If you read my last post here at Replicated Typo to the very end, you may remember that I promised to recommend a book and to return to one of the topics of this previous post. I won’t do this today, but I promise I will catch up on it in due time.
What I just did – promising something – is a nice example for one of the two functions of language which Vyvyan Evans from Bangor University distinguished in his talk on “The Human Meaning-Making Engine” yesterday at the UK Cognitive Linguistics Conference. More specifically, the act of promising is an example for the interactive function of language, which is of course closely intertwined with its symbolic function. Evans proposed two different sources for this two functions. The interactive function, he argued, arises from the human instinct for cooperation, whereas meaning arises from the interaction between the linguistic and the conceptual system. While language provides the “How” of meaning-making, the conceptual system provides the “What”. Evans used some vivid examples (e.g. this cartoon exemplifying nonverbal communication) to make clear that communication is not contingent on language. However, “language massively amplifies our communicative potential.” The linguistic system, he argued, has evolved as an executive control system for the conceptual system. While the latter is broadly comparable with that of other animals, especially great apes, the linguistic system is uniquely human. What makes it unique, however, is not the ability to refer to things in the world, which can arguably be found in other animals, as well. What is uniquely human, he argued, is the ability to symbolically refer in a sign-to-sign (word-to-word) direction rather than “just” in a sign-to-world (word-to-world) direction. Evans illustrated this “word-to-word” direction with Hans-Jörg Schmid’s (e.g. 2000; see also here) work on “shell nouns”, i.e. nouns “used in texts to refer to other passages of the text and to reify them and characterize them in certain ways.” For instance, the stuff I was talking about in the last paragraph would be an example of a shell noun.
According to Evans, the “word-to-word” direction is crucial for the emergence of e.g. lexical categories and syntax, i.e. the “closed-class” system of language. Grammaticalization studies indicate that the “open-class” system of human languages is evolutionarily older than the “closed-class” system, which is comprised of grammatical constructions (in the broadest sense). However, Evans also emphasized that there is a lot of meaning even in closed-class constructions, as e.g. Adele Goldberg’s work on argument structure constructions shows: We can make sense of a sentence like “Someone somethinged something to someone” although the open-class items are left unspecified.
Constructions, he argued, index or cue simulations, i.e. re-activations of body-based states stored in cortical and subcortical brain regions. He discussed this with the example of the cognitive model for Wales: We know that Wales is a geographical entity. Furthermore, we know that “there are lots of sheep, that the Welsh play Rugby, and that they dress in a funny way.” (Sorry, James. Sorry, Sean.) Oh, and “when you’re in Wales, you shouldn’t say, It’s really nice to be in England, because you will be lynched.”
On a more serious note, the cognitive models connected to closed-class constructions, e.g. simple past -ed or progressive -ing, are of course much more abstract but can also be assumed to arise from embodied simulations (cf. e.g. Bergen 2012). But in addition to the cognitive dimension, language of course also has a social and interactive dimension drawing on the apparently instinctive drive towards cooperative behaviour. Culture (or what Tomasello calls “collective intentionality”) is contigent on this deep instinct which Levinson (2006) calls the “human interaction engine”. Evans’ “meaning-making engine” is the logical continuation of this idea.
Just like Evans’ theory of meaning (LCCM theory), his idea of the “meaning-making engine” is basically an attempt at integrating a broad variety of approaches into a coherent model. This might seem a bit eclectic at first, but it’s definitely not the worst thing to do, given that there is significant conceptual overlap between different theories which, however, tends to be blurred by terminological incongruities. Apart from Deacon’s (1997) “Symbolic Species” and Tomasello’s work on shared and joint intentionality, which he explicitly discussed, he draws on various ideas that play a key role in Cognitive Linguistics. For example, the distinction between open- and closed-class systems features prominently in Talmy’s (2000) Cognitive Semantics, as does the notion of the human conceptual system. The idea of meaning as conceptualization and embodied simulation of course goes back to the groundbreaking work of, among others, Lakoff (1987) and Langacker (1987, 1991), although empirical support for this hypothesis has been gathered only recently in the framework of experimental semantics (cf. Matlock & Winter forthc. – if you have an account at academia.edu, you can read this paper here). All in all, then, Evans’ approach might prove an important further step towards integrating Cognitive Linguistics and language evolution research, as has been proposed by Michael and James in a variety of talks and papers (see e.g. here).
Needless to say, it’s impossible to judge from a necessarily fairly sketchy conference presentation if this model qualifies as an appropriate and comprehensive account of the emergence of meaning. But it definitely looks promising and I’m looking forward to Evans’ book-length treatment of the topics he touched upon in his talk. For now, we have to content ourselves with his abstract from the conference booklet:
In his landmark work, The Symbolic Species (1997), cognitive neurobiologist Terrence Deacon argues that human intelligence was achieved by our forebears crossing what he terms the “symbolic threshold”. Language, he argues, goes beyond the communicative systems of other species by moving from indexical reference – relations between vocalisations and objects/events in the world — to symbolic reference — the ability to develop relationships between words — paving the way for syntax. But something is still missing from this picture. In this talk, I argue that symbolic reference (in Deacon’s terms), was made possible by parametric knowledge: lexical units have a type of meaning, quite schematic in nature, that is independent of the objects/entities in the world that words refer to. I sketch this notion of parametric knowledge, with detailed examples. I also consider the interactional intelligence that must have arisen in ancestral humans, paving the way for parametric knowledge to arise. And, I also consider changes to the primate brain-plan that must have co-evolved with this new type of knowledge, enabling modern Homo sapiens to become so smart.
References
Bergen, Benjamin K. (2012): Louder than Words. The New Science of How the Mind Makes Meaning. New York: Basic Books.
Deacon, Terrence W. (1997): The Symbolic Species. The Co-Evolution of Language and the Brain. New York, London: Norton.
Lakoff, George (1987): Women, Fire, and Dangerous Things. What Categories Reveal about the Mind. Chicago: The University of Chicago Press.
Langacker, Ronald W. (1987): Foundations of Cognitive Grammar. Vol. 1. Theoretical Prerequisites. Stanford: Stanford University Press.
Langacker, Ronald W. (1991): Foundations of Cognitive Grammar. Vol. 2. Descriptive Application. Stanford: Stanford University Press.
Levinson, Stephen C. (2006): On the Human “Interaction Engine”. In: Enfield, Nick J.; Levinson, Stephen C. (eds.): Roots of Human Sociality. Culture, Cognition and Interaction. Oxford: Berg, 39–69.
Matlock, Teenie & Winter, Bodo (forthc): Experimental Semantics. In: Heine, Bernd; Narrog, Heiko (eds.): The Oxford Handbook of Linguistic Analysis. 2nd ed. Oxford: Oxford University Press.
Schmid, Hans-Jörg (2000): English Abstract Nouns as Conceptual Shells. From Corpus to Cognition. Berlin, New York: De Gruyter (Topics in English Linguistics, 34).
Talmy, Leonard (2000): Toward a Cognitive Semantics. 2 vol. Cambridge, Mass: MIT Press.
Oh wait, I’m not a guest anymore. Thanks to James for inviting me to become a regular contributor to Replicated Typo. I hope I will have to say some interesting things about the evoution of language, cognition, and culture, and I promise that I’ll try to keep my next posts a bit shorter than the guest post two weeks ago.
Today I’d like to pick up on an ongoing discussion over at Language Log. In a series of blog posts in early 2012, Mark Liberman has taken issue with the so-called “QWERTY effect”. The QWERTY effect seems like an ideal topic for my first regular post as it is tightly connected to some key topics of Replicated Typo: Cultural evolution, the cognitive basis of language, and, potentially, spurious correlations. In addition, Liberman’s coverage of the QWERTY effect has spawned an interesting discussion about research blogging (cf. Littauer et al. 2014).
But what is the QWERTY effect, actually? According to Kyle Jasmin and Daniel Casasanto (Jasmin & Casasanto 2012), the written form of words can influence their meaning, more particularly, their emotional valence. The idea, in a nutshell, is this: Words that contain more characters from the right-hand side of the QWERTY keyboard tend to “acquire more positive valences” (Jasmin & Casasanto 2012). Casasanto and his colleagues tested this hypothesis with a variety of corpus analyses and valence rating tasks.
