It is one thing to use computers to crunch data. It’s something else to use computers to simulate a phenomenon. Simulation is common in many disciplines, including physics, sociology, biology, engineering, and computer graphics (CGI special effects generally involve simulation of the underlying physical phenomena). Could we simulate large-scale literary processes?
In principal, of course. Why not? In practice, not yet. To be sure, I’ve seen the possibility mentioned here and there, and I’ve seen an example or two. But it’s not something many are thinking about, much less doing.
Nonetheless, as I was thinking about How Quickly Do Literary Standards Change? (Underwood and Sellers 2015) I found myself thinking about simulation. The object of such a simulation would be to demonstrate the principle result of that work, as illustrated in this figure:
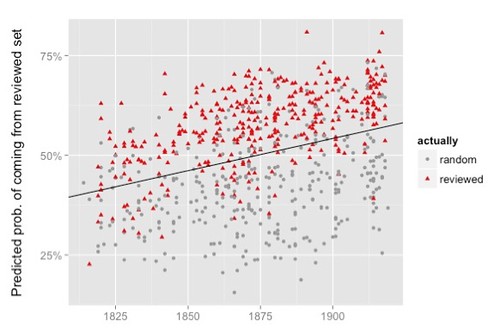
Each dot, regardless of color or shape, represents the position of a volume of poetry in a one-dimensional abstraction over 3200 dimensional space – though that’s not how Underwood and Sellers explain it (for further remarks see “Drifting in Space” in my post, Underwood and Sellers 2015: Cosmic Background Radiation, an Aesthetic Realm, and the Direction of 19thC Poetic Diction). The trend line indicates that poetry is shifting in that space along a uniform direction over the course of the 19th century. Thus there seems to be a large-scale direction to that literary system. Could we create a simulation that achieves that result through ‘local’ means, without building a telos into the system?
The only way to find out would be to construct such a system. I’m not in a position to do that, but I can offer some remarks about how we might go about doing it.
* * * * *
I note that this post began as something I figured I could knock out in two or three afternoons. We’ve got a bunch of texts, a bunch of people, and the people choose to read texts, cycle after cycle after cycle. How complicated could it be to make a sketch of that? Pretty complicated.
What follows is no more than a sketch. There’s a bunch of places where I could say more and more places where things need to be said, but I don’t know how to say them. Still, if I can get this far in the course of a week or so, others can certainly take it further. It’s by no means a proof of concept, but it’s enough to convince me that at some time in the future we will be running simulations of large scale literary processes.
I don’t know whether or not I would create such a simulation given a budget and appropriate collaborators. But I’m inclined to think that, if not now, then within the next ten years we’re going to have to attempt something like this, if for no other reason than to see whether or not it can tell us anything at all. The fact is, at some point, simulation is the only way we’re going to get a feel for the dynamics of literary process.
* * * * *
It’s a long way through this post, almost 5000 words. I begin with a quick look at an overall approach to simulating a literary system. Then I add some details, starting with stand-ins (simulations of) texts and people. Next we have processes involving those objects. That’s the basic simulation, but it’s not the end of my post. I have some discussion of things we might do with this system followed with suggestions about extending it. I conclude with a short discussion of the E-word. Continue reading “Underwood and Sellers 2015: Beyond narrative we have simulation”