![]() In the last post, I discussed some of the literature into experimental communication, with the intention of then following it up by looking at recent experiments done at Edinburgh (and beyond). But as Hannah pipped me to the post, with a great overview of the wide range of experiments into language evolution, I’ll instead limit this to two relatively recent papers on Human Iterated Learning (Kirby et al., 2008; Cornish et al., 2009)
In the last post, I discussed some of the literature into experimental communication, with the intention of then following it up by looking at recent experiments done at Edinburgh (and beyond). But as Hannah pipped me to the post, with a great overview of the wide range of experiments into language evolution, I’ll instead limit this to two relatively recent papers on Human Iterated Learning (Kirby et al., 2008; Cornish et al., 2009)
Drawing from experimental approaches found in Diffusion Chain and Artificial Language Learning studies, Kirby et al (2008) show that as a consequence of intergenerational transmission languages “culturally evolve in such a way as to maximize their own transmissibility: over time, the languages in our experiments become easier to learn and increasingly structured.” In these experiments a subject is exposed to an alien language, made up of two elements within a finite space: meanings (consisting of a picture with three discernible elements: colour, shape and movement) paired with signals (consisting of a string of letters). Importantly, the subject is only exposed to a set amount of meanings (SEEN items), after which they are then presented with a group of meanings (some SEEN, some UNSEEN) without the corresponding signal — the goal being that they provide a response (be it the correct version or not). On completion of forming the meaning-signal pairs the experiment is repeated, except this time the new subjects are trained on the data provided by the previous generation. This continues until the experiment is finished, which in this case happened at generation ten.

For their paper, Kirby et al run two experiments. The first is essentially identical to the above description, with a set of 27 string-picture pairs being divided into two sets: the SEEN set (14 string-picture pairs) and the UNSEEN set (13 string-picture pairs). In the second experiment however the SEEN set was filtered before being presented to the next generation:
Specifically, if any string labeled more than 1 picture, all but 1 of those string-picture pairs (chosen at random) was moved into the UNSEEN set. As a result, the training data seen by participants in the second experiment consisted of a purely 1-to-1 mapping from strings to pictures, even if the language of the previous generation included 1-to-many mappings.
By filtering out ambiguous meaning-strings, the authors are attempting to enforce an expressivity requirement: so that a unique 1-to-1 mapping between meanings and strings will add the additional challenge for a transmitted language to become structured. The goal being to see whether or not different pressures will result in markedly different solutions.
Learnability, Structure and Expressivity
The first point to look at is whether or not the languages are increasing in their learnability. To do this, the authors considered the transmissions error, which is simply where the mean distance is calculated between all the signals in a participant’s output and the corresponding signals in the previous generation’s output. Essentially, a decreasing transmission error reflects an increasing amount of inter-generational learnability (see figure below for transmission error across 4-languages over 10-generations):
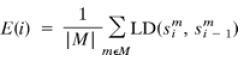{kind=link}
Yet how do we explain this increase in learnability? The introduction of a filter meant the experiment was equipped to rule out the possibility of participants using a different heuristic strategy to generalisation (such as rote learning) when exposed to the language. That participants fail to reproduce the chain faithfully from generation-to-generation is partially indicative of them not wholly relying on rote learning; rather, in later generations at least, the participants appear to rely on a more systematic method — they impose a structural relationship between the signals and meanings. Quantifying the emergence of an increasingly structured language is computed using a pairwise distance correlation (PDC). PDC uses a normalized Levenshtein distance, which calculates the edit distance between all pairs of strings in the language, and then the Hamming distance for the distances between all pairs of meanings. Next, Pearson’s product-moment correlation is applied to these two sets of distances, giving an indication as to which “similar meanings are expressed using similar strings”. Lastly, a Monte Carlo sample is used to give the z-score for the veridical correlation. As the figure below shows, the languages are evolving to become increasingly structured, with the output of the final generation being significantly more structured than the initial language:

As already mentioned, the results generally show languages become increasingly structured and increasingly learnable. However, the main difference between both experiments is in their expressivity: in experiment one, the languages that emerge have a high degree of ambiguity between the signal-meaning pairs, whilst experiment two manages to bypass this through the introduction of a filter. In a later paper, Cornish et al analyse these results under a new experimental methodology, which investigates this perceived tension between learnability and expressivity. The major finding being the ability to discover the types of structure that emerged in two of their languages. First, they find one of the languages from the first experiment is clearly the result of underspecification: “[…] a reduction in the total number of distinct signals, introducing ambiguity with respect to the meanings”. Still, this ambiguity is not a random assignment of signals and meanings, but rather a system of consistently structured mappings emerged.
A language from the second experiment, however, is not the result of underspecification. Rather, it appears to be more expressive and communicatively functional. On the basis of Cornish, Tamariz & Kirby’s results this suggests it is compositional: “whereby the meaning of a given string could be inferred by the meaning of sub-parts of that string (morphemes) and the way they are put together.” As distinguishing between underspecification and compositionality is difficult to infer from PDC, in that all we know is a correlation exists between the meaning structure and signal spaces, they instead use an analysis program called RegMap (Regularity of the Mapping). RegMap is simply a metric that measures the systematicity of a language. The figure below shows how changes in the language are guided towards maximising compositionality:

As the authors note:
The continuous coloured lines represent RegMap values obtained with all nine segment-meaning feature pairs in the ten generations of a language family from Kirby, Cornish and Smith 2008, referred to in Example 3. The boxplots show the distributions of values obtained with 10,000 randomised languages. The upper graphs show RegMap values from the sub-set of language (taken from the previous generation) that was actually transmitted to the current generation, after the ‘bottleneck’ was applied. The lower graphs show RegMap values obtained from the complete languages that participants actually produced at a given generation, before the bottleneck was applied.
These results not only tend to confirm the notion recently considered by Christiansen & Chater (2008), whereby language adapts to the user to become learnable — it also has to adapt to brain external constraints found in the transmission itself. Therefore, even slight alterations in the way a language is culturally transmitted may produce different structures. The current set of experiments show at least two known pressures acting upon the language: learnability versus expressivity — and it is these competing pressures that allow for structure to emerge over a certain length of time:
Given only a bottleneck on transmission preventing a proportion of the language from being seen by the next generation, language can adapt in such a way that ensures it is stably transmitted to future generations regardless. This however occurs at the expense of being able to uniquely refer to every meaning. When they introduced the additional pressure of having to use a unique signal for each meaning, the language once again adapted to cope with these new transmission constraints, this time by becoming compositional. Having a compositional system ensures that both signals and meanings survive the bottleneck […] Moreover, we were able to more precisely describe the role of the bottleneck in bringing about compositionality: the smaller subsets sampled as inputs to the next generation may locally contain more systematicity than the entire language. Iterating this learning process using these small samples therefore provides a platform that allows systematic patterns to be noticed, remembered and replicated preferentially, thereby allowing them to gradually accumulate in the language as a whole.
References:
Kirby, S., Cornish, H., & Smith, K. (2008). Cumulative cultural evolution in the laboratory: An experimental approach to the origins of structure in human language Proceedings of the National Academy of Sciences, 105 (31), 10681-10686 DOI: 10.1073/pnas.0707835105
Cornish, H., Tamariz, M., & Kirby, S. (2009). Complex Adaptive Systems and the Origins of Adaptive Structure: What Experiments Can Tell Us Language Learning, 59, 187-205 DOI: 10.1111/j.1467-9922.2009.00540.x
2 thoughts on “Experiments in communication pt 2: Human Iterated Learning”