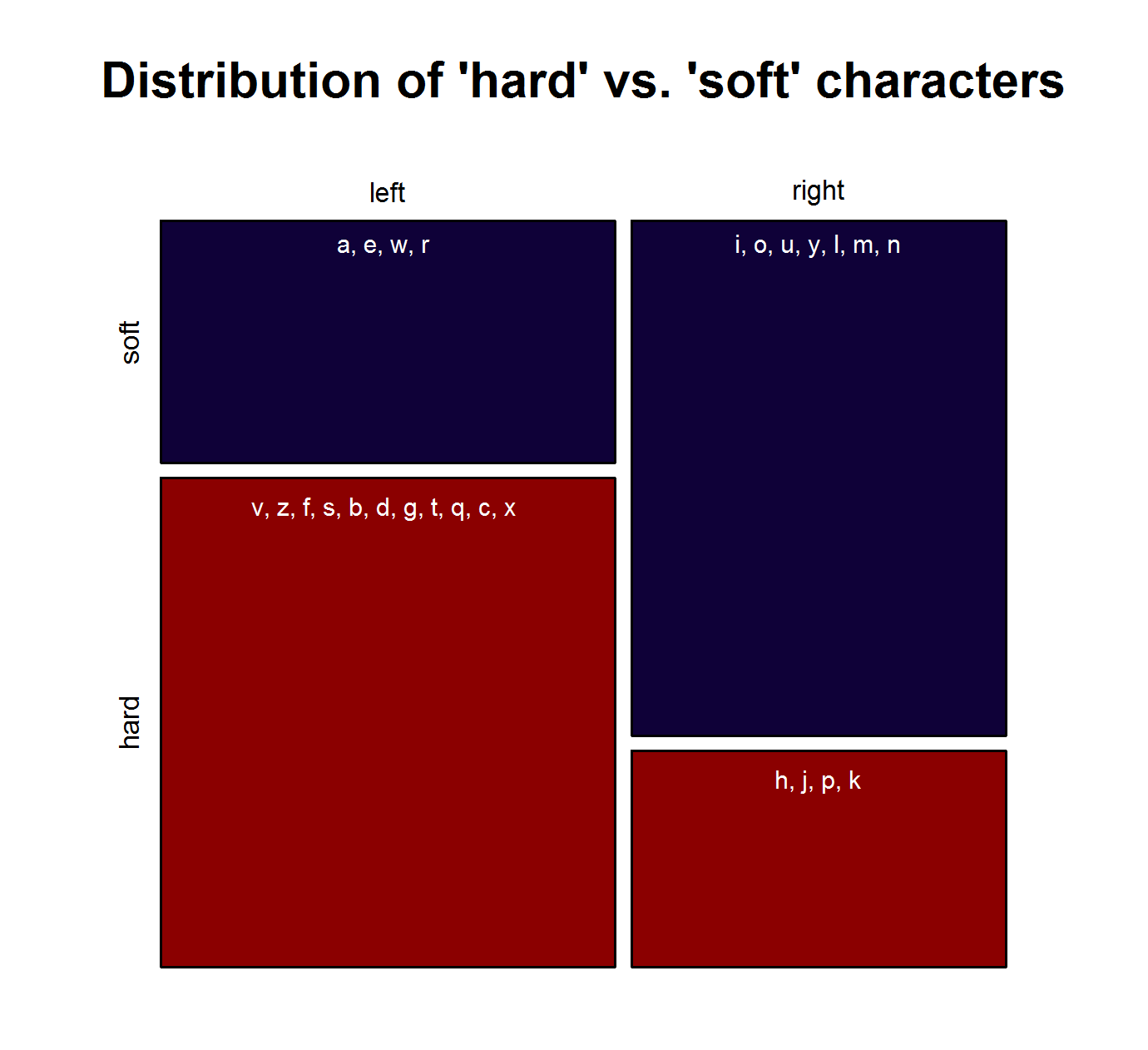
Note that the characters representing “soft sounds” and “hard sounds”, respectively, are distributed unequally over the QWERTY keyboard. Given that most “soft sound characters” are also right-side characters, it is hardly surprising that we cannot only detect an increase in the “Right-Side Advantage” (as well as the “Right-Side Ratio”, see below) of baby names, but also an increase in the mean “Soft Sound Ratio” (SSR – # of soft sound characters / total # of characters). This increase is significant for the time from 1960 to 2013 irrespective of the sample we use: a) all names attested since 1960, b) names attested in every year since 1960, c) names attested in every year since 1960 more than 100 times.