Whenever I tell fellow linguists who haven’t heard of the QWERTY effect yet about these studies, their reactions are quite predictable, ranging from “WHAT?!?” to “asdf“. But unlike other commentors, I don’t want to reject the idea that a QWERTY effect exists out of hand. Indeed, there is abundant evidence that “right” is commonly associated with “good”. In his earlier papers, Casasanto provides quite convincing experimental evidence for the bodily basis of the cross-linguistically well-attested metaphors RIGHT IS GOOD and LEFT IS BAD (e.g. Casasanto 2009). In addition, it is fairly obvious that at the end of the 20th century, computer keyboards started to play an increasingly important role in our lives. More and more people have full size keyboards somewhere in their home. Also, it seems legitimate to assume that in a highly literate society, written representations of words form an important part of our linguistic knowledge. Given these factors, the QWERTY effect is not such an outrageous idea. However, measuring it by determining the “Right-Side Advantage” of words in corpora is highly problematic since a variety of potential confounding factors are not taken into account.
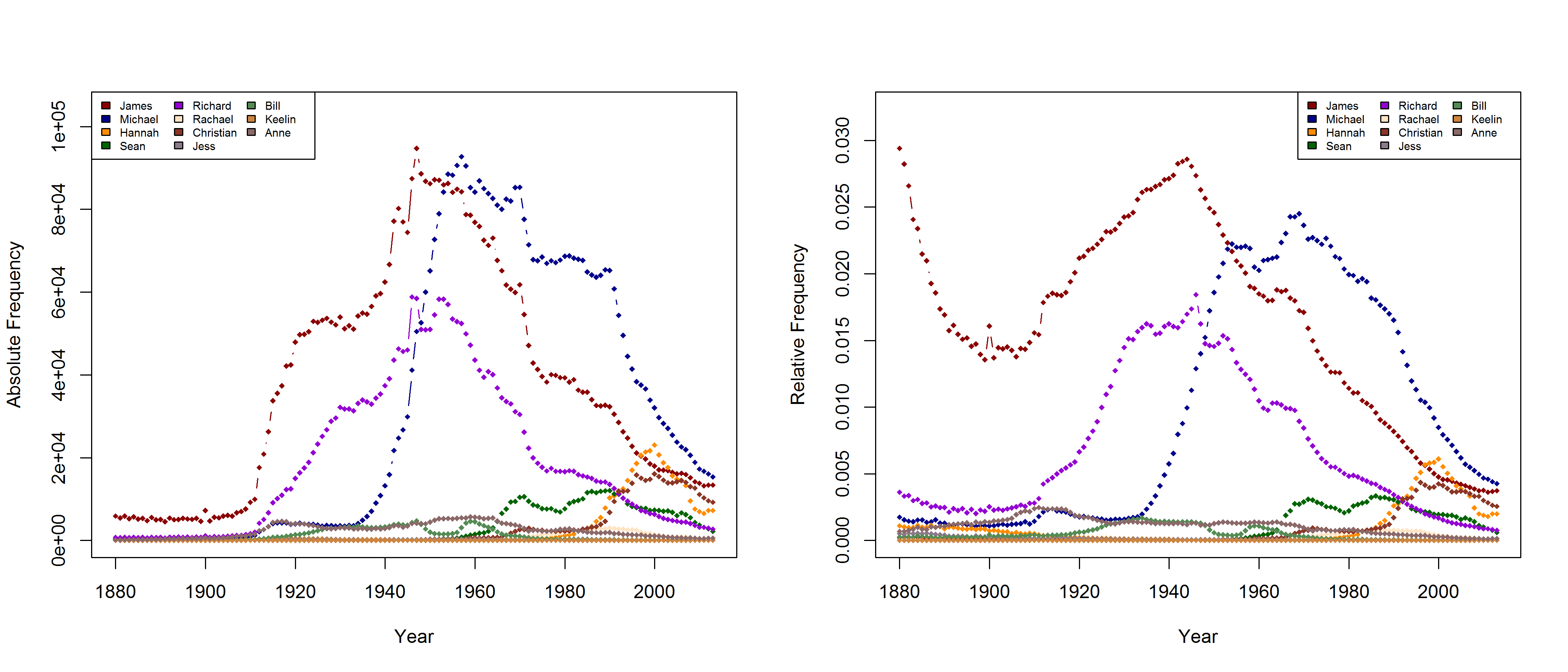
Finding the Right Name(s)
Frequencies of some (almost) randomly selected names in the USA.
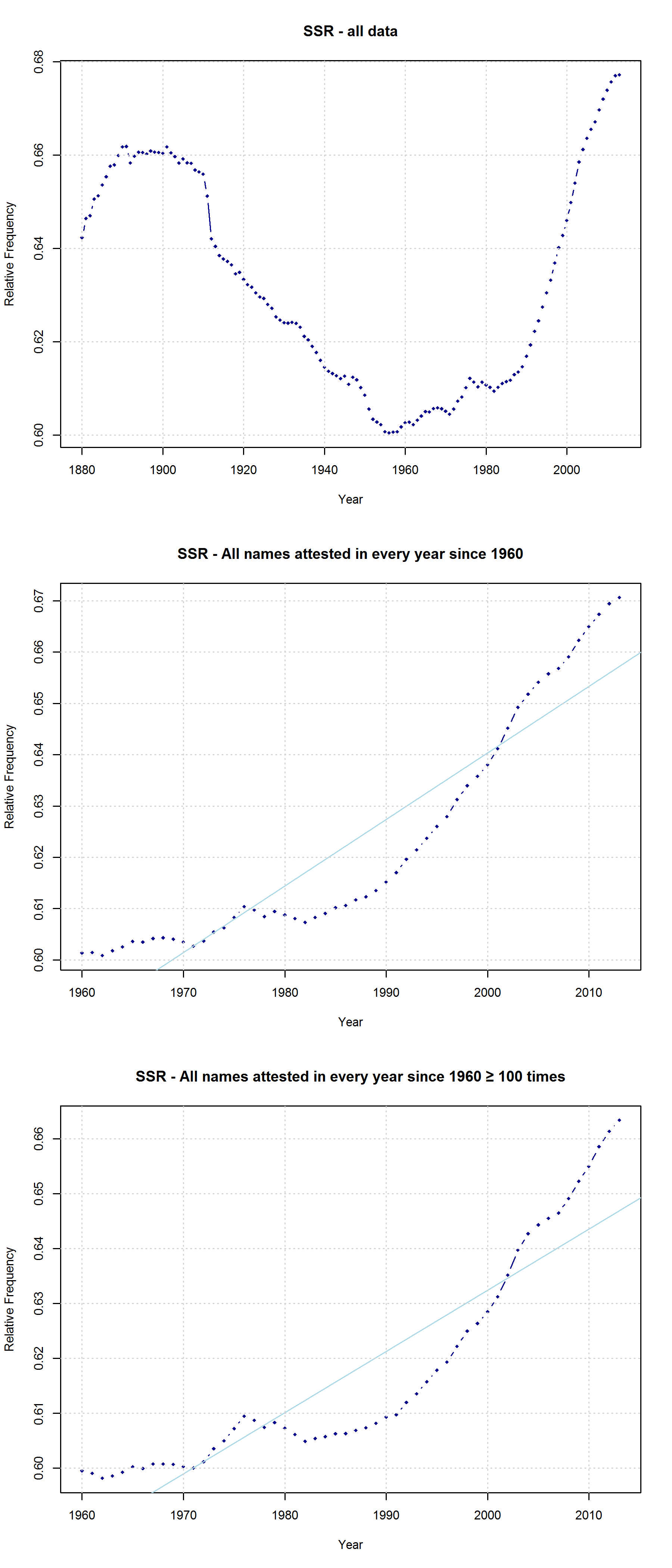
In a new CogSci paper, Casasanto, Jasmin, Geoffrey Brookshire, and Tom Gijssels present five new experiments to support the QWERTY hypothesis. Since I am based at a department with a strong focus on onomastics, I found their investigation of baby names particularly interesting. Drawing on data from the US Social Security Administration website, they analyze all names that have been given to more than 100 babys in every year from 1960 to 2012. To determine the effect of keyboard position, they use a measure they call “Right Side Adventage” (RSA): [(#right-side letters)-(#left-side letters)]. They find that
“that the mean RSA has increased since the popularization of the QWERTY keyboard, as indicated by a correlation between the year and average RSA in that year (1960–2012, r = .78, df = 51, p =8.6 × 10-12“
In addition,
“Names invented after 1990 (n = 38,746) use more letters from the right side of the keyboard than names in use before 1990 (n = 43,429; 1960–1990 mean RSA = -0.79; 1991–2012 mean RSA = -0.27, t(81277.66) = 33.3, p < 2.2 × 10-16 […]). This difference remained significant when length was controlled by dividing each name’s RSA by the number of letters in the name (t(81648.1) = 32.0, p < 2.2 × 10-16)”
Mark Liberman has already pointed to some problematic aspects of this analysis (but see also Casasanto et al.’s reply). They do not justify why they choose the timeframe of 1960-2012 (although data are available from 1880 onwards), nor do they explain why they only include names given to at least 100 children in each year. Liberman shows that the results look quite different if all available data are taken into account – although, admittedly, an increase in right-side characters from 1990 onwards can still be detected. In their response, Casasanto et al. try to clarify some of these issues. They present an analysis of all names back to 1880 (well, not all names, but all names attested in every year since 1880), and they explain:
