I recently discovered that videos uploaded to YouTube are automatically transcribed (if they’re in English). As you might guess, the transcriptions are not perfect, so there will be a discrepancy between what the speaker actually said and what is transcribed. This is essentially all you need to run an iterated learning experiment (e.g. Kirby, Cornish & Smith, 2008). Iterated learning is a process of repeatedly transmitting a signal through a bottleneck. For instance, language is transmitted from adults to children, who learn its rules. These children then go on to transmit this language to their own children.
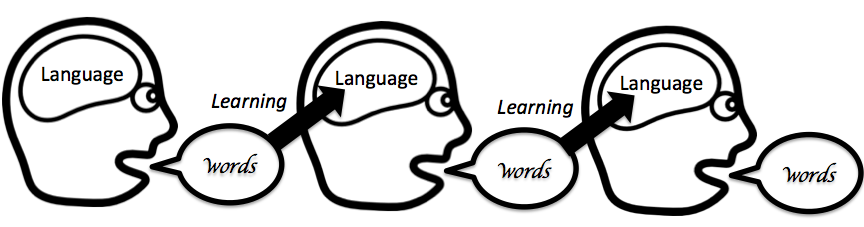
Simon Kirby and colleagues have discovered that this process leads to languages becoming both more learnable and more expressive over time. This happens by the emergence of compositionality: parts of a word become systematically linked to parts of its meaning. See some posts by Hannah and Wintz on these experiments.
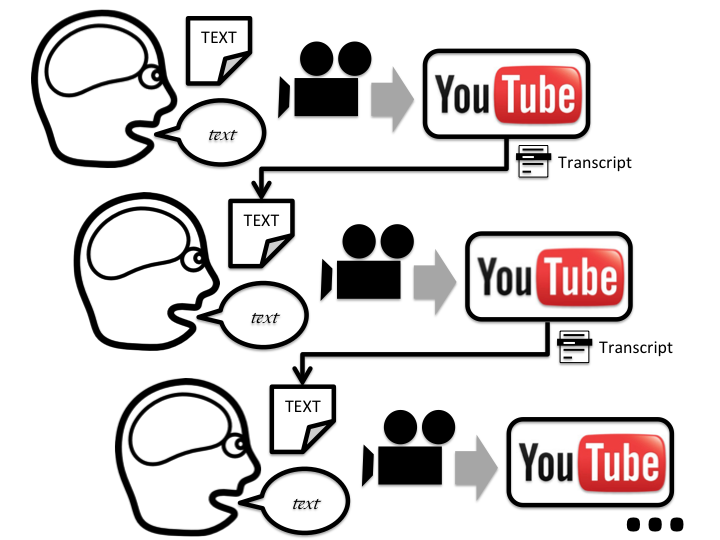
But can we see the same process with non-human learners? Here’s how iterated learning with YouTube works:
- Record yourself saying something.
- Upload the video to YouTube
- Let it be automatically transcribed (usually takes about 10 minutes for a short video)
- Record yourself saying the text from the automatic transcription
- Go to 2
Here’s a diagram of the procedure:
I did this with a short extract from the start of Kafka’s Metamorphosis. Here’s a video of the results from generation 1, 2, 5 and 10:
The text certainly changes over time, but is it changing systematically? Let’s look at some numbers. In the graphs below we see that the total number of words in the text declines but the number of unique words increases. Words are also getting longer on average over time.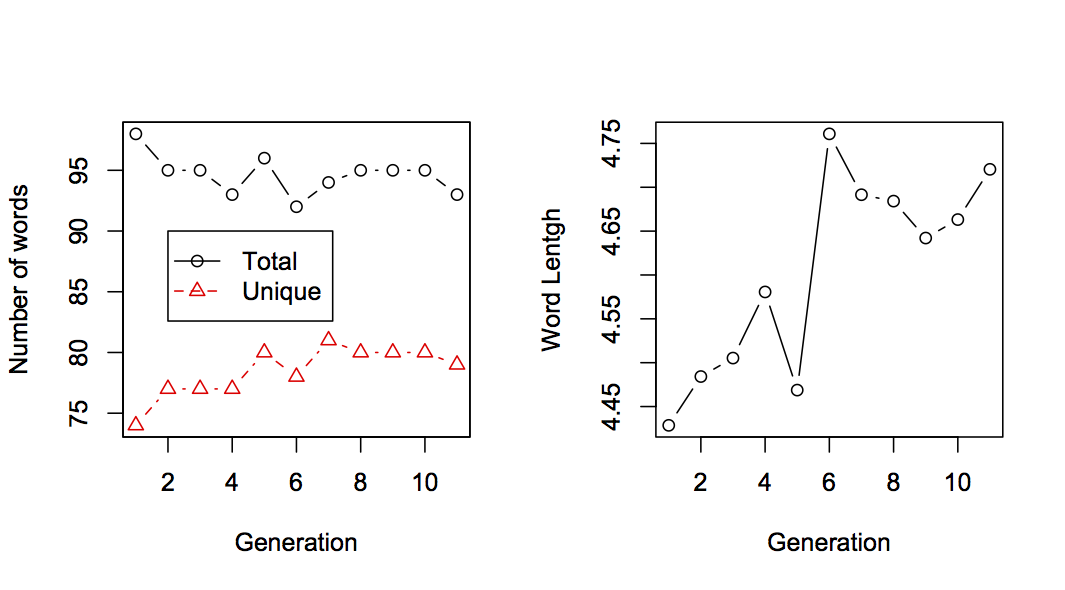
In the human iterated learning experiments, languages become easier to learn over time. We can estimate this using two measures. First, the error rate of the transcription at each generation (i.e. the accuracy of the transcription). This is calculated as the normalised Damerau Levenshtein distance between words. Secondly, we can measure the compressibility of each transcription. This is done by comparing the size of the text file in bytes and the size of the zipped text file in bytes.