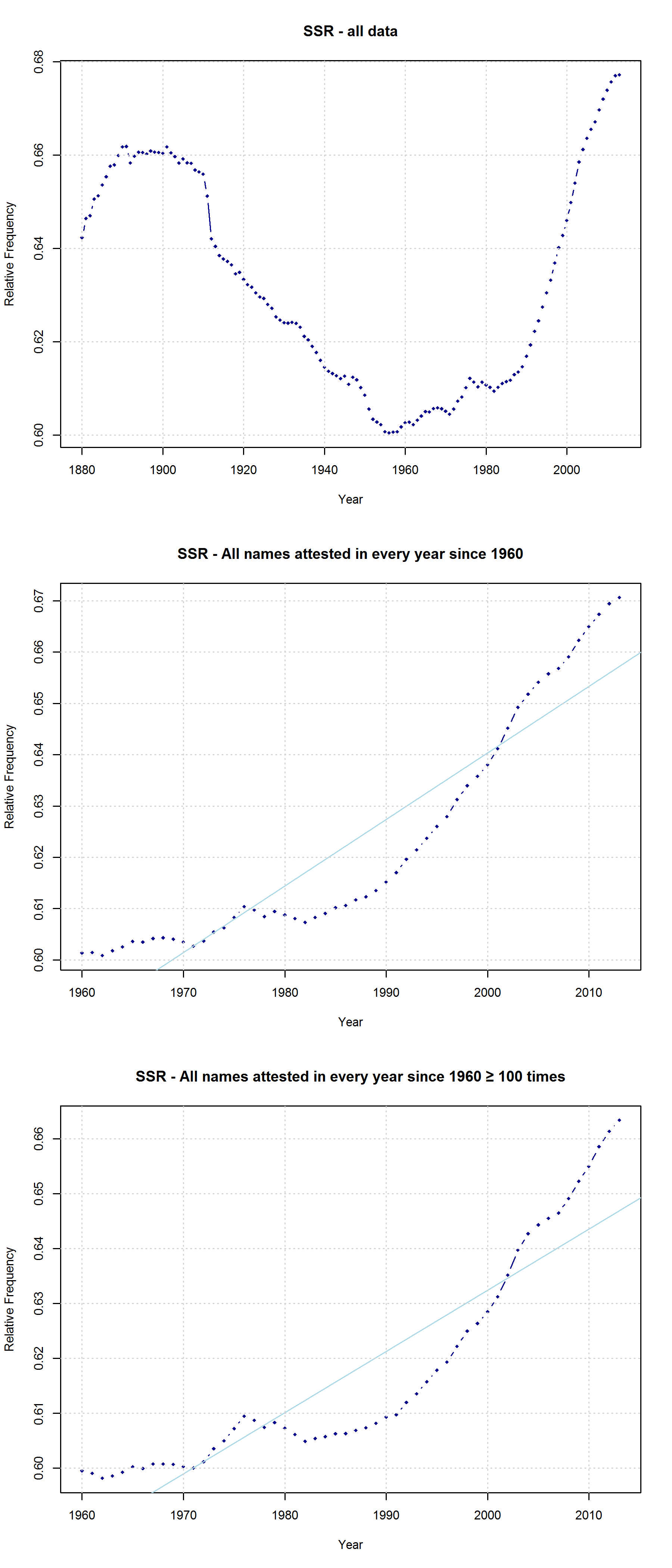
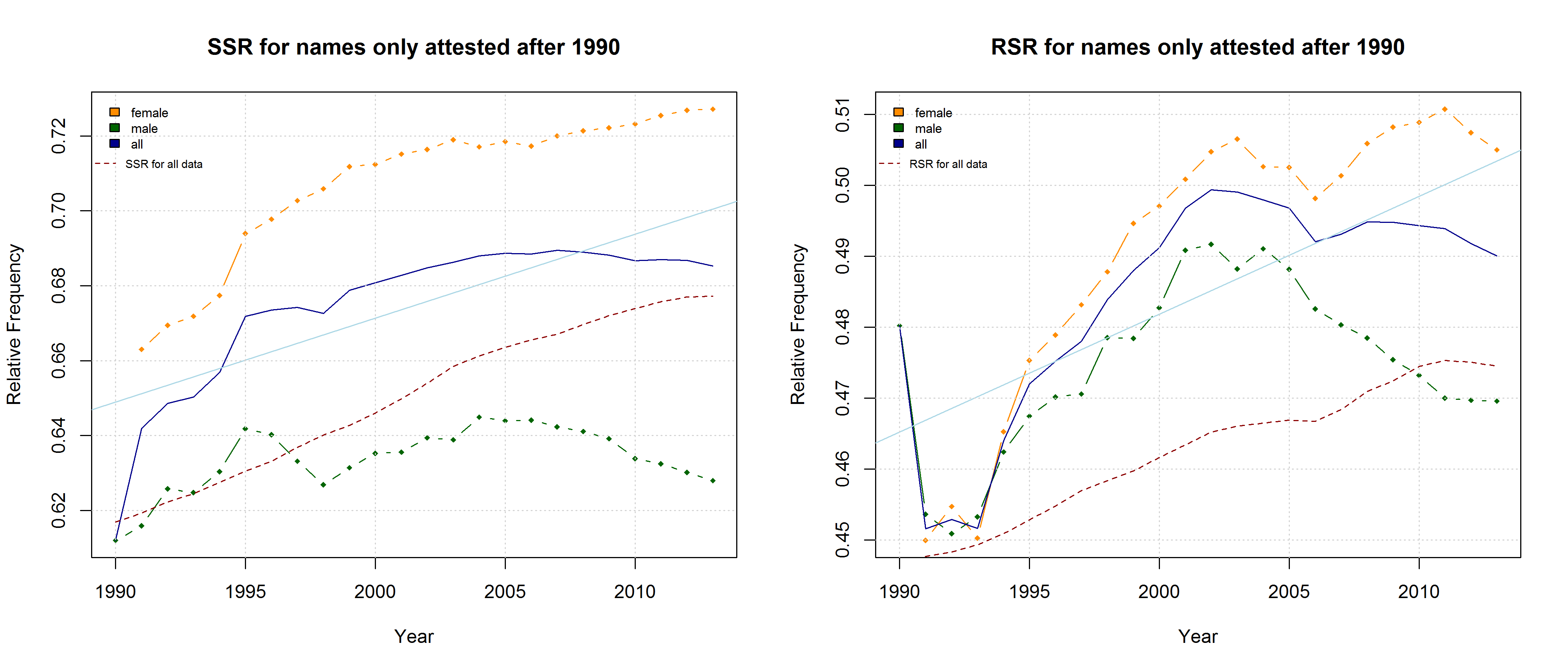
Note that both the “Right-Side Advantage” and the “Soft Sound Ratio” are particularly high in names only attested after 1990. (For the sake of (rough) comparability, I use the relative frequency of right-side characters here, i.e. Right Side Ratio = # of right-side letters / total number of letters.)