“In our longitudinal analysis we only considered names that had been given to more than 100 children in *every year* between 1960 and 2012. By looking at longitudinal changes in the same group of names, this analysis shows changes in names’ popularity over time. If instead you only look at names that were present in a given year, you are performing a haphazard collection of cross-sectional analyses, since many names come and go. The longitudinal analysis we report compares the popularity of the same names over time.“
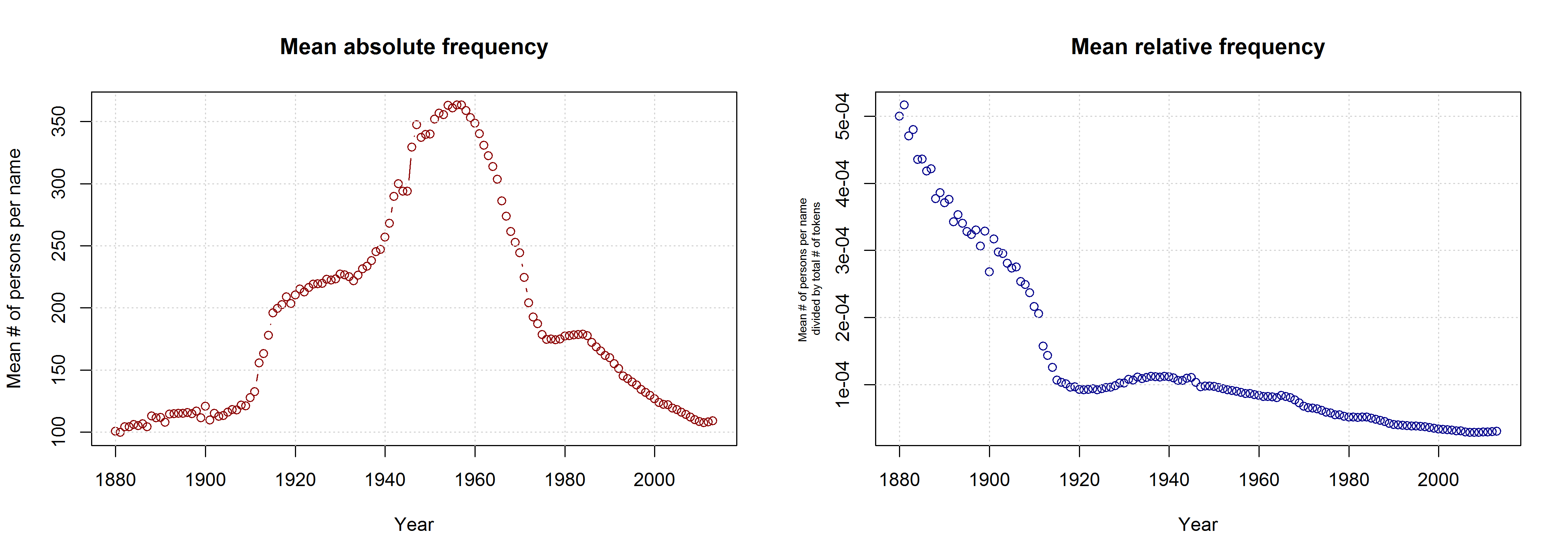
I am not sure what to think of this. On the one hand, this is certainly a methodologically valid approach. On the other hand, I don’t agree that it is necessarily wrong to take all names into account. Given that 3,625 of all name types are attested in every year from 1960 to 2013 and that only 927 of all name types are attested in every year from 1880 to 2013 (the total number of types being 90,979), the vast majority of names is simply not taken into account in Casasanto et al.’s approach. This is all the more problematic given that parents have become increasingly individualistic in naming their children: The mean number of people sharing one and the same name has decreased in absolute terms since the 1960s. If we normalize these data by dividing them by the total number of name tokens in each year, we find that the mean relative frequency of names has continuously decreased over the timespan covered by the SSA data.
Mean frequency of a name (i.e. mean number of people sharing one name) in absolute and relative terms, respectively.
Thus, Casasanto et al. use a sample that might be not very representative of how people name their babies. If the QWERTY effect is a general phenomenon, it should also be found when all available data are taken into account.
As Mark Liberman has already shown, this is indeed the case – although some quite significant ups and downs in the frequency of right-side characters can be detected well before the QWERTY era. But is this rise in frequency from 1990 onwards necessarily due to the spread of QWERTY keyboards – or is there an alternative explanation? Liberman has already pointed to “the popularity of a few names, name-morphemes, or name fragments” as potential factors determining the rise and fall of mean RSA values. In this post, I’d like to take a closer look at one of these potential confounding factors.
Sonorous Sounds and “Soft” Characters
When I saw Casasanto et al.’s data, I was immediately wondering if the change in character distribution could not be explained in terms of phoneme distribution. My PhD advisor, Damaris Nübling, has done some work (see e.g. here [in German]) showing an increasing tendency towards names with a higher proportion of sonorous sounds in Germany. More specifically, she demonstrates that German baby names become more “androgynous” in that male names tend to assume features that used to be characteristic of (German) female names (e.g. hiatus; final full vowel; increase in the overall number of sonorous phonemes). Couldn’t a similar trend be detectable in American baby names?
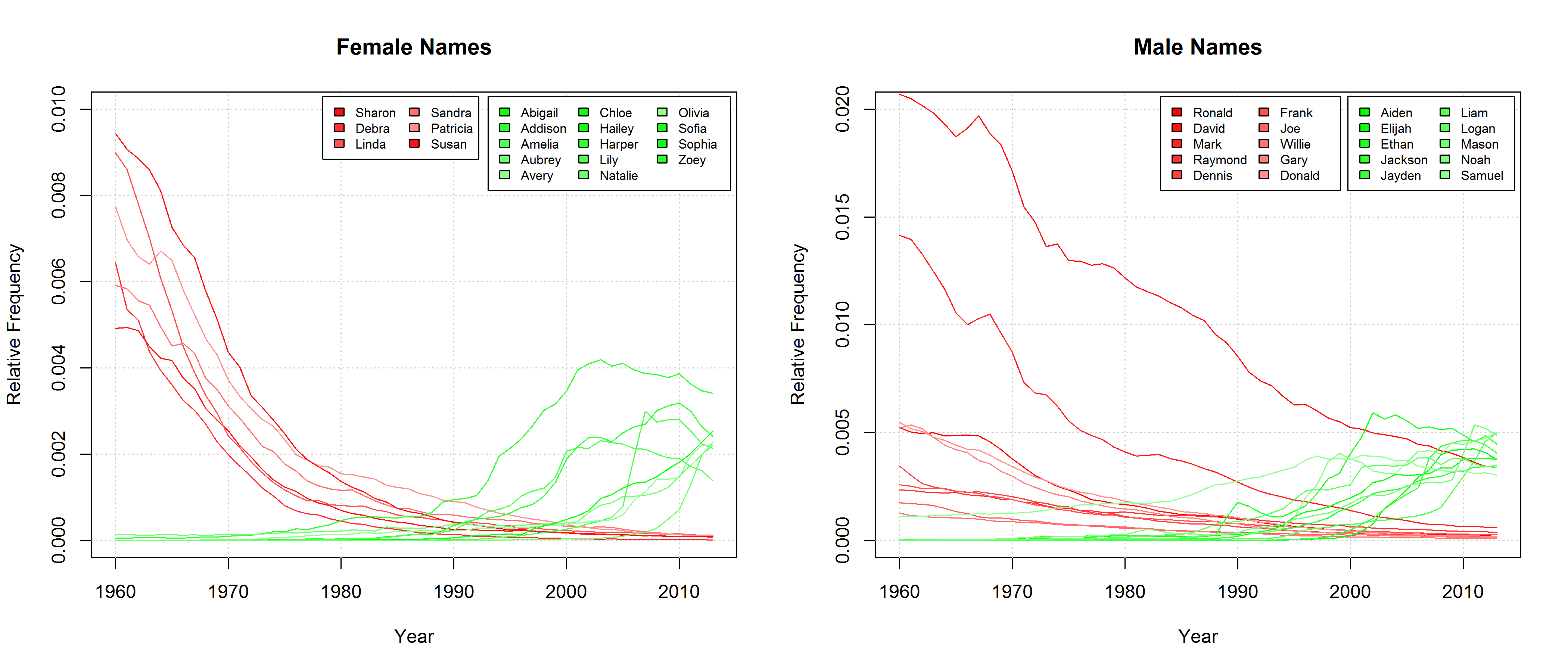
Names showing particularly strong frequency changes among those names that appear among the Top 20 most frequent names at least once between 1960 and 2013.
