
This weekend I appeared in an NPR article about Ian Maddieson and Christophe Coupe’s work on the effects of climate and ecology on the sound systems of languages. I haven’t read the study itself, but I did get to see the slides that Maddieson and Coupe presented this week at the Acoustical Society of America. Essentially, they find that speech sounds have high efficacy – adaptation to being transmitted and received in the local ecology. Specifically, languages tend to be more sonorous (less ‘consonant heavy’) in warmer places with more tree cover. This makes sense, since these kind of sounds are better at cutting through these obstacles.
I was interviewed for about an hour, but the quotes from me in the piece are actually a bit out of context. For instance, I claim that this is the first study of its kind, when there have been several studies which looks at climate and language (including one I co-authored with Caleb Everett and Damian Blasi). But, to be fair, Maddieson and Coupe’s study is probably the one with the greatest range of ecological variables and most sophisticated linguistic measure (although I’m not sure yet how they control for historical relatedness).
You can read about the study in the article above, but I wanted to address another thing I’m quoted as saying. The interviewer asked if it was possible to see these effects in a single language or a single speaker, and I said that it was very unlikely, but that I’d tried to do this with transcripts of Larry King. I went on to say that I absolutely wouldn’t publish this because it was a crazy idea that nobody would believe.
But now the cat’s out of the bag, so here’s what I found.
Does Larry King use more vowels when it’s warmer?
