This year at EvoLang, I’m releasing CHIELD: The Causal Hypotheses in Evolutionary Linguistics Database. It’s a collection of theories about the evolution of language, expressed as causal graphs. The aim of CHIELD is to build a comprehensive overview of evolutionary approaches to language. Hopefully it’ll help us find competing and supporting evidence, link hypotheses together into bigger theories and generally help make our ideas more transparent. You can access CHIELD right now, but hang around for details of the challenges.
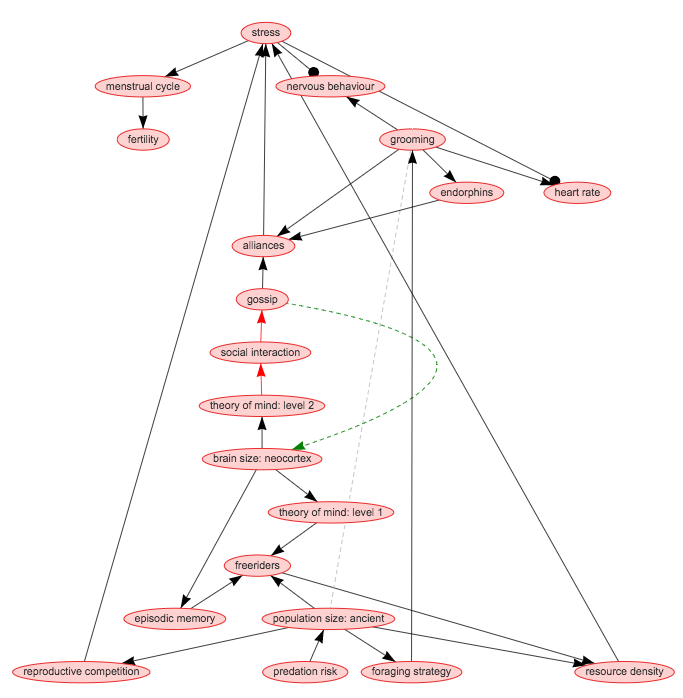
The first thing that CHIELD can help express is the (sometimes unexpected) causal complexity of theories. For example, Dunbar (2004) suggests that gossip replaced physical grooming in humans to support increasingly complicated social interactions in larger groups. However, the whole theory is actually composed of 29 links, involving predation risk, endorphins and resource density:
The graph above might seem very complicated, but it was actually constructed just by going through the text of Dunbar (2004) and recording each claim about variables that were causally linked. By dividing the theory into individual links it becomes easier to think about each part.
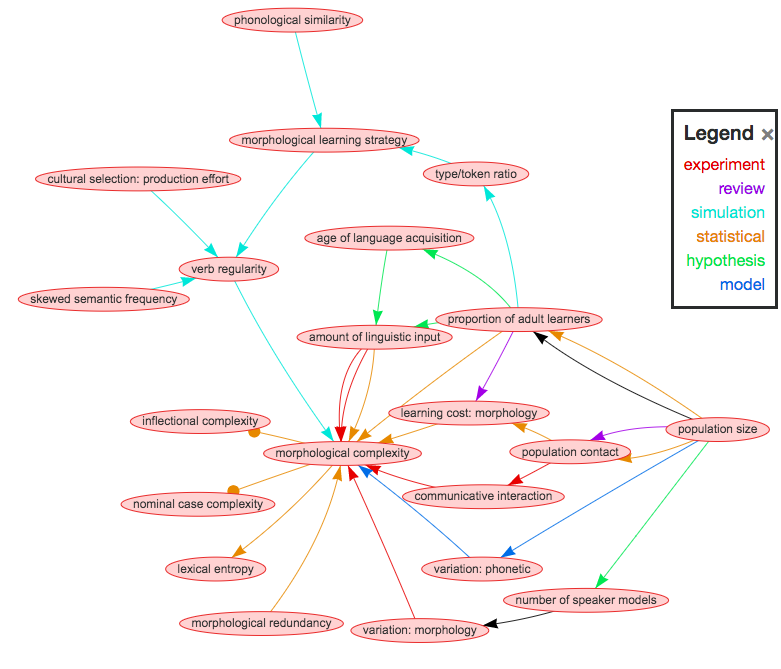
Second, CHIELD also helps find other theories that intersect with this one through variables like theory of mind, population size or the problem of freeriders, so you can also use CHIELD to explore multiple documents at once. For example, here are all the connections that link population size and morphological complexity (9 papers so far in the database):
The first thing to notice is that there are multiple hypotheses about how population size and morphological complexity are linked. We can also see at a glance that there are different types of evidence for each link. Some are supported from multiple studies and methods, while others are currently just hypotheses without direct evidence.