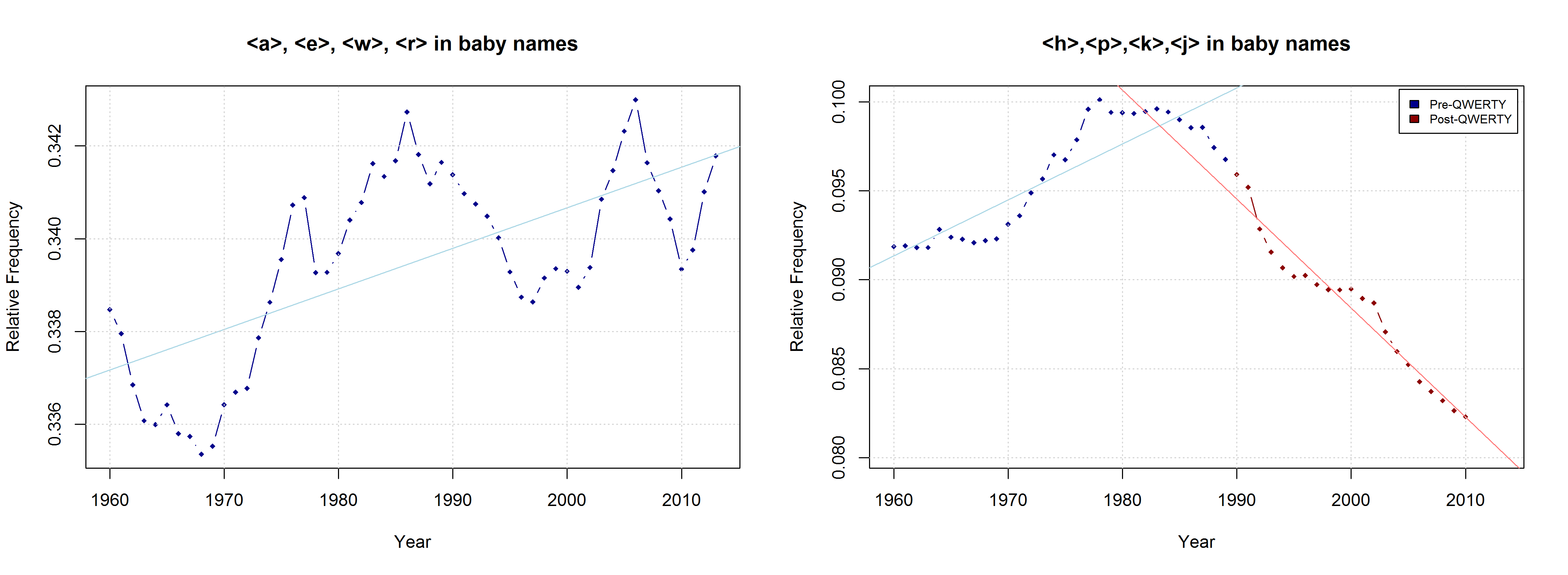
Due to the considerable overlap between right-side and “soft” characters, both the QWERTY Effect and the “Soft Sound” Hypothesis might account for the changes that can be observed in the data. If the QWERTY hypothesis is correct, we should expect an increase for all right-side characters, even those that stand for “hard” sounds. Conversely, we should expect a decrease in the relative frequency of left-side characters, even if they typically represent “soft” sounds. Indeed, the frequency of “Right-Side Hard Characters” does increase – in the time from 1960 to the mid-1980s. In the QWERTY era, by contrast, <h>, <p>, <k>, and <j> suffer a significant decrease in frequency. The frequency of “Left-Side Soft Characters”, by contrast, increases slightly from the late 1960s onwards.
Further potential challenges to the QWERTY Effect and possible alternative experimental setups
The commentors over at Language Log have also been quite creative in coming up with possible alternative explanations and challenging the QWERTY hypothesis by showing that random collections of letters show similarly strong patterns of increase or decrease. Thus, the increase in the frequency of right-side letters in baby names is perhaps equally well, if not better explained by factors independent of character positions on the QWERTY keyboard. Of course, this does not prove that there is no such thing as a QWERTY effect. But as countless cases discussed on Replicated Typo have shown, taking multiple factors into account and considering alternative hypotheses is crucial in the study of cultural evolution. Although the phonological form of words is an obvious candidate as a potential confounding factor, it is not discussed at all in Casasanto et al.’s CogSci paper. However, it is briefly mentioned in Jasmin & Casasanto (2012: 502):
“In any single language, it could happen by chance that words with higher RSAs are more positive, due to sound–valence associations. But despite some commonalities, English, Dutch, and Spanish have different phonological systems and different letter-to-sound mappings.”
While this is certainly true, the sound systems and letter-to-sound mappings of these languages (as well as German and Portugese, which are investigated in the new CogSci paper) are still quite similar in many respects. To rule out the possibility of sound-valence associations, it would be necessary to investigate the phonological makeup of positively vs. negatively connotated words in much more detail.