If we take a cursory glance at those names that can be found among the Top 20 most frequent names of at least one year since 1960 and if we single out those names that experienced a particularly strong increase or decrease in frequency, we find that, indeed, sonorous names seem to become more popular. Those names that gain in popularity are characterized by lots of vowels, diphthongs (Aiden, Jayden, Abigail), hiatus (Liam, Zoey), as well as nasals and liquids (Lily, Liam).
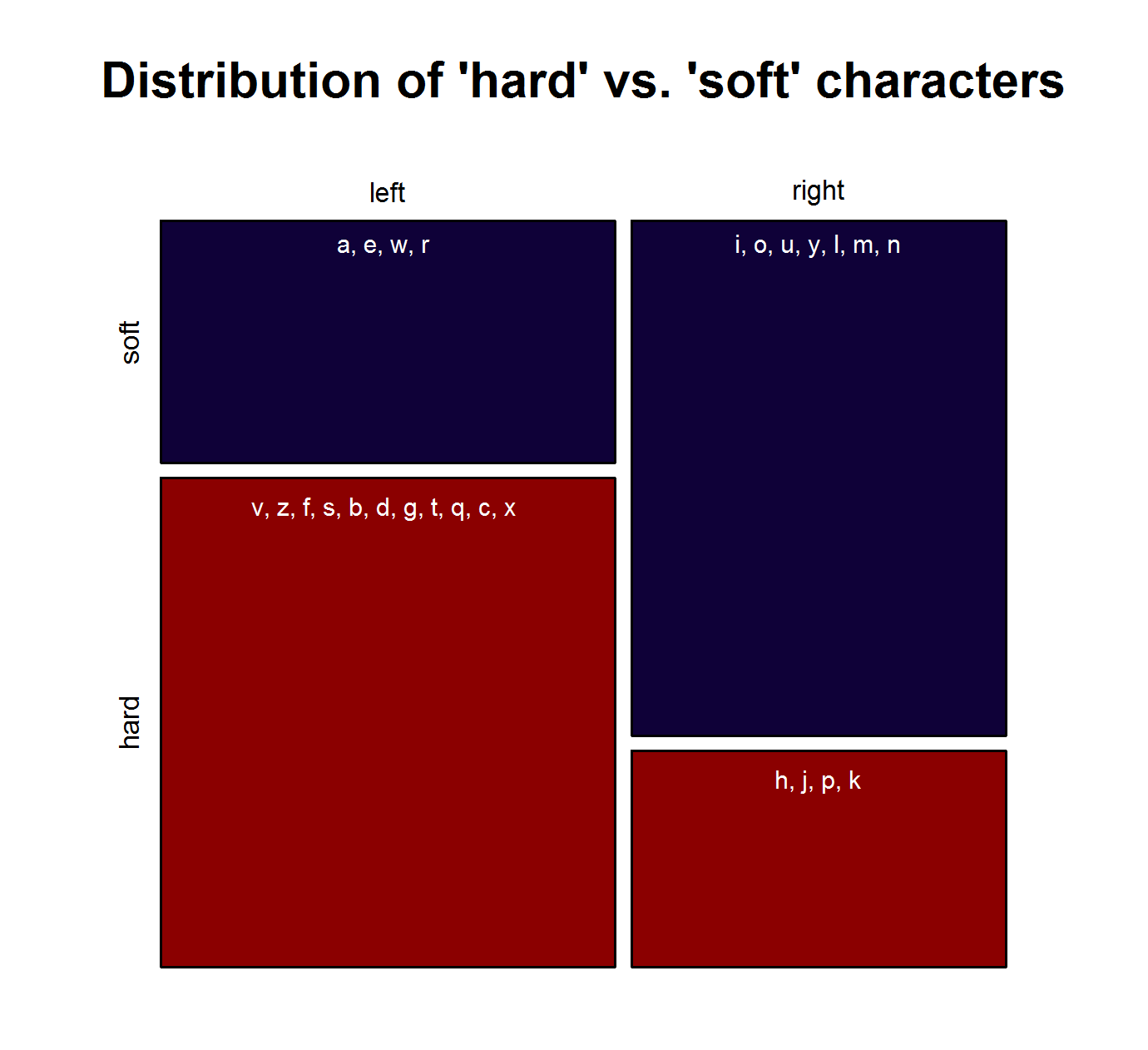
To be sure, these cursory observations are not significant in and of themselves. To test the hypothesis if phonological changes can (partly) account for the QWERTY effect in a bit more detail, I basically split the sonority scale in half. I categorized characters typically representing vowels and sonorants as “soft sound characters” and those typically representing obstruents as “hard sound characters”. This is of course a ridiculously crude distinction entailing some problematic classifications. A more thorough analysis would have to take into account the fact that in many cases, one letter can stand for a variety of different phonemes. But as this is just an exploratory analysis for a blog post, I’ll go with this crude binary distinction. In addition, we can justify this binary categorization with an argument presented above: We can assume that the written representations of words are an important part of the linguistic knowledge of present-day language users. Thus, parents will probably not only be concerned with the question how a name sounds – they will also consider how it looks like in written form. Hence, there might be a preference for characters that prototypically represent “soft sounds”, irrespective of the sounds they actually stand for in a concrete case. But this is highly speculative and would have to be investigated in an entirely different experimental setup (e.g. with a psycholinguistic study using nonce names).
Distribution of “hard sound” vs. “soft sound” characters on the QWERTY keyboard.
Note that the characters representing “soft sounds” and “hard sounds”, respectively, are distributed unequally over the QWERTY keyboard. Given that most “soft sound characters” are also right-side characters, it is hardly surprising that we cannot only detect an increase in the “Right-Side Advantage” (as well as the “Right-Side Ratio”, see below) of baby names, but also an increase in the mean “Soft Sound Ratio” (SSR – # of soft sound characters / total # of characters). This increase is significant for the time from 1960 to 2013 irrespective of the sample we use: a) all names attested since 1960, b) names attested in every year since 1960, c) names attested in every year since 1960 more than 100 times.
“Soft Sound Ratio” in three different samples: a) All names attested in the SSA data; b) all names attested in every year since 1960; c) all names attested in every year since 1960 at least 100 times.