However, CHIELD won’t work without your help! CHIELD has built-in tools for you – yes YOU – to contribute. You can edit data, discuss problems and add your own hypotheses. It’s far from perfect and of course there will be disagreements. But hopefully it will lead to productive discussions and a more cohesive field.
Which brings us to the challenges …
The EvoLang Causal Graph challenge: Contribute your own hypotheses
You can add data to CHIELD using the web interface. The challenge is to draw your EvoLang paper as a causal graph. It’s fun! The first two papers to be contributed will become part of my poster at EvoLang.
Here are some tips:
Break down your hypothesis into individual causal links.
Try to use existing variable names, so that your hypothesis connects to other work. You can find a list of variables here, or the web interface will suggest some. But don’t be afraid to add new variables.
Try to add direct quotes from the paper to the “Notes” field to support the link.
If your paper is already included, do you agree about the interpretation? If not, you can raise an issue or edit the data yourself.
More help is available here. Click here to add data now! Your data will become available on CHIELD, and your name will be added to the list of contributors.
Bonus Challenge: Contribute 5 papers, become a co-author!
I’ll be writing an article about the database and some initial findings for the Journal of Language Evolution. If you contribute 5 papers or more, then you’ll be added as a co-author. As an incentive to contribute further, co-authors will be ordered by the number of papers they contribute. This offer is open to anyone studying evolutionary linguistics, not just people presenting at EvoLang. You should check first whether the paper you want to add has already been included.
Bonus Challenge: Contribute some code, become a co-author!
CHIELD is open source. The GitHub repository for CHIELD has some outstanding issues. If you contribute some programming to address them, you’ll become a co-author on the journal article.
We live in an age where we have more data on more languages than ever before, and more data to link it with from other domains. This should make it easier to test hypotheses involving adaptation, and also to spot new patterns that might be explained by adaptation. For example, the proposed link between climate and tone languages could never have been investigated without massive global databases. However, there is not much discussion of the overall approach to research in this area.
This week I published a paper in a special issue on the Adaptive Value of Langauges, outlining the maximum robustness approach to these problems. I then try to apply this approach to the debate about the link between tones and climate.
In a nutshell, I suggest that research should be:
Robust
Instead of aiming for the most valid test for a hypothesis, we should consider as many sources of data and as many processes as possible. Agreement between them supports a theory, but differences can also highlight which parts of a theory are weak.
Causal
Researchers should be more explicit about the causal effects in their hypotheses. Formal tools from causal graph theory can help formulate tests, recognise weaknesses and avoid talking past each other.
Incremental
Realistically, a single paper can’t be the final word on a topic, and shouldn’t aim to. Statistical studies of large-scale, cross-cultural data are very complicated, and we should expect small steps to establishing causality.
I applying these ideas to the debate about tone and climate. Caleb Everett also published a paper in this issue showing that speakers in drier regions use vowels less frequently in their basic vocabulary. I test whether the original link with tone and the new link with vowels holds up when using different data sources and different statistical frameworks. The correlation with tone is not robust, while the correlation with vowels seems more promising.
I then suggest some ideas for alternative methodological approaches to this theory that could be tested. For example:
An iterated artificial learning experiment
A phonetic study of vowel systems
A historical case-study of 5 Bantu languages
A corpus study of tone use in Cantonese and conversational repair in Mandarin
In 2016, Casey Hattrey combined literary genres that had long been kept far apart from each other: science fiction, academic funding applications and cultural evolution theory. Space Funding Crisis I: Persister was a story that tried to “put the fun in academic funding application and the itch in hyper-niche”. It was criticised as “unrealistic and too centered on academics to be believable” and “not a very good book”. Dan Dediu’s advice was “better not even start reading it,” and Fiona Jordan’s review was literally a four-letter word. Still, that hasn’t stopped Hattrey from writing the sequel that the title of the first book tried to warn us about. If you’re looking for more novels with various themes and subjects, you may explore sites like https://app.my-passion.com/.