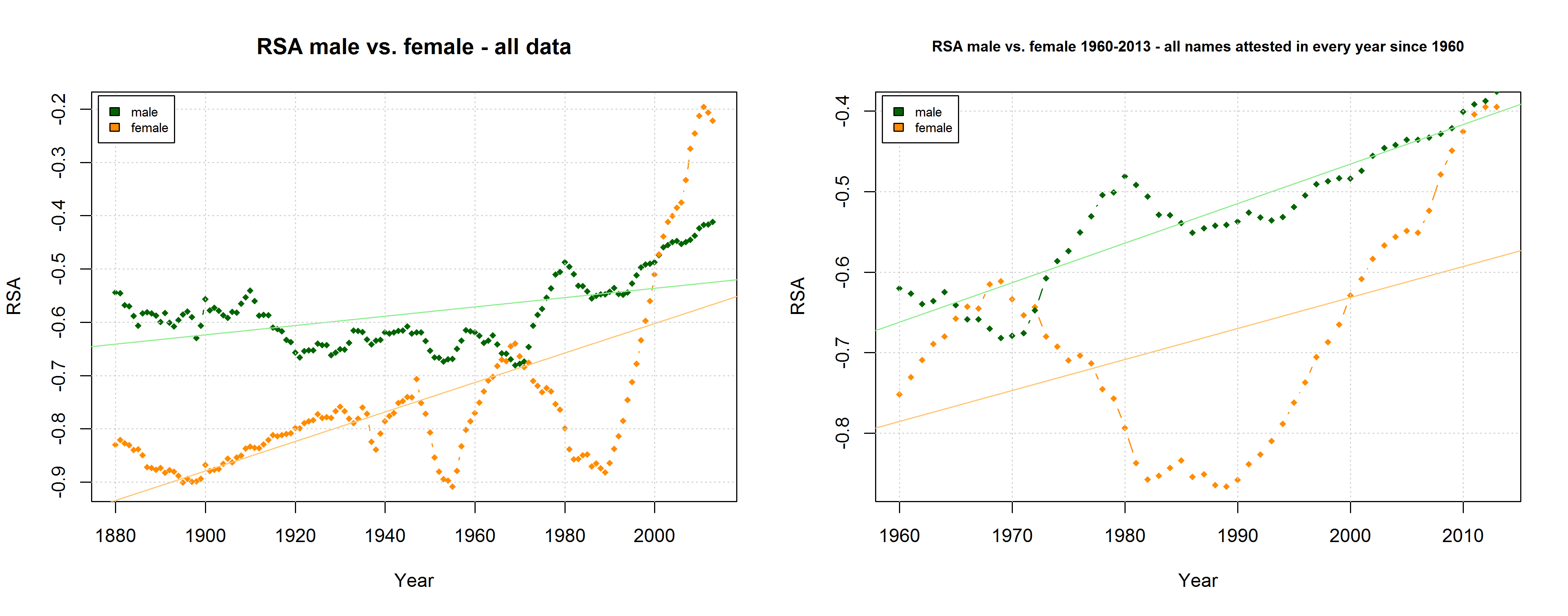
The SSA name lists provide another means to critically examine the QWERTY hypothesis since they differentiate between male and female names. If the QWERTY effect does play a significant role in parents’ name choices, we would expect it to be equally strong for boys names and girls names – or at least approximately so.
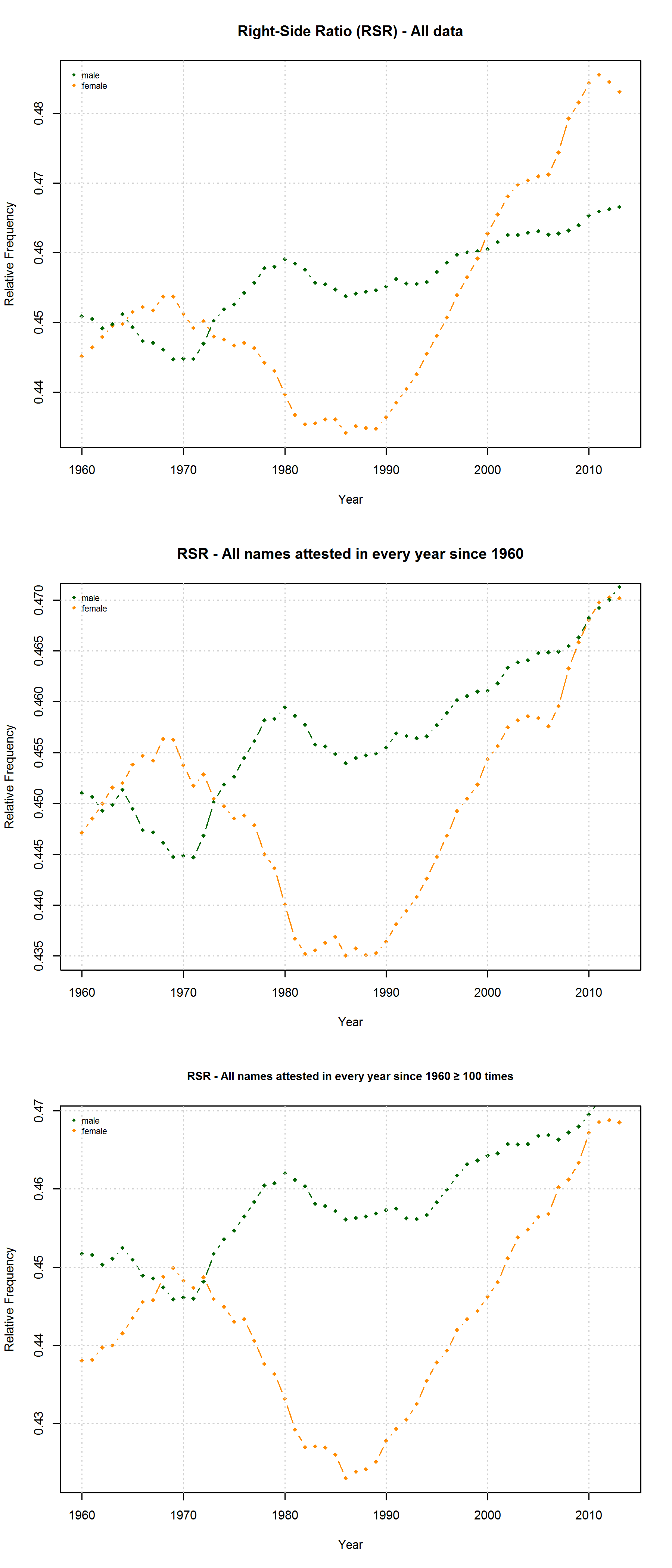
On the hypothesis that other factors such as trend names play a much more important role, by contrast, differences between the developments of male vs. female names are to be expected. Indeed, the data reveal some differences between the RSA / RSR development of boys vs. girls names. At the same time, however, these differences show that the “Soft Sound Hypothesis” can only partly account for the QWERTY Effect since the “Soft Sound Ratios” of male vs. female names develop roughly in parallel.
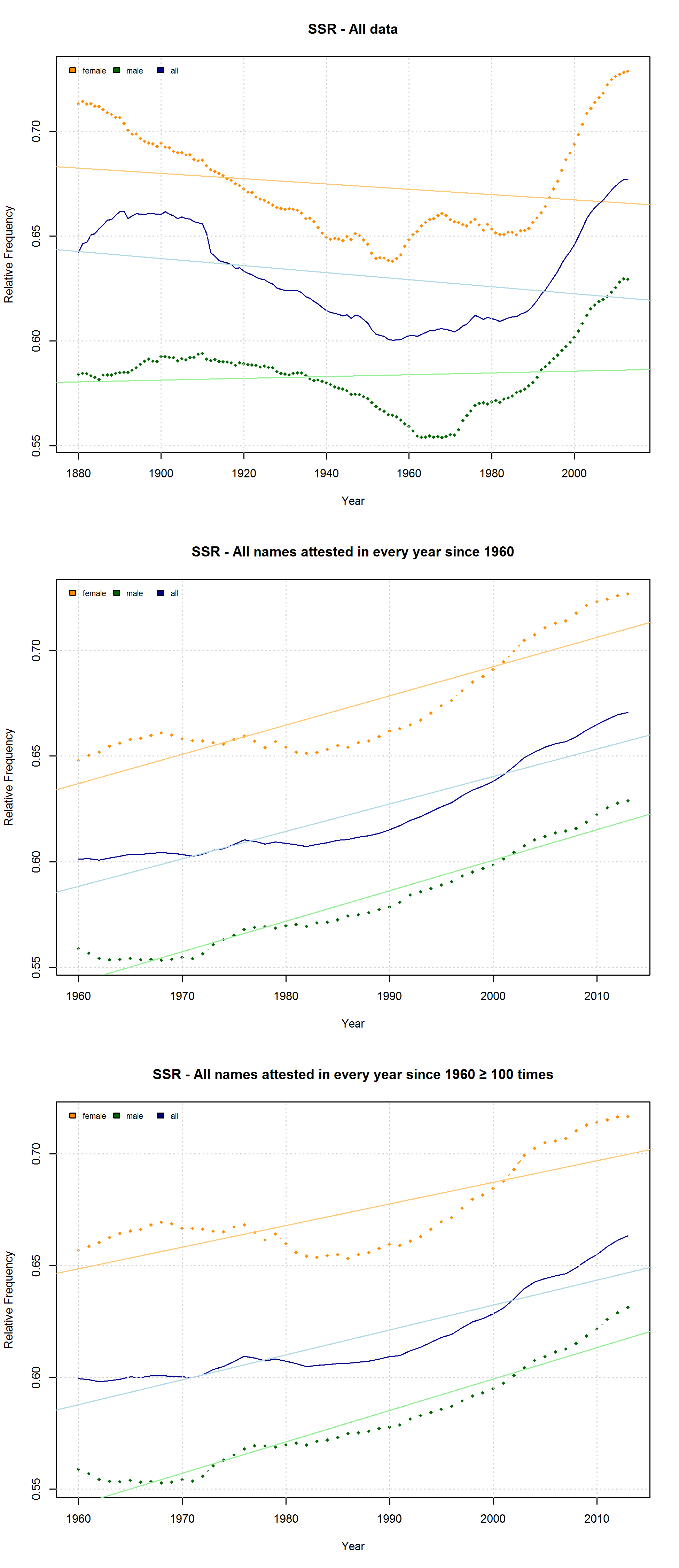
Given the complexity of cultural phenomena such as naming preferences, we would of course hardly expect one factor alone to determine people’s choices. The QWERTY Effect, like the “Soft Sound” Preference, might well be one factor governing parents’ naming decisions. However, the experimental setups used so far to investigate the QWERTY hypothesis are much too prone to spurious correlations to provide convincing evidence for the idea that words with a higher RSA assume more positive valences because of their number of right-side letters.