If we see language change as natural selection operating on individual utterances in conversation (a la Croft and others), then we should be able to see selective pressures at work in the utterances of an individual speaker. This should also apply to the influence of climate. Given enough data, you should be able to see an individual adapting over the seasons. In light of Maddieson and Coupe’s hypothesis, speakers should use proportionately more vowels compared to consonants when it’s warmer.
CNN provides transcripts for every show broadcast between 2000 and 2012. Larry King has done an interview practically every day on the show ‘Larry King Live’ (which has been used before in linguistic studies), so I extracted Larry King’s speech transcripts (excluding the guest’s speech, mentions of the location of the studio and the guest’s names). For each transcript I counted the frequency of each letter, then calculated the ratio of vowels (aeiouy) to consonants. Then, for each air date, I found the actual temperature and humidity data for that date and the location of the show (CNN studios in LA). The show is occasionally recorded in Washington DC or New York. I tried to detect these automatically and matched them with the climate measures for the CNN studios in those cities.
There are about 3,500 transcripts over 11 years, about 90% of which were aired on consecutive days. (I know nothing about this show, and am a bit surprised by its frequency! I’ll have to check whether the transcripts include repeats).
Here is a depiction of the results for temperature and humidity:
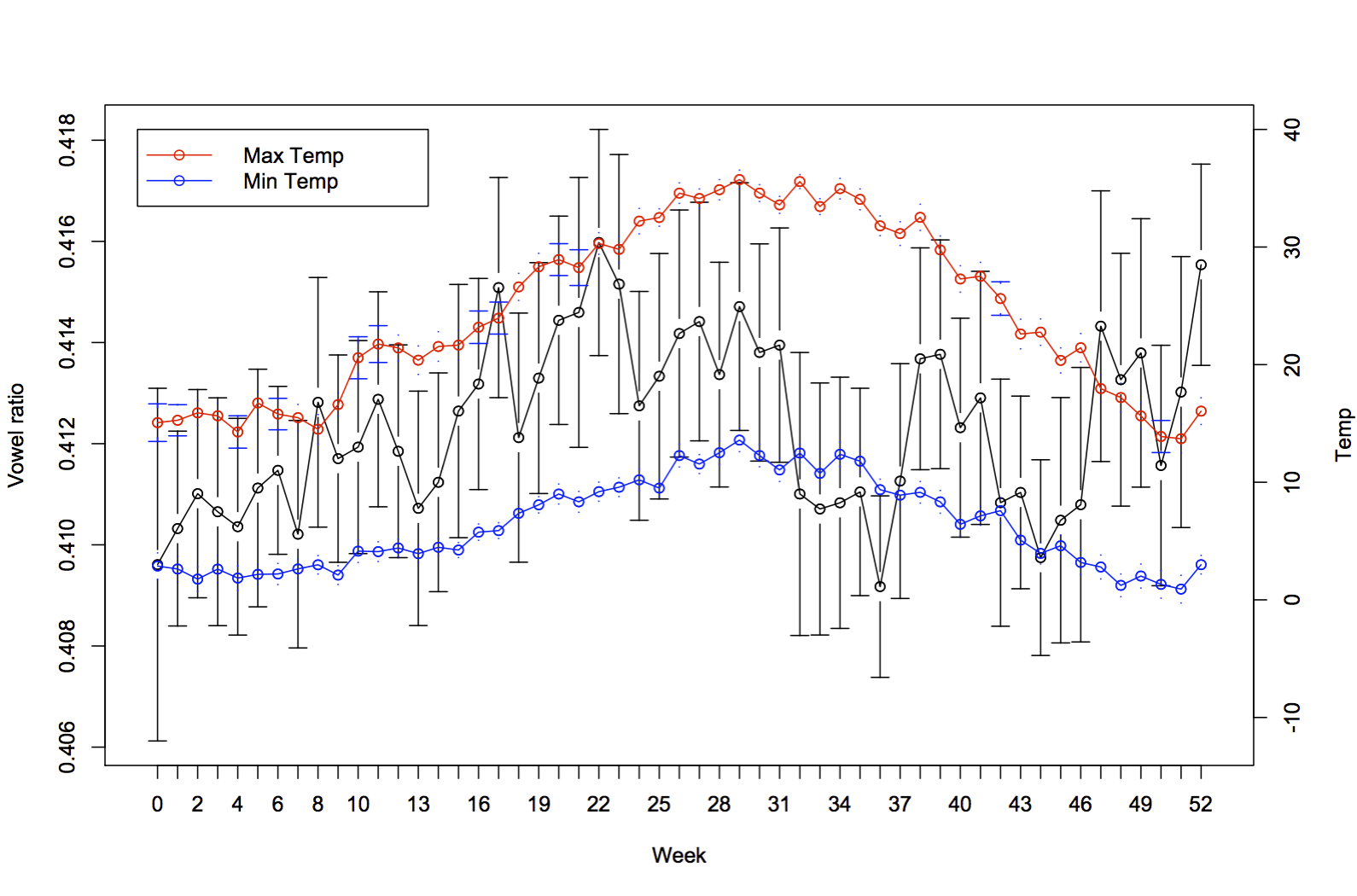
The Black lines show King’s vowel ratio (higher = more vowels) and bars are 95% confidence intervals around the mean for each week of the year. The maximum and minimum temperature are shown in red and blue. Below is a similar graph for specific humidity.
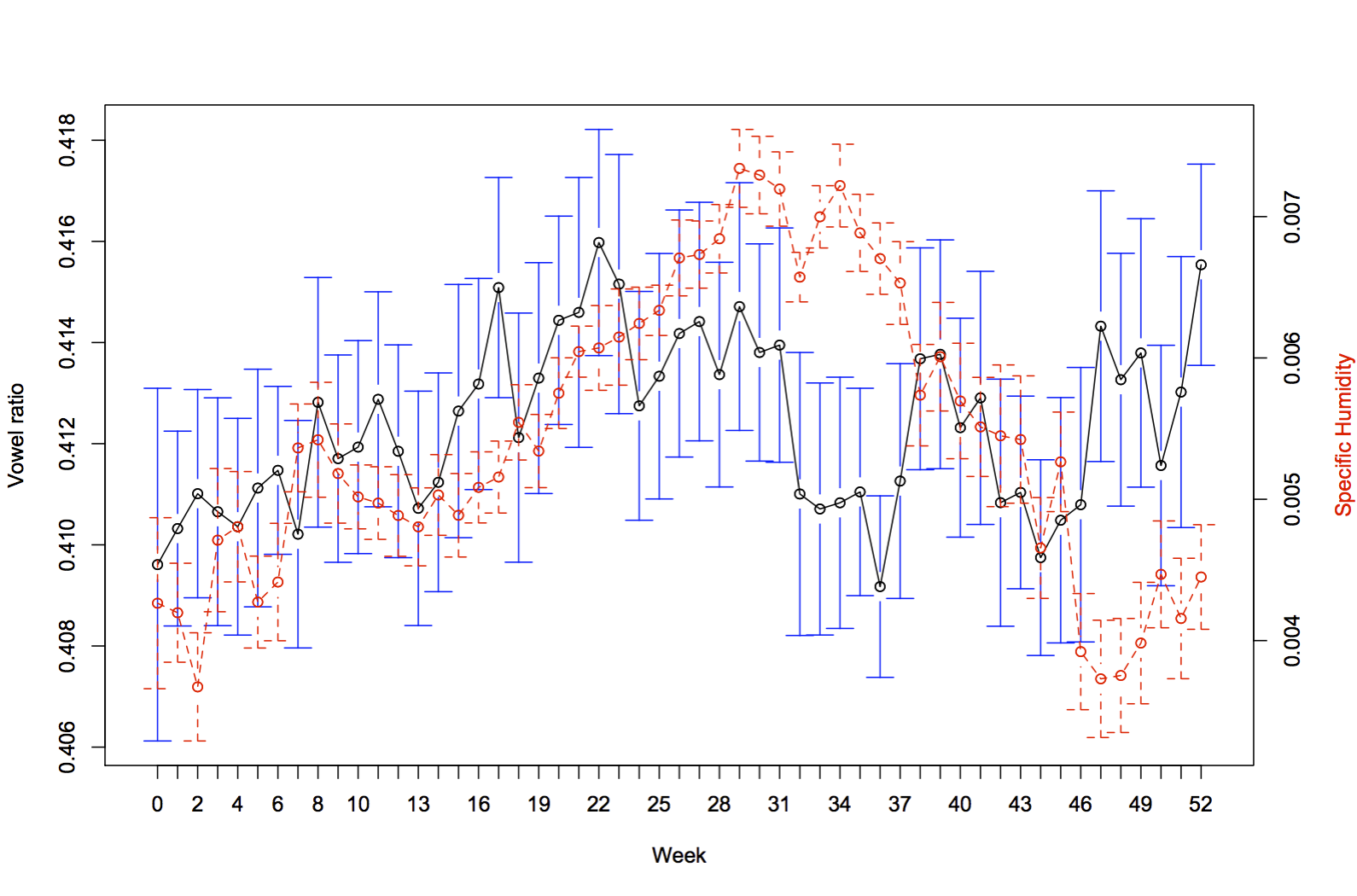
Surprisingly, there is some variation in proportion of vowels, and it looks like there’s a trend in the right direction.