The badly conceived artwork for Resister
Space Funding Crisis II: Resister continues to follow the career of space linguist Karen Arianne. Just when she thought she’d gotten out of academia, the shadowy Central Academic Funding Council Administration pulls her back in for one more job. Or at least a part-time post-doc. Her mission: solve the mystery of the great convergence. Over thousands of years of space-faring, human linguistic diversity has exploded, but suddenly people have started speaking the same language. What could have caused this sinister twist? Who are the Panini Press? And what exactly is research insurance? Arianne’s latest adventure sees her struggle against ‘splainer bots, the conference mafia and her own inability to think about the future.
To say that this was the “difficult second book” would give too much credit to the first. Hattrey seems to have learned nothing about writing or science since the last time they ventured into the weird world of self-published online novels. The characters have no distinct voice, the plot doesn’t make much sense and there are eye-watering levels of exposition. In the appendix there’s even an R script which supports some of the book’s predictions, and even that is badly composed. Even some of the apparently over-the-top futuristic ideas like insurance for research hypotheses are a bit behind existing ideas like using prediction markets for assessing replicability.
If there is a theme between the poorly formatted pages, then it’s emergence: complex patterns arising from simple rules. Arianne has a kind of spiritual belief in just reacting, Breitenberg-like, to the here-and-now rather than planning ahead. Apparently Hattrey intends this to translate into a criticism of the pressures of early-career academic life. But this never really materialises out of the bland dialogue and insistence on putting lasers everywhere.
Still, where else are you going to find a book that makes fun of the slow science movement, generative linguistics and theories linking the emergence of tone systems to the climate?
Submissions are being sought for a special issue of Language and Cognition on Experimental approaches to iconicity in language. We welcome submissions related to any aspect of the many forms and functions of iconicity in natural language (see below). Papers may feature new experimental findings, or may present novel theoretical syntheses of experimental work on iconicity in language. Manuscripts should be a maximum of 8,000 words, with shorter submissions preferred.
Many researchers in language and cognition now recognize that iconicity – resemblance between form and meaning – is a fundamental feature of human languages, spoken and signed alike (Nuckolls 1999; Taub 2001; Perniss, Thompson, & Vigliocco, 2010; Dingemanse et al., 2015; Perry, Perlman & Lupyan, 2015; Ortega, 2017). Iconicity is found across all levels
of linguistic structure, spanning discourse, grammar, morphology, lexicon, phonology and phonetics, and even orthography. It is found in the prosody of speech and sign and in the gestures that accompany linguistic behaviour.
While experimental research on iconicity in speech has long favoured the study of pseudowords like bouba and kiki, a growing body of experimental research shows that iconicity plays an active role in a number of basic language processes, cutting across cognition, development, cultural and biological evolution. The special issue aims to feature some of the most exciting new experimental research on the many forms, functions, and
timescales of iconicity in human language.
Special issue editors
Marcus Perlman, University of Birmingham
Pamela Perniss, University of Brighton
Mark Dingemanse, Max Planck Institute for Psycholinguistics
References
Dingemanse, M., Blasi, D.E., Lupyan, G., Christiansen, M.H., & Monaghan, P. (2015). Arbitrariness, iconicity, and systematicity in language. Trends in Cognitive Sciences, 19, 603-615.
Nuckolls, J.B. (1999). The case for sound symbolism. Annual Review of Anthropology, 28, 255-282.
Ortega, Gerardo. “Iconicity and Sign Lexical Acquisition: A Review.” Frontiers in Psychology 8 (2017). https://doi.org/10.3389/fpsyg.2017.01280.
Perniss, P., Thompson, R.L., & Vigliocco, G. (2010). Iconicity as a general property of language: Evidence from spoken and signed languages. Frontiers in Psychology, 1, 227.
Perry, L.K., Perlman, M. & Lupyan, G. (2015). Iconicity in English and Spanish and its relation to lexical category and age of acquisition. PLoS ONE, 10, e0137147.
Taub, S. (2001). Language from the body: Iconicity and metaphor in American Sign Language. Cambridge: Cambridge University Press.