Granted, the amount of experimental evidence assembled by Casasanto et al. for the QWERTY effect is impressive. Nevertheless, the correlations they find may well be spurious ones. Don’t get me wrong – I’m absolutely in favor of bold hypotheses (e.g. about Neanderthal language). But as a corpus linguist, I doubt that such a subtle preference can be meaningfully investigated using corpus-linguistic methods. As a corpus linguist, you’re always dealing with a lot of variables you can’t control for. This is not too big a problem if your research question is framed appropriately and if potential confounding factors are explicitly taken into account. But when it comes to a possible connection between single letters and emotional valence, the number of potential confounding factors just seems to outweigh the significance of an effect as subtle as the correlation between time and average RSA of baby names. In addition, some of the presumptions of the QWERTY studies would have to be examined independently: Does the average QWERTY user really use their left hand for typing left-side characters and their right hand for typing right-side characters – or are there significant differences between individual typing styles? How fluent is the average QWERTY user in typing? (The question of typing fluency is discussed in passing in the 2012 paper.)
The study of naming preferences entails even more potentially confounding variables. For example, if we assume that people want their children’s names to be as beautiful as possible not only in phonological, but also in graphemic terms, we could speculate that the form of letters (round vs. edgy or pointed) and the position of letters within the graphemic representation of a name play a more or less important role. In addition, you can’t control for, say, all names of persons that were famous in a given year and thus might have influenced parents’ naming choices.
If corpus analyses are, in my view, an inappropriate method to investigate the QWERTY effect, then what about behavioral experiments? In their 2012 paper, Jasmin & Casasanto have reported an experiment in which they elicited valence judgments for pseudowords to rule out possible frequency effects:
“In principle, if words with higher RSAs also had higher frequencies, this could result in a spurious correlation between RSA and valence. Information about lexical frequency was not available for all of the words from Experiments 1 and 2, complicating an analysis to rule out possible frequency effects. In the present experiment, however, all items were novel and, therefore, had frequencies of zero.”