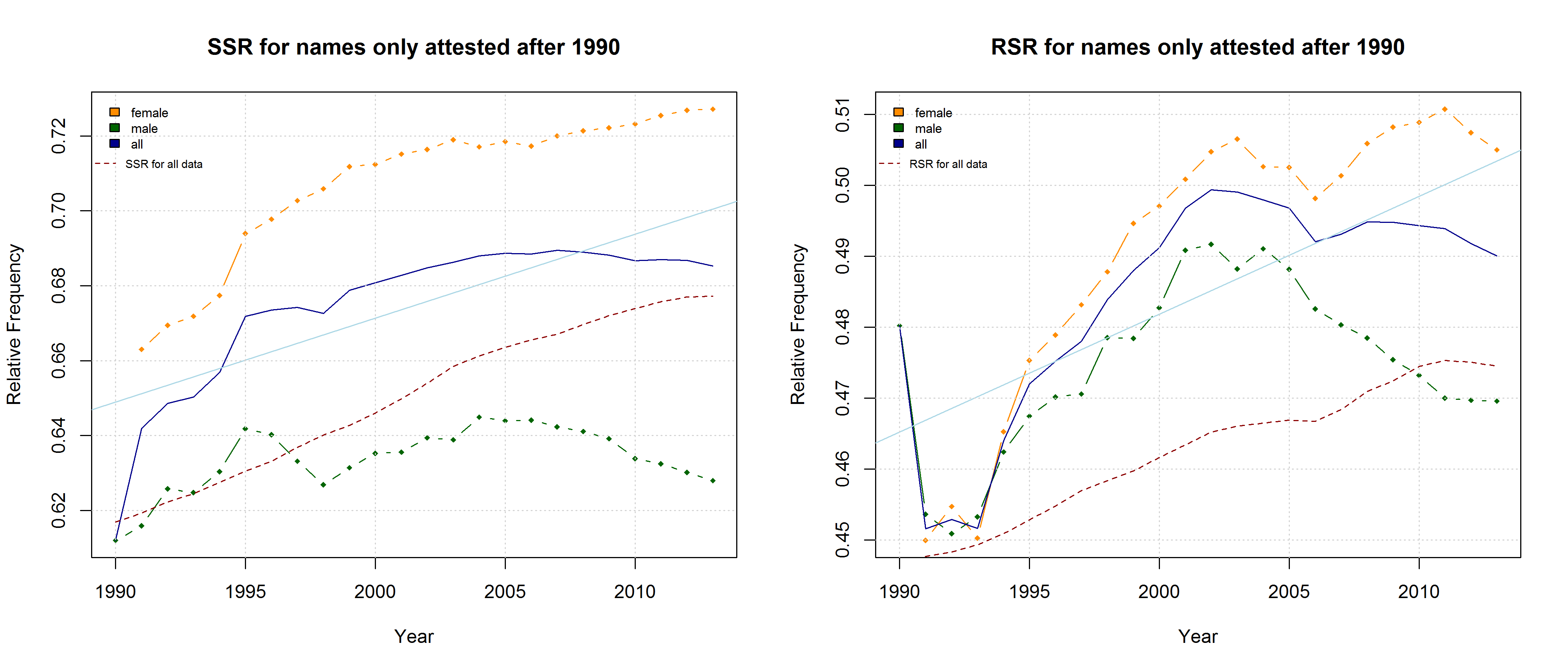
Note that both the “Right-Side Advantage” and the “Soft Sound Ratio” are particularly high in names only attested after 1990. (For the sake of (rough) comparability, I use the relative frequency of right-side characters here, i.e. Right Side Ratio = # of right-side letters / total number of letters.)
“Soft Sound Ratio” and “Right-Side Ratio” for names only attested after 1990.
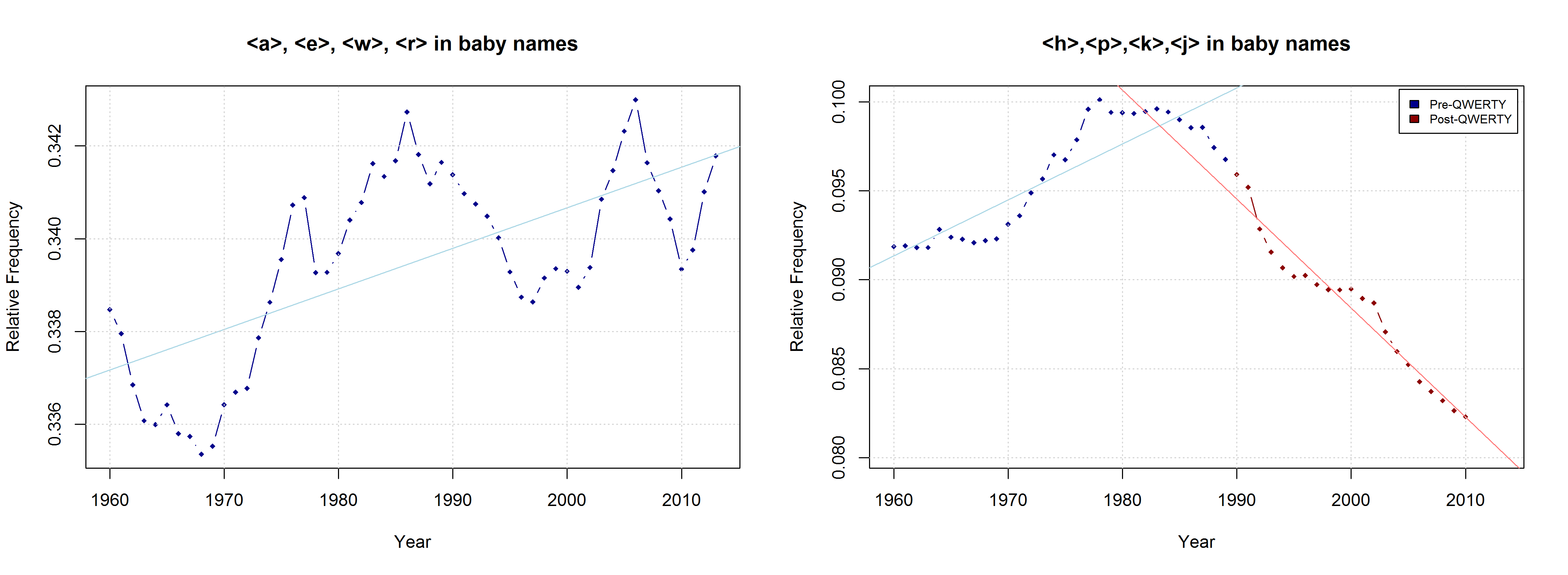
Due to the considerable overlap between right-side and “soft” characters, both the QWERTY Effect and the “Soft Sound” Hypothesis might account for the changes that can be observed in the data. If the QWERTY hypothesis is correct, we should expect an increase for all right-side characters, even those that stand for “hard” sounds. Conversely, we should expect a decrease in the relative frequency of left-side characters, even if they typically represent “soft” sounds. Indeed, the frequency of “Right-Side Hard Characters” does increase – in the time from 1960 to the mid-1980s. In the QWERTY era, by contrast, <h>, <p>, <k>, and <j> suffer a significant decrease in frequency. The frequency of “Left-Side Soft Characters”, by contrast, increases slightly from the late 1960s onwards.
Frequency of left-side “soft” characters and right-side “hard” characters in all baby names attested from 1960 to 2013.
Further potential challenges to the QWERTY Effect and possible alternative experimental setups
The commentors over at Language Log have also been quite creative in coming up with possible alternative explanations and challenging the QWERTY hypothesis by showing that random collections of letters show similarly strong patterns of increase or decrease. Thus, the increase in the frequency of right-side letters in baby names is perhaps equally well, if not better explained by factors independent of character positions on the QWERTY keyboard. Of course, this does not prove that there is no such thing as a QWERTY effect. But as countless cases discussed on Replicated Typo have shown, taking multiple factors into account and considering alternative hypotheses is crucial in the study of cultural evolution. Although the phonological form of words is an obvious candidate as a potential confounding factor, it is not discussed at all in Casasanto et al.’s CogSci paper. However, it is briefly mentioned in Jasmin & Casasanto (2012: 502):
“In any single language, it could happen by chance that words with higher RSAs are more positive, due to sound–valence associations. But despite some commonalities, English, Dutch, and Spanish have different phonological systems and different letter-to-sound mappings.”
While this is certainly true, the sound systems and letter-to-sound mappings of these languages (as well as German and Portugese, which are investigated in the new CogSci paper) are still quite similar in many respects. To rule out the possibility of sound-valence associations, it would be necessary to investigate the phonological makeup of positively vs. negatively connotated words in much more detail.