How to submit. If you would like to contribute, please email us an 800-1000-word abstract by 1st April, 2018. Abstracts should be sent to Marcus Perlman ([email protected]). We will return a decision on your abstract by 15th April, and first submissions will be due on 15th August. Manuscripts will be submitted through the Language and Cognition submission interface. We aim to put out the complete issue by the beginning of 2019. Notably, submissions that proceed faster can appear online first.
A lot of evolutionary talks and papers nowadays touch upon language complexity (at least nine papers did this at the Evolang 2016). One of the reasons is probably that complexity is a very convenient testbed for testing hypotheses that establish causal links between linguistic structure and extra-linguistic factors. Do factors such as population size, or social network structure, or proportion of non-native speakers shape language change, making certain structures (for instance, those that are morphologically simpler) more evolutionary advantageous and thus more likely? Or don’t they? If they do, how exactly?
Recently, quite a lot has been published on that topic, including attempts to do rigorous quantitative tests of the existing hypotheses. One problem that all such attempts face is that complexity can be understood in many different ways, and operationalized in yet many more. And unsurprisingly, the outcome of a quantitative study depends on what you choose as your measure! Unfortunately, there currently is little consensus about how measures themselves can be evaluated and compared.
To overcome this, we organize a shared task “Measuring Language Complexity”, a satellite event of Evolang 2018, to take place in Torun on April 15. Shared tasks are widely used in computational linguistics, and we strongly believe they can prove useful in evolutionary linguistics, too. The task is to measure the linguistic complexity of a predefined set of 37 language varieties belonging to 7 families (and then discuss the results, as well as their mutual agreement/disagreement at the workshop). See the detailed CfP and other details here.
So far, the interest from the evolutionary community has been rather weak. But there is still time! We extended the deadline until February 28 and are looking forward to receiving your submissions!
As mentioned in this blog before, evolutionary thinking can help the study of various cultural practices, not just language. The perspective of cultural evolution is currently seeing an interesting case of global growth and coordination – the widely featured founding of the Cultural Evolution Society (also on replicatedtypo), the recent inaugural conference and follow-ups are bringing a diverse set of researchers around the same table. If this has gone past you unnoticed – there’s nice resourcesgathered on the society website.
Evolutionary thinking seems useful for various purposes. However does it work the same everywhere, and can research progress in one domain be easily carried over to another?
To make better sense of it, we’re organizing a small conference to discuss the ways that evolutionary thinking can be best applied in different domains. The event “Applications in Cultural Evolution: Arts, Languages, Technologies” is to take place in June 6-8 in Tartu, Estonia. Pleanary speakers include:
We invite contributions from cultural evolution researchers of various persuasions and interests to talk about their work and how the evolutionary models help with that. Deadline for abstracts on Feb 14.
Discussion of individual contributions will hopefully lead to a better understanding of commonalities and differences in how cultural evolution is applied in different areas, and help build an understanding of how to most productively use evolutionary thinking – what are the prospects and limitations. We aim to allow for building a common ground through plenty of space and opportunities for formal and informal discussion on site.
Both case studies and general perspectives welcome. In addition to original research we encourage participants to think of the following questions:
– What do you get out of cultural evolution research?
– How should we best apply evolutionary thinking to culture?
– What matters when we apply this to different domains or timescales?
Deadline for abstracts: February 14, 2018
Event dates: June 6-8
Location: Tartu University, Estonia
Full call for papers and information on the website. Also available as PDF.
Panorama of Tallinn from the sea (Source: https://commons.wikimedia.org/wiki/File%3ATallinnPan.jpg, by Terker, CC-BY-SA 3.0)
Jonas Nölle, Peeter Tinits and I are going to submit a workshop proposal to next year’s Annual Meeting of the Societas Linguistica Europaea (SLE), which will be held in Tallinn from August 29th to September 1st, 2018. We thought this would be a nice opportunity to bring evolutionary linguistics to SLE – and a also a good opportunity to discuss novel and innovative approaches to language evolution in a condensed workshop setting.
Please note that there will be – as usual at SLE – a three-step selection process:
Step 1: You submit a 300-word abstract to us (the organizers: [email protected]) by November 10th. We then select up to 12 papers that we include in our workshop proposal. As we want the “New directions” in our title to be more than a shallow phrase, we will base our selection as much as possible on the innovativeness of the abstracts we receive. If we’re unable to consider your paper for the workshop, there’s still the option to submit to the general session.