To analyse the data, I used a linear mixed effects model, predicting vowel ratio by (log) text length and maximum temperature, with random effects for year and each week (580 separate weeks, to try to control for topical issues).
Maximum temperature significantly improves the fit of the model over a null model with text length (Chi Squre = 23.7, df = 1, p < 0.00001).
Model estimates: Estimate Std. Error t value (Intercept) 4.100e-01 8.114e-04 505.3 maxTempC.loc 9.628e-05 1.973e-05 4.9 text.total.log.center 5.340e-03 8.400e-04 6.4
King uses proportionately more vowels when it’s warmer. The effect is very small: On average, there is a difference of about 15 vowels used in an hour of conversation between summer and winter. A model with location-specific maximum temperature improves the model fit over one with just LA-specific maximum temperature (Chi Sqaured = 11.59, df=1 , p=0.0007).
Of course, the temperature is not independent from day to day, so I also tried a lagged regression, predicting vowel ratio by text length (total) and maximum temperature of the recording location (maxTempC.loc). Lagging back in time by days.
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.076e-01 7.342e-04 555.073 < 2e-16 ***
d[lag.0, ]$textLength 3.772e-07 6.715e-08 5.618 2.08e-08 ***
d[lag.0, ]$maxTempC.loc 1.008e-04 3.300e-05 3.055 0.00227 **
d[lag.1, ]$maxTempC.loc 5.009e-05 3.812e-05 1.314 0.18893
d[lag.2, ]$maxTempC.loc 1.549e-07 3.840e-05 0.004 0.99678
d[lag.3, ]$maxTempC.loc -7.405e-05 3.809e-05 -1.944 0.05195 .
d[lag.4, ]$maxTempC.loc -2.418e-06 3.300e-05 -0.073 0.94159
The temperature of actual day is still significant, taking into account previous days. Note that the coefficient is negative after 3 lagged days. (please forgive the rough analysis- it’s all I have left after my computer broke recently).
I’m not really sure what to make of this. Given the data above, there is an argument that King is adapting the way he speaks to the climate. However, a LOT more needs to be done in order to show this. There are several confounding factors, such as the show being recorded in an air conditioned studio, the topics or guests might be different, there might be seasonal topics or key-words which affect the results (though one might argue that the lexicon for things related to cold climates has adapted). The graphs show big jumps around week 32, which I can’t explain yet. Then there is the question of the mechanism – how exactly is King adapting? By choice of alternative words, or constructions? And, of course, the transcripts are orthorgraphic. And, of course, the idea is crazy.
Still, I think it’s amazing that we’re now in a position where we can even start asking these kind of questions with data.
LOL! Yes, it’s a remarkable world we’re living in.
Can you try comparing excerpts from the most and least ‘vowelly’ segments, long enough to still show the effect, but short enough to look at the word frequency distribution in each without drowning in data?
Three comments:
First, there’s another huge discontinuity in the yearly time series, between weeks 52 and 1. This is obscured by plotting the data in two dimensions, but of course the beginning and the end should be connected in a 3d circle. The 31st week of the year is around the end of July, so my alternative hypothesis is that Larry King uses more consonants just after he goes on vacation, which he does twice a year in late July and at New Year’s. Maybe people use more vowels when they’re stressed or something.
Second, it’s very easy to run standard English through CMUdict or something similar to get pronunciations. This won’t account for stress, segments elided during speech, etc. But it’s really hard to take the analysis seriously unless you take that basic step, especially since English is well-known to have lots of orthographic vowels that are non-phonological (silent e at the ends of words, -ed past tense which is frequently realized as just a /t/ or /d/ segment, word-initial y, …)
Third, you have to look at style/register. I bet that higher-register words have a higher proportion of vowels, due to suffixes like -ation (0.6, or 0.5 if you count phonetically) and -ity (0.66 either orthographically or phonetically). If there’s seasonal variation in the register of the interviews (e.g. because Larry King tends to talk less formally when he is just back from vacation), that will confound the observed effect. There’s work by Biber on measuring the register of texts. For a quick and dirty test you could look at the type:token ratio and the average length of words in the transcript.
Good suggestions! and it’s a good point about the discontinuities. I still have to look at the text clean-up scripts to make sure they’re not doing something strange, or including messages from sponsors etc.. Still, I’m not planning on taking this study further in the near future, so if anyone wants to do this, let me know!
That’s a good idea – it would be quite easy to do a qualitative analysis of the most and least vowelly shows.
Yes – it would really make sense that King “is adapting the way he speaks to the climate” as he sits in his windowless, air-conditioned, temperature-controlled studio bombarded by hot, bright artificial lighting.