Note, however, that they used phonologically well-formed stimuli such as pleek or ploke. These can be expected to yield associations to existing words such as, say, peak connotated) and poke, or speak and spoke, etc. It would be interesting to repeat this experiment with phonologically ill-formed pseudowords. (After all, participants were told they were reading words in an alien language – why shouldn’t this language only consist of consonants?) Furthermore, Casasanto & Chrysikou (2011) have shown that space-valence mappings can change fairly quickly following a short-term handicap (e.g. being unable to use your right hand as a right-hander). Considering this, it would be interesting to perform experiments using a different kind of keyboard, e.g. an ABCDE keyboard, a KALQ keyboard, or – perhaps the best solution – a keyboard in which the right and the left side of the QWERTY keyboard are simply inverted. In a training phase, participants would have to become acquainted with the unfamiliar keyboard design. In the test phase, then, pseudowords that don’t resemble words in the participants’ native language should be used to figure out whether an ABCDE-, KALQ-, or reverse QWERTY effect can be detected.
References
Casasanto, D. (2009). Embodiment of Abstract Concepts: Good and Bad in Right- and Left-Handers. Journal of Experimental Psychology: General 138, 351–367.
Casasanto, D., & Chrysikou, E. G. (2011). When Left Is “Right”. Motor Fluency Shapes Abstract Concepts. Psychological Science 22, 419–422.
Casasanto, D., Jasmin, K., Brookshire, G., & Gijssels, T. (2014). The QWERTY Effect: How typing shapes word meanings and baby names. In P. Bello, M. Guarini, M. McShane, & B. Scassellati (Eds.), Proceedings of the 36th Annual Conference of the Cognitive Science Society. Austin, TX: Cognitive Science Society.
Jasmin, K., & Casasanto, D. (2012). The QWERTY Effect: How Typing Shapes the Meanings of Words. Psychonomic Bulletin & Review 19, 499–504.
Littauer, R., Roberts, S., Winters, J., Bailes, R., Pleyer, M., & Little, H. (2014). From the Savannah to the Cloud. Blogging Evolutionary Linguistics Research. In L. McCrohon, B. Thompson, T. Verhoef, & H. Yamauchi, The Past, Present, and Future of Language Evolution Research. Student Volume following the 9th International Conference on the Evolution of Language (pp. 121–131).
Nübling, D. (2009). Von Monika zu Mia, von Norbert zu Noah. Zur Androgynisierung der Rufnamen seit 1945 auf prosodisch-phonologischer Ebene. Beiträge zur Namenforschung 44.
Nice post, especially the SSR measures for male and female names! One thing I’ve always wondered is if names are evolving to become more distinguishable from each other. For example, is the average edit distance between the top 100 names increasing over time? Is the most popular name more distinguishable than the 2nd most popular name? I guess this could quantify whether names are becoming more androgynous (or at least confusable between male and female). Has someone looked at this kind of thing?
That’s an interesting question, and as far as I know, no one has done any work on this yet. However, I would speculate that in the case of baby names, it’s more a trade-off between similarity and discriminability… At least if you’re referring to the total set of names rather than specific subcategories. In the case of subcategories such as male vs. female names or names prototypically connected with, say, a specific social status, it does seem very reasonable to assume that names evolve certain highly distinctive features.
The “androgynization” that I mentioned in passing seems to be special to German baby names, at least regarding the features discussed in the post. But of course, there are lots of factors that I didn’t take into account, e.g. syllable structure or graphemic pecularities ( vs. , vs. , etc.).
Interesting. DB sent me a link to this paper, which goes some way to testing similarity vs discriminability (thought it doesn’t address whether the system as a whole is getting more efficient):
Berger, Bradlow, Braunstein & Zhang (2012) From Karen to Katie : Using Baby Names to Understand Cultural Evolution. Psychological Science.
http://jonahberger.com/wp-content/uploads/2013/02/Cultural-Evolution_1.pdf
It would be interesting to see if this effect could be replicated with popular French names, which INSEE keeps detailed records of, and the AZERTY keyboard.
Though they fail to cite it, it seems clear to me that Casasanto et al’s article on baby names is in response to my article, published last year:
Thogmartin, W. E. 2013. The QWERTY effect does not extend to birth names. Names: A Journal of Onomastics 61:47–52.
https://www.academia.edu/2511672/The_QWERTY_effect_does_not_extend_to_birth_names