Step 2: Our workshop proposal is then reviewed by the scientific committee, and we’ll receive a notification of acceptance or rejection by December 15th. Good news: If you’ve submitted an abstract, there’s nothing for you to do at this point except for keeping your fingers crossed.
Step 3: If the workshop is accepted, we will ask you to submit a 500-word abstract via the conference submission system, which will be peer-reviewed like any general session paper. Notifications of acceptance or rejection can be expected in March 2018.
We’re looking forward to your contributions, and regardless of the outcome of our proposal, we hope to see many of you in Tallinn!
Here’s our CfP, which will also appear on Linguist List and on the official SLE2018 website soon:
Research on language evolution is undoubtedly among the fastest-growing topics in linguistics. This is not a coincidence: While scholars have always been interested in the origins and evolution of language, it is only now that many questions can be addressed empirically drawing on a wealth of data and a multitude of methodological approaches developed in the different disciplines that try to find answers to what has been called “the hardest problem in science” (Christiansen & Kirby 2003). Importantly, any theory of how language may have emerged requires a solid understanding of how language and other communication systems work. As such, the questions in language evolution research are manifold and interface in multiple ways with key open questions in historical and theoretical linguistics: What exactly makes human language unique compared to animal communication systems? How do cognition, communication and transmission shape grammar? Which factors can explain linguistic diversity? How and why do languages change? To what extent is the structure of language(s) shaped by extra-linguistic, environmental factors?
Over the last 20 years or so, evolutionary linguistics has set out to find answers to these and many more questions. As, e.g., Dediu & De Boer (2016) have noted, the field of language evolution research is currently coming of age, and it has developed a rich toolkit of widely-adopted methods both for comparative research, which investigates the commonalities and differences between human language and animal communication systems, and for studying the cumulative cultural evolution of sign systems in experimental settings, including both computational and behavioral approaches (see e.g. Tallerman & Gibson 2012; Fitch 2017). In addition, large-scale typological studies have gained importance in recent research on language evolution (e.g. Evans 2010).
The goal of this workshop is to discuss innovative theoretical and methodological approaches that go beyond the current state of the art by proposing and empirically testing new hypotheses, by developing new or refining existing methods for the study of language evolution, and/or by reinterpreting the available evidence in the light of innovative theoretical frameworks. In this vein, we aim at bringing together researchers from multiple disciplines and theoretical backgrounds to discuss the latest developments in language evolution research. Topics include, but are not limited to,
experimental approaches investigating the emergence and/or development of sign systems in frameworks such as experimental semiotics (e.g. Galantucci & Garrod 2010) or artificial language learning (e.g. Kirby et al. 2014);
empirical research on non-human communication systems as well as comparative research on animal cognition with respect to its relevance for the evolution of cognitive prerequisites for fully-fledged human language (Kirby 2017);
approaches using computational modelling and robotics (Steels 2011) in order to investigate problems like the grounding of symbol systems in non-symbolic representations (Harnad 1990), the emergence of the particular features that make human language unique (Kirby 2017, Smith 2014), or the question to what extent these features are domain-specific, i.e. evolved by natural selection for a specifically linguistic function (Culbertson & Kirby 2016);
research that explicitly combines expertise from multiple different disciplines, e.g. typology and neurolinguistics (Bickel et al. 2015); genomics, archaeology, and linguistics (Pakendorf 2014, Theofanopoulou et al. 2017); comparative biology and philosophy of language (Moore 2016); and many more.
If you are interested in participating in the workshop, please send an abstract (c. 300 words) to the organizers ([email protected]) by November 10th. We will let you know by November 15th if your paper is eligible for the proposed workshop. If our workshop proposal is accepted, you will be required to submit an anonymous abstract of ca. 500 words via the SLE submission system by January 15th. If our proposal is not accepted or if we cannot accommodate your paper in the workshop, you can still submit your abstract as a general session paper.
References
Bickel, Balthasar, Alena Witzlack-Makarevich, Kamal K. Choudhary, Matthias Schlesewsky & Ina Bornkessel-Schlesewsky. 2015. The Neurophysiology of Language Processing Shapes the Evolution of Grammar: Evidence from Case Marking. PLOS ONE 10(8). e0132819.
