![]()
In my last post on the vanishing phonemes debate I briefly mentioned Atkinson’s two major theoretical points: (i) that there is a link between phoneme inventory sizes, mechanisms of cultural transmission and the underlying demographic processes supporting these changes; (ii) we could develop a Serial Founder Effect (SFE) model from Africa based on the phoneme inventory size. I also made the point that more work was needed on the details of the first claim before we went ahead and tested the second. To me at least, it seems slightly odd to assume the first model is correct, without really going to any great lengths to disprove it, and then go ahead and commit the statistical version of the narrative fallacy – you find a model that fits the past and use it to tell a story. Still, I guess the best way to get in the New York Times is to come up with a Human Origins story, and leave the boring phonemes as a periphery detail.
Unrealistic Assumptions?
One problem with these unrealistic assumptions is they lead us to believe there is a linear relationship between a linguistic variable (e.g. phoneme inventories) and a socio-demographic variable (e.g. population size). The reality is far more complicated. For instance, Atkinson (2011) and Lupyan & Dale (2010) both consider population size as a variable. Where the two differ is in their theoretical rationale for the application of this variable: whereas the former is interested in how these population dynamics impact upon the distribution of variation, the latter sees social structure as a substantial feature of the linguistic environment in which a language adapts. It is sometimes useful to tell simple stories, and abstract away from the messy complexities of life, yet for the relationships being discussed here, I think we’re still missing some vital points.
First, as Trudgill (2004a; 2004b; 2011) has repeatedly pointed out, these cross-linguistic similarities in phoneme inventory sizes are contingent on numerous social, cultural and demographic factors. Besides genealogical and areal factors, socio-demographic forces are theorised to influence language structure in three fundamental ways: (i) Community Size; (ii) Network Density and Multiplexity; (iii) Learner Bias Composition (degree of adult versus child learning). Taken together, these forces regulate contact between individuals within a speech community, and it is this concept of interaction through which linguistic knowledge is built, maintained and changed. Societal complexity will therefore influence what an individual is exposed to, how their linguistic, social and cultural knowledge is structured, and impact upon the pressures underpinning successful acts of communication.
The second point is straight out of phonology 101: phoneme inventories are not a homogenous range of vaguely similar sounds, but are instead coarsely divided into consonants and vowels. These two classes of phonemes clearly play different functional roles in language. This is demonstrated in that vowels and consonants vary across articulatory (Lindblom & Maddieson, 1988), perceptual (cf. Kolinsky et al., 2009) and processing (cf. Carreiras et al., 2008) dimensions, as well as differing on several measures, including the degree of sonority, phonotactic deployment and functional load. There is even some evidence to suggest these two types of phoneme classes will cluster according to climatic zones (see below for more on this). So, the question is: to what extent can we say that those factors influencing vowel inventories are necessarily going to hold true for consonant inventories, or vice versa? After all, it has long been acknowledged that the sizes of these two inventories do not correlate (Ladefoged & Maddieson, 1996), and this is without getting into the issues surrounding tonal contrasts.
The last point concerns the many levels of organisation found in language. The sounds that make up phonemes are, after all, part of a wider linguistic environment: that is, they are not easily divorced from the constructions being learned and used by individuals within any one speech community. Changes in one level, then, may result in cumulative and far-reaching effects at other levels. Indeed, there is a whole field of study to this topic of sub-system tradeoffs known as synergetic linguistics (cf. Fenk-Oczlon & Fenk, 2008). Nettle (1999) presents an interesting example of one of these tradeoffs in his statistical analysis showing that there exists a negative correlation between word length and the number of phonological segments (which includes tonal contrasts and vowel length). This was more recently confirmed by Wichmann, Rama & Holman (2011) on a larger sample of over 3000 languages in the ASJP database. So, despite having their own structures and patterns, different linguistic subsystems might produce systematic, overlapping distributions (Wedel, 2007).
We can look at these last two points in more detail. Basically, I’m going to look at the following prediction: that the distribution of consonants and vowels are influenced by different factors. Two identified factors are climatic zones (measured by the degree of latitude and longitude) and subsystem tradeoffs (measured by incorporating mean word length). Below are some brief statistical tests I did on a small(ish) number of languages, with the specific aim of looking at alternative explanations for the size of phoneme inventories. There will be some serious under-reporting of all the results, simply because they form a small part of my dissertation, and I’ll try to go into more detail in future posts (note: I’m happy to clarify any details in the comments).
Testing the Alternatives
We can quickly test these hypotheses to see if the patterns of vowels and consonants are differentially influenced. To give a quick summary of my sources: phoneme inventory size data is from UPSID (I only looked at consonants and vowel quality); speaker population size is from Ethnologue; family and areal data is from WALS; and lastly, word length data was from the ASJP database. As for the statistical tests, I used two regression models. The first, a Generalised Additive Model (GAM), allows you to specify a distribution (in the case a Gaussian), which can then be used to tell you the significance of each variable, the deviance explained by the model and the degree of interaction between two or more independent variables (Fox, 2005). Second, a Bayesian MCMC model comparison is used: this allows us to take two or more regression models, albeit with the same dependent variable, and then compare the predictive power of these models against one another based on how well they account for the prior distribution. The output of the model comparison will show the Log Marginal Likelihood (LML) score (Martin, Quinn & Park, 2008).
When controlling for genealogical and areal factors, the Bayesian MCMC model comparison returned the strongest results for a model consisting of population size and latitude as an independent predictors for consonant inventory size (LML = -702.5982). Each of these predictors combined explain 18.6% (R-sq.(adj) = 0.178) of the total deviance, with both population size (t = 3.271; p = 0.00128) and latitude (t = 4.687; p <.001) returning significant results. Word length does return significant results for consonant inventory size (t = -3.164; p = 0.00181), but this is lost as soon as we control for population size and latitude.