In the graphs below, we see that the error rate for generation 1 is about 0.4. This means that the automatic transcription is accurately transcribing about 60% of the words in a video. However, the error actually declines over time, meaning that the transcription of generation 10 is much more accurate (about 95% accuracy). We also see that the compression ratio declines over time (r = -0.0014782, t = -3.1, p = 0.01). This means that the transcription is becoming more compressible by accumulating regularities.
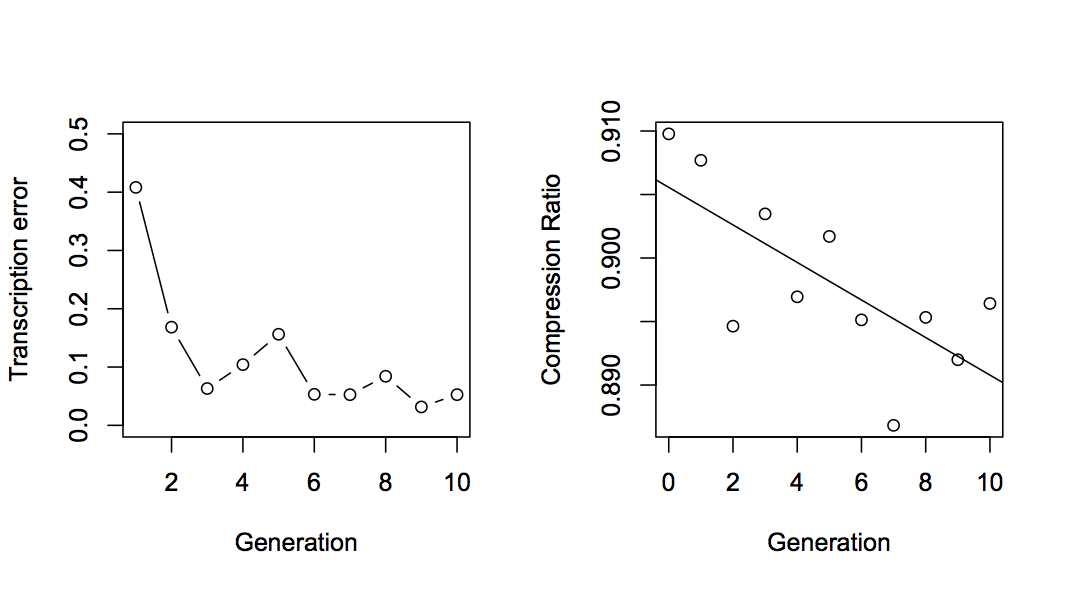
So, this process of iterated learning results in a text which has longer words and more unique words, but at the same time is also more compressible and less prone to error in transmission. In a sense, the texts have become more expressive and more learnable, just like in the human iterated learning experiments. Of course, it’s increasingly difficult for us humans to make sense of the text, but the process does not include a pressure to maintain semantic meaning. The text has adapted to the constraints of the bottleneck imposed by the YouTube transcription. We can say that the YouTube transcription algorithm has a bias for longer words, fewer total words and better compression. This may be due, for instance, to the perception of two separate words as one because of coarticulation.
Of course, there’s another source of bias in this apart from the YouTube transcription algorithm: me! I might be reading particular words more clearly or interpreting the prosody in a particular way. Perhaps a better analogue of the iterated learning model would be to film the YouTube video itself rather than me re-recording it. However, in language learning, the transmission process is also affected by the biases of the speaker as well as the learner.
EDIT: As many commenters have pointed out, this study isn’t really revealing anything about the evolution of human language, but rather it’s revealing the inductive biases of the YouTube transcription system, similar to Kalish et al. (2007)’s study of iterated function learning. However, it’s also possible that the inductive biases are being amplified by the transmission process, as in Kirby, Dowman & Griffiths (2007).
References
Kirby, S., Cornish, H., & Smith, K. (2008). Cumulative cultural evolution in the laboratory: An experimental approach to the origins of structure in human language Proceedings of the National Academy of Sciences, 105 (31), 10681-10686 DOI: 10.1073/pnas.0707835105
Kalish, M. L., Griffiths, T. L., and Lewandowsky, S. (2007). Iterated learning: inter- generational knowledge transmission reveals inductive biases. Psychon Bull Rev, 14(2):288–94.
Kirby, S., Dowman, M., and Griffiths, T. L. (2007). Innateness and culture in the evolution of language. Proceedings of the National Academy of Sciences, 104(12):5241–5245.
Did you think about using a computer voice to read the text?
I thought of that yesterday – would have saved me trying to say those tongue-twisters! With the YouTube API, it may even be possible to automate the whole process.
Someone really should do this, the outcome of the 10th iteration would be super-interesting…
Awesome. I was wondering about what’s causing the increase in compressibility over the generations. This would be due to a loss of variation in the datafiles (i.e. accumulating regularities) – like maybe you got increasingly bored reading each iteration and settled into more predictable intonational patterns. Anyway, this exercise definitely exposes the biases in YouTube’s transcription algorithm – maybe they’ll hire you as a consultant, hehe.
Justin Quillinan has now implemented a computer-voice version! http://www.replicatedtypo.com/iterated-learning-using-youtube-videos-and-speech-synthesis/6123.html