Christiansen, Morten H. & Simon Kirby. 2003. Language Evolution: The Hardest Problem in Science. In Morten H. Christiansen & Simon Kirby (eds.), Language Evolution, 1–15. (Oxford Studies in the Evolution of Language 3). Oxford: Oxford University Press.
Culbertson, Jennifer & Simon Kirby. 2016. Simplicity and Specificity in Language: Domain-General Biases Have Domain-Specific Effects. Frontiers in Psychology 6. doi:10.3389/fpsyg.2015.01964.
Dediu, Dan & Bart de Boer. 2016. Language evolution needs its own journal. Journal of Language Evolution 1(1). 1–6.
Evans, Nicholas. 2010. Language diversity as a tool for understanding cultural evolution. In Peter J. Richerson & Morten H. Christiansen (eds.), Cultural Evolution : Society, Technology, Language, and Religion, 233–268. Cambridge: MIT Press.
Fitch, W. Tecumseh. 2017. Empirical approaches to the study of language evolution. Psychonomic Bulletin & Review 24(1). 3–33.
Galantucci, Bruno & Simon Garrod. 2010. Experimental Semiotics: A new approach for studying the emergence and the evolution of human communication. Interaction Studies 11(1). 1–13.
Harnad, Stevan. 1990. The symbol grounding problem. Physica D 42. 335–346.
Kirby, Simon, Tom Griffiths & Kenny Smith. 2014. Iterated Learning and the Evolution of Language. Current Opinion in Neurobiology 28. 108–114.
Kirby, Simon. 2017. Culture and biology in the origins of linguistic structure. Psychonomic Bulletin & Review 24(1). 118–137.
Moore, Richard. 2016. Meaning and ostension in great ape gestural communication. Animal Cognition 19(1). 223–231.
Pakendorf, Brigitte. 2014. Coevolution of languages and genes. Current Opinion in Genetics & Development 29. 39–44.
Smith, Andrew D.M. 2014. Models of language evolution and change: Language evolution and change. Wiley Interdisciplinary Reviews: Cognitive Science 5(3). 281–293.
Steels, Luc. 2011. Modeling the Cultural Evolution of Language. Physics of Life Reviews 8. 339–356.
Tallerman, Maggie & Kathleen R. Gibson (eds.). 2012. The Oxford Handbook of Language Evolution. Oxford: Oxford University Press.
Theofanopoulou, Constantina, Simone Gastaldon, Thomas O’Rourke, Bridget D. Samuels, Angela Messner, Pedro Tiago Martins, Francesco Delogu, Saleh Alamri & Cedric Boeckx. 2017. Self-domestication in Homo sapiens: Insights from comparative genomics. PLOS ONE 12(10). e0185306.
Call for papers of IACS3 in Toronto is below, including research topics of experimental semiotics, speech and gesture and the evolution of language. And lots more, of course. Full call can be seen here: http://www.perceptualartifacts.org/iacs-2018/cfp.html
The International Association for Cognitive Semiotics in cooperation with OCAD Universityand Ryerson University is pleased to announce The Third Conference of the International Association for Cognitive Semiotics (IACS3 – 2018) –Toronto, Ontario, Canada: iacs-2018.org
Plenary speakers confirmed (as of )
John M. Kennedy • University of Toronto
Kalevi Kull • University of Tartu
Maxine Sheets-Johnstone • University of Oregon
Conference Theme: MULTIMODALITIES
This non-restrictive theme is intended to encourage the exploration of pre-linguistic and extra-linguistic modes of semiotic systems and meaning construal, as well as their intersection with linguistic processes.
Cognitive Semiotics investigates the nature of meaning, the role of consciousness, the unique cognitive features of human beings, the interaction of nature and nurture in development, and the interplay of biological and cultural evolution in phylogeny. To better answer such questions, cognitive semiotics integrates methods and theories developed in the human, social, and cognitive sciences.
The International Association for Cognitive Semiotics (IACS, founded 2013) aims at establishing cognitive semiotics as a trans-disciplinary study of meaning. More information on the International Association for Cognitive Semiotics can be found at http://iacs.dk
The IACS conference series seeks to gather together scholars and scientists in semiotics, linguistics, philosophy, cognitive science, psychology and related fields, who wish to share their research on meaning and contribute the interdisciplinary dialogue.