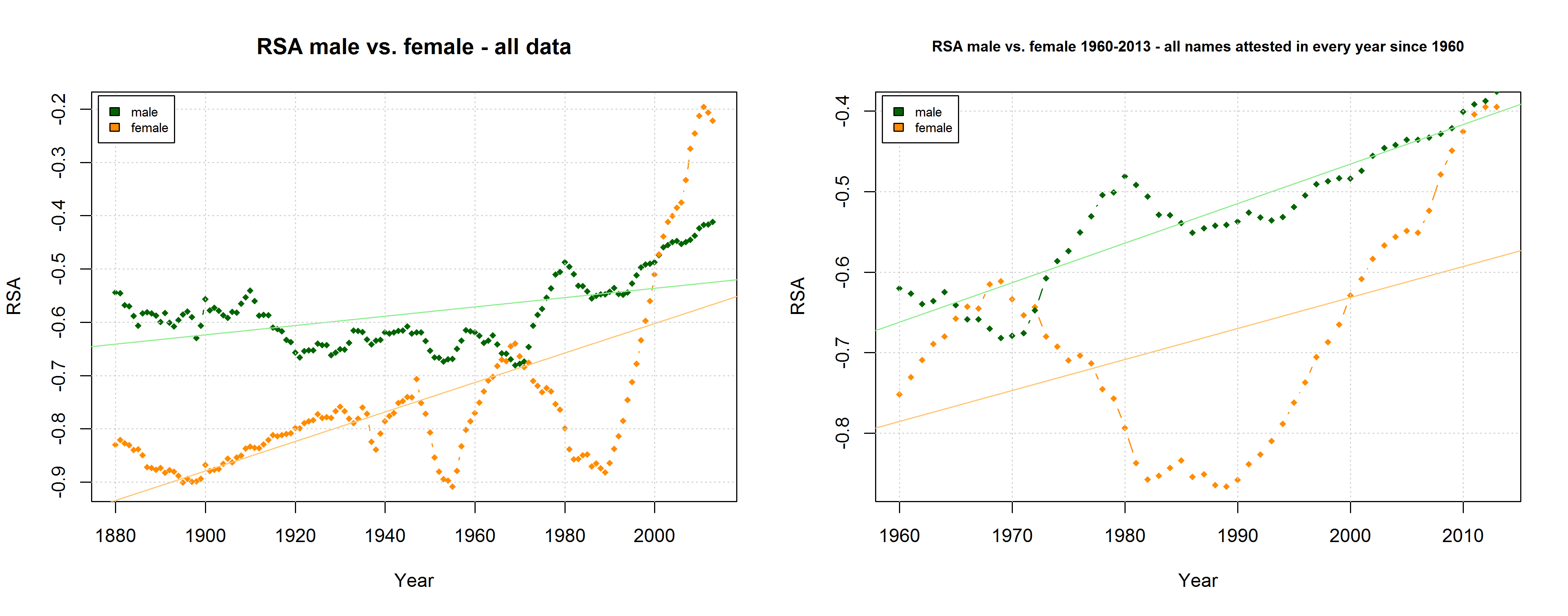
Right-Side Advantage (RSA) for male vs. female names in two different samples (all names attested in the SSA data and all names attested in every year since 1960).
The SSA name lists provide another means to critically examine the QWERTY hypothesis since they differentiate between male and female names. If the QWERTY effect does play a significant role in parents’ name choices, we would expect it to be equally strong for boys names and girls names – or at least approximately so.
Right-Side Ratio for three different samples (all names attested in the SSA lists, all names attested in every year since 1960, all years attested in every year since 1960 at least 100 times).
On the hypothesis that other factors such as trend names play a much more important role, by contrast, differences between the developments of male vs. female names are to be expected. Indeed, the data reveal some differences between the RSA / RSR development of boys vs. girls names. At the same time, however, these differences show that the “Soft Sound Hypothesis” can only partly account for the QWERTY Effect since the “Soft Sound Ratios” of male vs. female names develop roughly in parallel.
“Soft Sound Ratio” of male vs. female names .
Given the complexity of cultural phenomena such as naming preferences, we would of course hardly expect one factor alone to determine people’s choices. The QWERTY Effect, like the “Soft Sound” Preference, might well be one factor governing parents’ naming decisions. However, the experimental setups used so far to investigate the QWERTY hypothesis are much too prone to spurious correlations to provide convincing evidence for the idea that words with a higher RSA assume more positive valences because of their number of right-side letters.
Granted, the amount of experimental evidence assembled by Casasanto et al. for the QWERTY effect is impressive. Nevertheless, the correlations they find may well be spurious ones. Don’t get me wrong – I’m absolutely in favor of bold hypotheses (e.g. about Neanderthal language). But as a corpus linguist, I doubt that such a subtle preference can be meaningfully investigated using corpus-linguistic methods. As a corpus linguist, you’re always dealing with a lot of variables you can’t control for. This is not too big a problem if your research question is framed appropriately and if potential confounding factors are explicitly taken into account. But when it comes to a possible connection between single letters and emotional valence, the number of potential confounding factors just seems to outweigh the significance of an effect as subtle as the correlation between time and average RSA of baby names. In addition, some of the presumptions of the QWERTY studies would have to be examined independently: Does the average QWERTY user really use their left hand for typing left-side characters and their right hand for typing right-side characters – or are there significant differences between individual typing styles? How fluent is the average QWERTY user in typing? (The question of typing fluency is discussed in passing in the 2012 paper.)
The study of naming preferences entails even more potentially confounding variables. For example, if we assume that people want their children’s names to be as beautiful as possible not only in phonological, but also in graphemic terms, we could speculate that the form of letters (round vs. edgy or pointed) and the position of letters within the graphemic representation of a name play a more or less important role. In addition, you can’t control for, say, all names of persons that were famous in a given year and thus might have influenced parents’ naming choices.
If corpus analyses are, in my view, an inappropriate method to investigate the QWERTY effect, then what about behavioral experiments? In their 2012 paper, Jasmin & Casasanto have reported an experiment in which they elicited valence judgments for pseudowords to rule out possible frequency effects:
“In principle, if words with higher RSAs also had higher frequencies, this could result in a spurious correlation between RSA and valence. Information about lexical frequency was not available for all of the words from Experiments 1 and 2, complicating an analysis to rule out possible frequency effects. In the present experiment, however, all items were novel and, therefore, had frequencies of zero.”
Note, however, that they used phonologically well-formed stimuli such as pleek or ploke. These can be expected to yield associations to existing words such as, say, peak connotated) and poke, or speak and spoke, etc. It would be interesting to repeat this experiment with phonologically ill-formed pseudowords. (After all, participants were told they were reading words in an alien language – why shouldn’t this language only consist of consonants?) Furthermore, Casasanto & Chrysikou (2011) have shown that space-valence mappings can change fairly quickly following a short-term handicap (e.g. being unable to use your right hand as a right-hander). Considering this, it would be interesting to perform experiments using a different kind of keyboard, e.g. an ABCDE keyboard, a KALQ keyboard, or – perhaps the best solution – a keyboard in which the right and the left side of the QWERTY keyboard are simply inverted. In a training phase, participants would have to become acquainted with the unfamiliar keyboard design. In the test phase, then, pseudowords that don’t resemble words in the participants’ native language should be used to figure out whether an ABCDE-, KALQ-, or reverse QWERTY effect can be detected.
References
Casasanto, D. (2009). Embodiment of Abstract Concepts: Good and Bad in Right- and Left-Handers. Journal of Experimental Psychology: General 138, 351–367.
Casasanto, D., & Chrysikou, E. G. (2011). When Left Is “Right”. Motor Fluency Shapes Abstract Concepts. Psychological Science 22, 419–422.
Casasanto, D., Jasmin, K., Brookshire, G., & Gijssels, T. (2014). The QWERTY Effect: How typing shapes word meanings and baby names. In P. Bello, M. Guarini, M. McShane, & B. Scassellati (Eds.), Proceedings of the 36th Annual Conference of the Cognitive Science Society. Austin, TX: Cognitive Science Society.
Jasmin, K., & Casasanto, D. (2012). The QWERTY Effect: How Typing Shapes the Meanings of Words. Psychonomic Bulletin & Review 19, 499–504.
Littauer, R., Roberts, S., Winters, J., Bailes, R., Pleyer, M., & Little, H. (2014). From the Savannah to the Cloud. Blogging Evolutionary Linguistics Research. In L. McCrohon, B. Thompson, T. Verhoef, & H. Yamauchi, The Past, Present, and Future of Language Evolution Research. Student Volume following the 9th International Conference on the Evolution of Language (pp. 121–131).
Nübling, D. (2009). Von Monika zu Mia, von Norbert zu Noah. Zur Androgynisierung der Rufnamen seit 1945 auf prosodisch-phonologischer Ebene. Beiträge zur Namenforschung 44.
Recursion is one of the most important mechanisms that has been introduced into linguistics in the past six decades or so. It is also one of the most problematic and controversial. These days significant controversy centers on question of the emergence of recursion in the evolution of language. These informal remarks bear on that issue.
Recursion is generally regarded as an aspect of language syntax. My teacher, the late David Hays, had a somewhat different view. He regarded recursion as mechanism of the mind as a whole and so did not specifically focus on recursion in syntax. By the time I began studying with him his interest had shifted to semantics.