A fitted surface for the additive non-parametric regression of consonant inventory size on latitude and speaker population size can be displayed to show this relationship more clearly:

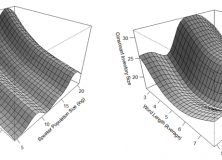
We can also do the same to show the effects of word length and speaker population size:

And again for word length and latitude:

Moving on to vowel quality inventories and a different picture emerges. It seems the best candidate models are word length and population size (LML = -388.5584) and just word length (LML = -389.4255). I included both results because the evidence to support one model of another is not strong at all and worth no more than a bare mention. In separate models, word length (R-sq.(adj) = 0.175; deviance explained = 18%) appears to be a stronger predictor than population size (R-sq.(adj) = 0.076; Deviance explained = 8.09%). Interestingly, when family and areal controls are introduced, only word length remains a statistically significant predictor in the combined model.

Again, we can display a fitted surface for the additive non-parametric regression for vowel quality inventory size on word length and speaker population size:

Linking population size with segment inventory size appears not to be the whole story. Based on the current results, these superficial regularities in larger segment inventories are further delineated along the lines of consonants and vowel quality. So, whereas larger population sizes and latitudes further away from the equator are the best predictors of an increased consonant inventory size, the same does not hold true for vowel quality inventories: here, the strongest predictor appears to be the negative relationship between the number of vowels and the mean word length.
This still doesn’t resolve why consonants are more likely to be found further away from the equator and why more vowels are associated with shorter word lengths. A cultural evolutionary explanation makes sense of the division if, as in other evolutionary systems, language change is characterised by a division of labour. The clustering of a large number of consonants north and south of the equator might be the result of climatic zones. Cold-climate languages, for instance, are found to have a high frequency of consonants at a very low frequency (obstruents). By contrast, languages in warm climatic zones possess sound classes exhibiting moderate to high levels of sonority (rhotic consonants, laterals, nasals and vowels) (cf. Munroe, Fought & Macaulay, 2009). As for word length: It is widely acknowledged in the literature that vowels and consonants subtend to different linguistic functions. Consonants are often associated with word identification, whereas vowels contribute to grammar and to prosody (cf. Kolinsky et al., 2009). Vowel quality is also implicated in regular sound change, which results in paradigmatic changes, whereas consonants are frequently cited as being changed through lexical diffusion (cf. Labov, 1994). Lastly, consonant systems expand with “minimum articulatory cost” (Lindblom & Maddieson, 1988: 72), whereas vowel systems appear to follow pressure for maximal perceptual differences (Munroe, Fought & Macaulay, 2009).
Assuming these results hold in larger datasets, which I will hopefully get around to doing at some point in the near future, then it goes to show that there might be some hidden stories behind the phonemic diversity and demography correlations. This by no means disproves the original hypothesis put forward to support the cultural transmission model linking phoneme inventory sizes and demography. But I think it does offer an instructive point: that more work needs to be done on these original correlations and their underlying theoretical assumptions.
N.B. If you managed to read all of this then here are some additional treats. The first is a paper by Hunley et al: Rejection of a serial founder effect model of genetic and linguistic coevolution (Language Log provided some good coverage on this). To continue with the pile-on Science published three technical comments (see here, here and here). Atkinson also offered a response (see here).
References
Atkinson, Q. (2011). Phonemic Diversity Supports a Serial Founder Effect Model of Language Expansion from Africa Science, 332 (6027), 346-349 DOI: 10.1126/science.1199295
Lupyan G, & Dale R (2010). Language structure is partly determined by social structure. PloS one, 5 (1) PMID: 20098492
Trudgill, P. (2004). Linguistic and social typology: The Austronesian migrations and phoneme inventories Linguistic Typology, 8 (3), 305-320 DOI: 10.1515/lity.2004.8.3.305
Trudgill, P. (2011). Social structure and phoneme inventories Linguistic Typology, 15 (2), 155-160 DOI: 10.1515/LITY.2011.010
Kolinsky, R., Lidji, P., Peretz, I., Besson, M., & Morais, J. (2009). Processing interactions between phonology and melody: Vowels sing but consonants speak Cognition, 112 (1), 1-20 DOI: 10.1016/j.cognition.2009.02.014
Munroe, R., Fought, J., & Macaulay, R. (2009). Warm Climates and Sonority Classes: Not Simply More Vowels and Fewer Consonants Cross-Cultural Research, 43 (2), 123-133 DOI: 10.1177/1069397109331485
1 thought on “Phonemic Diversity and Vanishing Phonemes: Looking for Alternative Hypotheses”