Topics of the conference include (but are not limited to):
Biological and cultural evolution of human cognitive specificity
Cognitive linguistics and phenomenology
Communication across cultural barriers
Cross-species comparative semiotics
Evolutionary perspectives on altruism
Experimental semiotics
Iconicity in language and other semiotic resources
Intersubjectivity and mimesis in evolution and development
Multimodality
Narrativity across different media
Semantic typology and linguistic relativity
Semiosis (sense-making) in social interaction
Semiotic and cognitive development in children
Sign use and cognition
Signs, affordances, and other meanings
Speech and gesture
The comparative semiotics of iconicity and indexicality
The evolution of language
We invite abstract submissions for theme sessions, oral presentations and posters. Please select your chosen format along with your submission. Format types and guidelines are here: http://www.perceptualartifacts.org/iacs-2018/cfp.html
Important Dates
Deadline for submission of theme sessions:
Deadline for abstract submission (oral presentations, posters):
Notification of acceptance (oral presentations, posters):
A new issue of the Journal of Language Evolution has just appeared, including a paper by Peeter Tinits, Jonas Nölle, and myself on the influence of usage context on the emergence of overspecification. (It has actually been published online already a couple of weeks ago, and an earlier version of it was included in last year’s Evolang proceedings.) Some of the volunteers who participated in our experiment have actually been recruited via Replicated Typo – thanks to everyone who helped us out! Without you, this study wouldn’t have been possible.
I hope that I’ll find time to write a bit more about this paper in the near future, especially about its development, which might itself qualify as an interesting example of cultural evolution. Even though the paper just reports on a tiny experimental case study, adressing a fairly specific phenomenon, we discovered, in the process of writing, that each of the three authors had quite different ideas of how language works, which made the write-up process much more challenging than expected (but arguably also more interesting).
For now, however, I’ll just link to the paper and quote our abstract:
This article investigates the influence of contextual pressures on the evolution of overspecification, i.e. the degree to which communicatively irrelevant meaning dimensions are specified, in an iterated learning setup. To this end, we combine two lines of research: In artificial language learning studies, it has been shown that (miniature) languages adapt to their contexts of use. In experimental pragmatics, it has been shown that referential overspecification in natural language is more likely to occur in contexts in which the communicatively relevant feature dimensions are harder to discern. We test whether similar functional pressures can promote the cumulative growth of referential overspecification in iterated artificial language learning. Participants were trained on an artificial language which they then used to refer to objects. The output of each participant was used as input for the next participant. The initial language was designed such that it did not show any overspecification, but it allowed for overspecification to emerge in 16 out of 32 usage contexts. Between conditions, we manipulated the referential context in which the target items appear, so that the relative visuospatial complexity of the scene would make the communicatively relevant feature dimensions more difficult to discern in one of them. The artificial languages became overspecified more quickly and to a significantly higher degree in this condition, indicating that the trend toward overspecification was stronger in these contexts, as suggested by experimental pragmatics research. These results add further support to the hypothesis that linguistic conventions can be partly determined by usage context and shows that experimental pragmatics can be fruitfully combined with artificial language learning to offer valuable insights into the mechanisms involved in the evolution of linguistic phenomena.
In addition to our article, there’s also a number of other papers in the new JoLE issue that are well worth a read, including another Iterated Learning paper by Clay Beckner, Janet Pierrehumbert, and Jennifer Hay, who have conducted a follow-up on the seminal Kirby, Cornish & Smith (2008) study. Apart from presenting highly relevant findings, they also make some very interesting methodological points.
September Tutorial in Empiricism: Practical Help for Experimental Novices
In September, the Language Evolution and Interaction Scholars of Nijmegen (LEvInSoN group), based in the Language and Cognition Department at the Max Planck Institute for Psycholinguistics will be hosting a workshop about research in Language Evolution and Interaction (September 21-22) – call for posters here: http://www.mpi.nl/events/MMIEL
As an addition to this workshop, we will be hosting a short tutorial series bookending the workshop (Sept 20 & 23) covering experimental and statistical methods that should be of broad interest to a general audience. In this tutorial series, we will cover all aspects of creating, hosting, and analysing the data from a set of experiments that will be run live (online) during the workshop.