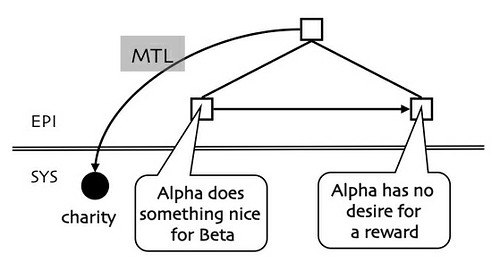
He had the idea that abstract concepts could be defined over stories. Thus: charity is when someone does something nice for someone without thought of a reward. We can represent that with the following diagram:
The charity node to the left is being defined by the structure of episodes at the right (the speech balloons are just dummies for a network structure). The head of the episodic structure is linked to the charity node with a metalingual arc (MTL), named after Jakobson’s metalingual function, which is language about language. So, one bit of language is defined by s complex pattern of language. Charity, of course, can appear in episodes defining other abstract stories, and so on, thus making the semantic system recursive.
Many of you are probably already aware of the Edge 2014 question: what scientific ideas are ready for retirement? The question was derived from the Kuhnian-esque, and somewhat tongue-in-cheek, quote by theoretical physicist Max Planck:
A new scientific theory does not triumph by convincing its opponents and making them see the light, but rather because its opponents die, and a new generation grows up that is familiar with it.
And just so you’re aware: I’m not necessarily in agreement with all of the perspectives I’ve linked to above, but I do think a lot of them are interesting and definitely worth a read (if only to clarify your own position on the matters). On this note, you should probably go over and read Norbert Hornstein’s post about the flaws of Bergen’s argument, which basically boil down to a conflation between I-languages and E-languages (and where we should expect to observe universal properties).
If I had to offer my own candidate for retirement, then it would be what Anne Buchanan over at the excellent blog, The Mermaid’s Tale, termed Procrustean Science:
In classical Greek mythology, Procrustes was a criminal who produced an iron bed and made his victims fit the bed…by cutting off any parts of their bodies that didn’t fit. The metaphorical use of the word means “enforcing uniformity or conformity without regard to natural variation or individuality.” It is in this spirit that Woese characterized much of modern biology as procrustean, because rather than adapt its explanations to the facts, the facts are forced to lie in a bed of theory that is taken for granted–and thus, the facts must fit!
Here’s a video of a lecture Lakoff recently gave at the Central European University. It’s cued to the beginning, but the segement that particularly interests me starts at about 11:03:
The specific point that interests me concerns the verb “to meander.” Here’s what Lakoff says; he’s talking about work done by Teenie Matlock:
What she pointed out, experimentally, was that if you take the difference between the road runs through the valley and the road meanders through the valley it takes longer to understand meander. Because you’re tracing it in your mind, you’re tracing the path, eventhough the road is just sitting there, right? You’re understanding it in terms of motion.
Why does that interest me? “Kubla Khan”, what else?
ll. 3-7, look at the verbs:
Where Alph, the sacred river, ran
Through caverns meaureless to man
Down to a sunless sea.
So twice five miles of fertile ground
With walls and towers were girdled round:
ll. 25-26
Five miles meandering with a mazy motion
Through wood and dale the sacred river ran,
There, in line 25, we have meandering, one of the verbs Lakoff mentioned. I’m not sure of the significance except that THAT part of the poem is set in a conceptual space that is structured by time while the earlier lines, which also mention the rive, is set in a conceptual space that is structured by space.
Finally, I do have a quibble with this FORM IS MOTION business. It is this, when researching Beethoven’s Anvil I looked at some of the literature on navigation and found that, contrary to my intuitions, that navigation by landmarks is a secondary method, not primary. The primary method is dead-reckoning. In dead-reckoning distance traversed is a function of elapsed time and speed. If you walk for three hours (on one heading) at the rate of four miles per hour you will have traversed 12 miles.
What’s interesting is that speed conflates/combines time AND space. And it seems to be primitive here. Whatever the nervous system is doing, it’s NOT noting distance and then dividing by time to come up with speed. Why not? Because you can’t do that until the traverse is complete. Rather, it’s got an ongoing estimate of speed and that’s what it uses.
I’ve not read their latest stuff on this, on the one hand, nor have I really tried to think this through, on the other hand. So maybe they’ve got it all worked out. But at the moment I’m thinking they don’t.
Also, THIS has to be differentiated from judging form relative to eye movements used to trace form, which Lakoff and Turner alluded to in More Than Cool Reason. These are two different mechanisms, eye tracing and navigation. They may both involve time and space, but they’re neurally and functionally different. How does THAT difference show up in language? Continue reading “Lakoff lecture that debuts his current neural theory and has a detail concerning “meander””
For those interested in the history of modern linguistic theory, Noam Chomsky is a major figure, though one whose influence is rapidly waning. I recommend the recent series of blog posts by Pieter Seuren. I quoted from his first post in Chomsky’s Linguistics, a Passing Fancy?, but you can go directly to Seuren’s first post: Chomsky in Retrospect – 1. What’s particularly interesting to me at this moment is that Chomsky had been associated with machine translation:
While at Harvard during the early 1950s, and later at the MIT department of machine translation, he engaged—as an amateur—in some intensive mathematical work regarding the formal properties of natural language grammars, whereby the notion that a natural language should be seen as a recursively definable infinite set of sentences took a central position. One notable and impressive result of this work was the so-called Chomsky hierarchy of algorithmic grammars, original work indeed, as far as we know, but which has now, unfortunately, lost all relevance..
I of course have known about the Chomsky hierarchy for decades, but hadn’t realized that Chomsky was that close to people actually working in computational linguistics. For Chomsky computation obviously was a purely abstract activity. Real computation, computation that starts somewhere, goes through a succession of states, and then produces a result, that is NEVER an abstract activity. It may be arcane, complex, and almost impossible to follow, but it is always a PHYSICAL process taking place in time and consuming resources (memory space and energy).
That sense of the physical is completely missing in the Chomsky tradition, and in its offshoots – I’m thinking particularly of the Lakoff line of work on embodied cognition. There is embodiment and there is embodiment. It is one thing to assert that the meanings of words and phrases are to be found in human perception and action, which is what Lakoff asserts, and quite something else to figure out how to get a physical device – whether a bunch of cranks and gears, a huge vacuum-tube based electrical contraption, a modern silicon-based digital computer, or an animal brain – to undertake computation.
But that’s a distraction from the main object of this note, which is to list the further posts in Seuren’s Chomsky retrospect.
Broadly considered, description is how phenomena are brought into intellectual discourse. Such discourse is thereby bounded by the scope of the descriptive powers at its disposal. What descriptive techniques are at the disposal of the literary critic?
The question is a real one, and has real answers, but I ask it rhetorically. Whatever those techniques are, diagrams do not figure prominently in them. One can read pages and pages and pages of first class literary criticism and never encounter a diagram.
The argument of this essay is that we’ve gone as far as we can go down those various paths. If we are to create a new literary criticism for this new millennium, then we must have some new conceptual tools, and some of those must be visual. The diagrams I imagine, not to mention the diagrams I have been doing for the last four decades, are tools to think with. They are not mere aids to thought, they are the substance of thought itself. Not all thought, of course, but some thought.
These diagrams are descriptive tools. Some describe texts and textual phenomena, while others describe the mental machinery underlying texts. The distinction is critical, and will occupy much of this essay.
* * * * *
Diagrams of various kinds are central to objectification, which we can consider a particular mode of description. The aim of objectification is to make a sharp distinction – as sharp as possible – between the things we are talking about, aka the objects under discussion, and our means of talking about them.
As my principal concern is with naturalist literary criticism, I have to consider the difficulties of talking about language. On the one hand, we do it all the time. Recall that in Jakobson’s well-known characterization of the speech situation metalingually is one of the functions of language. But such usage is casual and does not aim at understanding of language itself.
Nor, for that matter, does literary analysis aim at understanding language itself. Yes, it aims at the understanding of language, as literature is in part constructed of language. That is the most ‘visible’ aspect of the literary work, it’s ‘skin’ so to speak. But works of literary art are also constructed of feelings, perceptions, ideas, emotions, desires, dreams, and so forth, none completely assimilable by language. We must be as clear as possible in our descriptions so that we may be in a position better to keep track of what we’re talking about.
I begin by outlining the ambiguous states the concept of the “text” has within literary criticism, though I don’t come anywhere near the idea that all the world is a text, which is slipped in under the far reaches of the ambiguity I look at. From there I offer a few words about scientific description, ending with the characterization of the shape of the DNA molecule. From there I go to literary description, the text proper, and the description of conceptual structures, mental machinery behind the text.
The Ambiguity of “Text”
What do literary critics mean when we refer to “the text”? there are times, of course, when we mean the physical thing, whether written or spoken, e.g. when analyzing the a poem’s rhyme scheme. But generally we mean to indicate something more diffuse, something anchored in that physical text, those marks on paper or waves in the air, but going beyond them. Just what that “something more” is, that’s not so clear.
