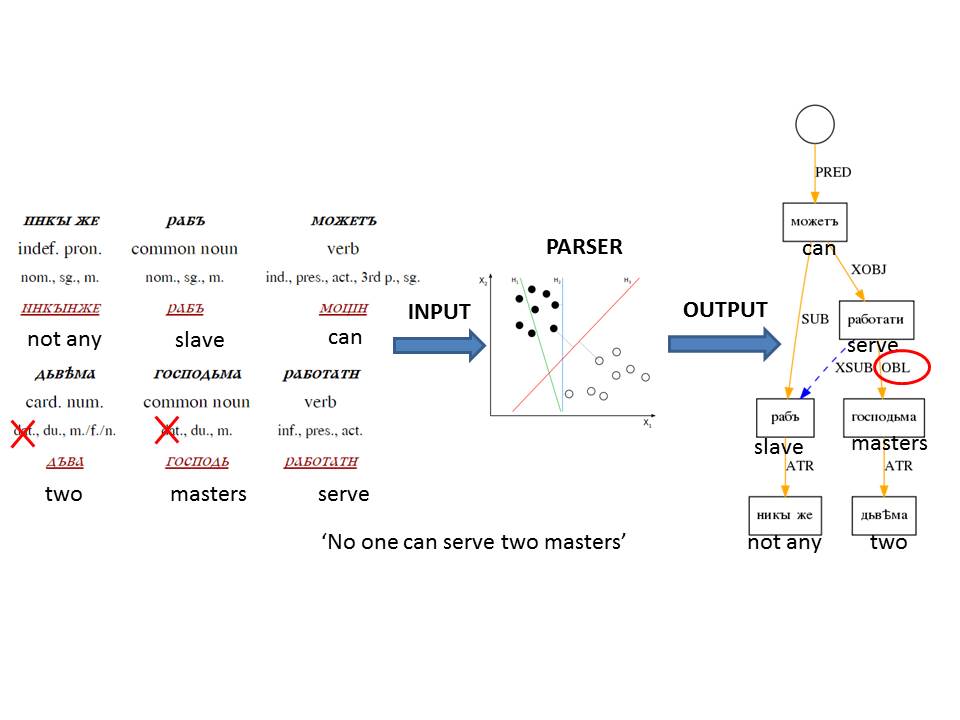
This week the workshops appearing at EvoLang have been announced. Participation is free to those attending the main conference.
Gregory Mills and I are running a workshop on language evolution and interaction. Details are on the workshop website, including a call for papers.

Language Adapts to Interaction
Language has been shown to be adapted to constraints from many domains such as production, transmission, memory, processing and acquisition. These adaptations and constraints have formed the basis for theories of language evolution, but arguably the primary ecology of language is interaction – face-to-face conversation (Levinson, 2006). Taking turns at talk, repairing problems in communication and organising conversation into contingent sequences seem completely natural to us, but are in fact highly organised, tightly integrated systems (Sacks et al., 1974) which are not shared by any other species. Therefore, the infrastructure for interaction may provide an insight into the origins of our unique communicative abilities (Mills, 2014a; Micklos, 2014).
Indeed, recent studies on interaction have shown that an approach that emphasises interaction can sharpen our understanding of linguistic universals (Kendrick et al., 2014; Dingemanse et al., 2015), ontogeny and acquisition (Hilbrink, et al. 2015; Vogt, 2014), on-line processing constraints (Bögels et al., 2015) and animal signalling (Levinson & Holler, 2014).
The emerging picture is that the infrastructure for interaction is an evolutionary old requirement for the emergence of a complex linguistic system, and for a cooperative, cumulative culture more generally. These issues are also being integrated into computational models of the cultural evolution of linguistic systems (Vogt and Haasdijk, 2010; Roberts, & Levinson, 2015) and are being explored through studies of experimental semiotics (Mills, 2014b; Christensen et al., 2016).
This workshop is interested in addressing the following questions:
- How did the infrastructure for interaction emerge and how did it shape the emergence of language?
- What evidence is there that language structures show adaptation to interaction?
- How do interactional constraints interact with other domains such as processing?
- What are the limits of interactional abilities in non-human animals?
For instructions on how to submit, please see the Abstract Submissions page.
References
Bögels, S., Magyari, L., & Levinson, S. C. (2015). Neural signatures of response planning occur midway through an incoming question in conversation. Scientific Reports, 5: 12881.
Christensen, P., Fusaroli, R., and Tylén, K. (2016). Environmental constraints shaping constituent order in emerging communication systems: Structural iconicity, interactive alignment and conventionalization. Cognition, 146:67–80.
Dingemanse, M., Roberts, S. G., Baranova, J., Blythe, J., Drew, P., Floyd, S., Gisladottir, R. S., Kendrick, K. H., Levinson, S. C., Manrique, E., Rossi, G., & Enfield, N. J. (2015). Universal Principles in the Repair of Communication Problems. PLoS One, 10(9).
Hilbrink, E., Gattis, M., & Levinson, S. C. (2015). Early developmental changes in the timing of turn-taking: A longitudinal study of mother-infant interaction. Frontiers in Psychology, 6: 1492.
Kendrick, K. H., Brown, P., Dingemanse, M., Floyd, S., Gipper, S., Hayano, K., Hoey, E., Hoymann, G., Manrique, E., Rossi, G., & Levinson, S. C. (2014). Sequence organization: A universal infrastructure for action. 4th International Conference on Conversation Analysis. UCLA, CA.
Levinson, S. (2006). On the human interaction engine. In Enfield, N. and Levinson, S., editors, Roots of Human Sociality: Culture, Cognition and Human Interaction, pages 39–69. Oxford: Berg.
Levinson, S. C., & Holler, J. (2014). The origin of human multi-modal communication. Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences, 369(1651): 2013030.
Micklos, A. (2014) The Nature of Language in Interaction. Proceedings of the 10th Evolution of Language conference. World Scientific: Vienna, Austria.
Mills, G. (2014a) Establishing a communication system: Miscommunication drives Abstraction. Proceedings of the 10th Evolution of Language conference. World Scientific: Vienna, Austria.
Mills, G. J. (2014b). Dialogue in joint activity: complementarity, convergence and conventionalization. New Ideas in Psychology, 32:158–173.
Roberts, S. G. & Levinson (2015) On-line pressures for turn-taking constrain the cultural evolution of word order. Workshop on Cognitive Linguistics and the Evolution of Language, International Cognitive Linguistics Conference, Newcastle University, UK.
Sacks, H., Schegloff, E. A., and Jefferson, G. (1974). A simplest systematics for the organization of turn-taking for conversation. Language, 40(4):696–735.
Vogt, P. (2014) Language acquisition through interactions: A cross-cultural corpus of multimodal interactions with 1-to 2-years old infants. 8th International Conference on Construction Grammar. Osnabrück University, Germany.
Vogt, P. and Haasdijk, E. (2010). Modeling social learning of language and skills. Artificial Life, 16(4):289–309.