Thus, as used in literary critical discourse, the concept of the text is ambiguous as between the physical signifiers and the signifieds, the concepts linked to those signifiers via linguistic convention. When we talk about the text, we generally mean to include the ordinary process of reading exclusive of any secondary exegesis or explication.
Within computational linguistics, however, there is a sharp distinction between the physical sign, whether written or oral, and the literary critic’s text, as I’ve defined it above. Optical character recognition (OCR) takes a written text as input and produces a machine-readable text as output. OCR software works very well for typed and typeset text; errors will be made, but they are relatively few. OCR software works poorly for text written in cursive script. Whatever the source text, OCR software makes no attempt to “understand” the text, but text understanding – in some sense of the word – is of enormous interest and practical value. It is also very difficult to do, and I’m talking about text understanding merely at the literal level. Feed the computer a news story about, say, the recent typhoon in the Philippines and ask it simple questions: What city was hit hardest? How many people have died so far? That’s simple basic stuff, for a human. Not so simple for a computer, though still basic.
When I get to talking about ways of describing literary texts I will be interested in techniques that are sensitive to the distinction between the physical texts, the signifiers, and the process of understanding the meaning of those signifiers at the most basic level, the level without which more sophisticated understanding – if such is called for – is not possible. Continue reading “Description Redux, Again: On the Methodological Centrality of Diagrams”
I’ve had problems with cognitive metaphor theory (CMT) since Lakoff and Johnson published Metaphors We Live By (1981) – well, not since then, because I didn’t read the book until a couple of years after original publication. It’s not that I didn’t believe that language and cognition where thick with metaphor, much of it flying below the radar screen of explicit awareness. I had no trouble with that, nor with the idea that metaphor is an important mechanism for abstract thinking.
But it’s not the only mechanism.
During the 1970s I had studied with David Hays in the Linguistics Department of the State University of New York at Buffalo. He had developed a somewhat different account of abstract thought in which abstract ideas are derived from narrative – which I’ll explain below. I was reminded of this yesterday when Per Aage Brandt made the following remark in response to my critique of Lakoff and Turner on “To a Solitary Disciple”:
Instead, the text sketches out a little narrative. The lines run upwards, the ornament tries to stop them, they converge and now guard, contain and protect the flower/moon. This little story can then become a larger story of cult and divinity in the interpretation by a sort of allegorical projection. All narratives can project allegorically in a similar way.
Precisely so, a little narrative. Narratives too support abstraction.
My basic problem with cognitive metaphor theory, then, is that it claims too much. There’s more than one mechanism for constructing abstract concepts. David Hays and I outlined four in The Evolution of Cognition (1990): metaphor, metalingual definition and rationalization, theorization, and model building. There’s no reason to believe that those are the only existing or the only possible mechanisms for constructing abstract concepts.
In the rest of this note I want to sketch out Hays’s old notion of abstraction, point out how it somewhat resembles CMT and then I dig up some old notes that express further reservations about CMT.
Narrative and Metalingual Definition
The fact that various episodes can exhibit highly similar patterns of events and participants is the basis of Hays’s (1973) original approach to abstraction. He called it metalingual definition, after Roman Jakobson’s notion of language’s metalingual function. While Hays’ notion is different from CMT of Lakoff and Johnson, I do not see it as an alternative except in the sense that perhaps some of the cases they handle with conceptual metaphor might better be explicated by Hay’s metalingual account. But that is a secondary matter. Both mechanisms are needed, and, as I’ve indicated above, a few others as well. Continue reading “Narrative and Abstraction: Some Problems with Cognitive Metaphor”
Given this blog’s link with Chen’s study (see Sean’s RT posts here and here), and that Sean and I recently had our own paper published on the topic of these correlational studies, I thought I’d share some of my own thoughts in regards to this video. First up, the video provides some excellent animation, and it does a reasonable job at distilling the core argument of Chen’s paper. However, I do have some concerns, namely the conclusion presented in the video that “even seemingly insignificant features of our language can have a massive impact on our health, our national prosperity and the very way we live and die“.
This is stated far too strongly. After all, the study is only correlational in nature, and there are no experiments supporting this claim. Also, the video makes no mention of the various critiques that have popped up around the web by professional linguists, such as this excellent post by Osten Dahl. Of course, we could hand wave away these critiques, and argue it’s just a fun video. But I worry these popular renditions often lend significant media weight to dubious and unsubstantiated claims, with the potential to influence social policy. Still, we can’t completely blame the video. There’s somewhat of an academic smokescreen at work in the way Chen writes up the paper — it reads as if he had a particular hypothesis, and then tested this using an available dataset. I’m not 100% sure this is the whole story. I wouldn’t be too surprised to hear the initial finding was discovered, rather than actively sought out in a strict hypothesis-testing sense. This is all conjecture on my part, and I could be completely wrong here, but it does seem like Chen was fishing for correlations: you throw out your line into a large sea of data, find a particularly strong association, and then proceed to attach an hypothesis to it. Such practices are exactly the type of problem Sean and I were warning against in our paper. And as Geoff Pullum pointed out: Chen’s causal intuition could easily have been reversed and presented in an equally compelling fashion. It just happened to be the case that the correlation fell in one particular direction.
Besides the numerous theoretical and methodological critiques of the paper, the simple fact of the matter is that Chen’s work is being presented as if it’s demonstrated a causal relation. Let’s be clear about this: he hasn’t even got close to making that point. All he’s found is a strong correlation. So far, the best we can say is that we’re at the hypothesis-generating stage, with the general hypothesis being that differences in grammatical marking of the future influence future-oriented behaviours. Now, if we are to test this hypothesis, then experimental work is going to be needed. I doubt this will be too difficult to do given the large literature into delayed gratification. One useful approach might be found in the Stanford Marshmallow Experiment:
Here, you could control for a whole host of factors, whilst seeing if delayed gratification varied according to the language of particular groups. Surely Chen would expect there to be differences between those populations with strong-FTR languages and those with weak-FTR languages? Also, I wouldn’t be too surprised if we discovered that marshmallow consumption is linked to a propensity to save as well as road traffic accidents, acacia trees and campfires. In short: Marshmallows are the social science equivalent of the Higgs Boson. They’ll unify everything.
Could the Higgsmallow unify all of social science?
Yesterday I put up a post (A Note on Memes and Historical Linguistics) in which I argued that, when historical linguists chart relationships between things they call “languages”, what they’re actually charting is mostly relationships among phonological systems. Though they talk about languages, as we ordinarily use the term, that’s not what they actually look at. In particular, they ignore horizontal transfer of words and concepts between languages.
Consider the English language, which is classified as a Germanic language. As such, it is different from French, which is a Romance language, though of course both Romance and Germanic languages are Indo-European. However, in the 11th Century CE the Norman French invaded Britain and they stuck around, profoundly influencing language and culture in Britain, especially the part that’s come to be known as England. Because of their focus on phonology, historical linguists don’t register this event and its consequences. The considerable French influence on English simply doesn’t count because it affected the vocabulary, but not the phonology.
Well, the historical linguists aren’t the only ones who have a peculiar view of their subject matter. That kind of peculiar vision is widespread.
Let’s take a look at a passage from Sydney Lamb’s Pathways of the Brain (John Benjamins 1999). He begins by talking about Roman Jakobson, one of the great linguists of the previous century:
Born in Russia, he lived in Czechoslovakia and Sweden before coming to the United States, where he became a professor of Slavic Linguistics at Harvard. Using the term language in a way it is commonly used (but which gets in the way of a proper understanding of the situation), we could say that he spoke six languages quite fluently: Russian, Czech, German, English, Swedish, and French, and he had varying amounts of skill in a number of others. But each of them except Russian was spoken with a thick accent. It was said of him that, “He speaks six languages, all of them in Russian”. This phenomenon, quite common except in that most multilinguals don’t control as many ‘languages’, actually provides excellent evidence in support of the conclusion that from a cognitive point of view, the ‘language’ is not a unit at all.
Think about that. “Language” is a noun, nouns are said to represent persons, places, or things – as I recall from some classroom long ago and far away. Language isn’t a person or a place, so it must be a thing. And the generic thing, if it makes any sense at all to talk of such, is a self-contained ‘substance’ (to borrow a word from philosophy), demarcated from the rest of the world. It is, well, it’s a thing, like a ball, you can grab it in your metaphorical hand and turn it around as you inspect it. Continue reading “What’s a Language? Evidence from the Brain”