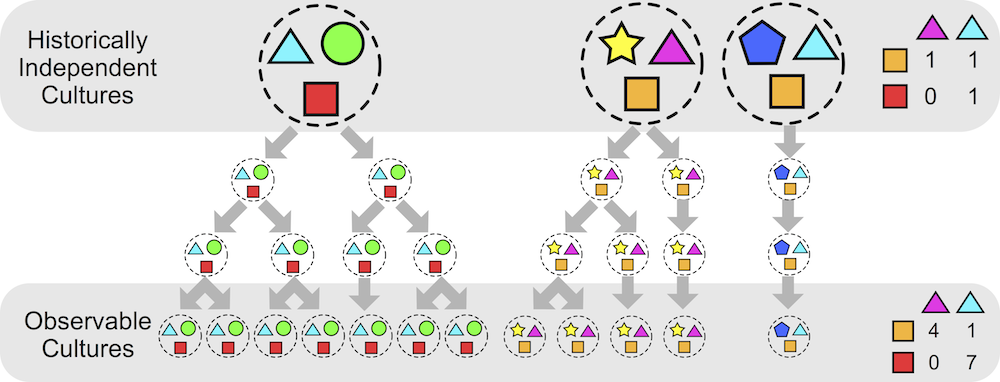
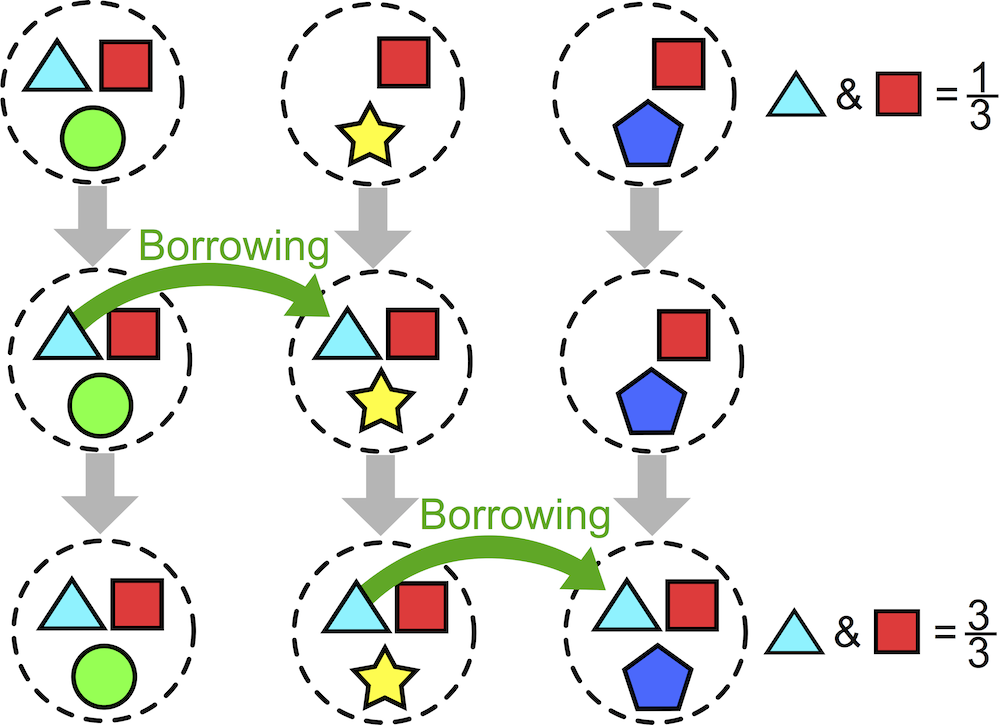
Another working paper (title above):
Academia.edu: https://www.academia.edu/10263479/Cultural_Evolution_Literary_History_Popular_Music_Cultural_Beings_Temporality_and_the_Mesh
SSRN: http://ssrn.com/abstract=2553278
Abstract and introduction below.
* * * * *
Abstract: Culture is implemented in a material and biological substrate but has a distinct ontology and its phenomena belong to a distinct order of temporality. The evolution of culture proceeds by random variation among coordinators, the cultural parallel to biological genes, and selective retention of phantasms, the cultural parallel to biological phenotypes. Taken together phantasms and a package or envelope of coordinators constitute a cultural being. In at least the case of 19th century American and British novels, cultural evolution has a direction, as demonstrated by the analytical work of Matthew Jockers (Macroanalysis 2013). While we can think of cultural evolution as a phenomenon that happens in history, it is at the same time a force that influences human life. It is thus a force IN history. This is illustrated by considering the history of the European novel from the 19th century and into the 20th century and in the evolution of popular musical styles in 20th century American music, in which interaction between African American and European American populations has been important. Ultimately, the evolution of culture can be thought of as the evolution of mind.
* * * * *
0. Introduction: The Evolution of Culture is the Evolution of Mind
One of the themes that has been prominent in Western culture is that we humans have a “higher” nature and a “lower” nature. That lower nature is something we share with animals, even plants–I’m thinking here of Aristotle’s account of the soul. That higher nature is unique to us and we have tended to identify it with reason and rationality. We are rational and can reason, animals are not and cannot.
It was one thing to hold such a belief when we could believe that our nature was distinct from that of animals. Darwin made that belief much more difficult to entertain. If we are descended from apes, and so are but animals, then how can we have this higher nature? And yet, by any reasonable account, we are quite different from all the other animals.
For one thing, we have language. Yes, other animals communicate, and, with much painstaking effort, we’ve managed to teach some sign language to chimpanzees, but still, no other species has yet managed anything quite like human language. And the same goes for culture. Yes, other animals have culture in the sense that they pass behavioral traits from one individual to another through social learning rather than through reproduction. But the trait repertoire of animal culture is quite limited in comparison to that of human culture. Nor has any animal species managed to remake their environment in the way we have, for better or worse, not beavers and their dams, nor termites and their often astounding mounds.
In the process of working through the posts I’ve gathered into the this working paper, the original writing and the subsequent reviewing and revising, I’ve come to believe that it is culture, not reason, that is our higher nature. Reason is a product of culture, not the reverse.
That conclusion is not a direct result of the post’s I’ve gathered here. You won’t find it as a conclusion in any of them, nor will I provide more of an argument in this introduction than I’ve already done. It’s a way of framing my current view of culture and human nature. It’s a higher nature. It rules us even as it is utterly dependent upon us.
Conceptualizing Cultural Evolution
This working paper marks the fruition of a line of investigation I began in 1996 with the publication of “Culture as an Evolutionary Arena” (Journal of Social and Evolutionary Systems, 19(4), 321-362). That was not my first work on cultural evolution; but my earlier work, going back to graduate school in the 1970s, was about stages conceived in terms of cognitive systems (called ranks). That work was descriptive in character, aimed at identifying the types of things possible with a given cognitive apparatus. The 1996 paper was my first attempt at characterizing the process of cultural evolution in evolutionary terms.
That paper originated in conversations I’d had with David Hays, who died in 1995, in which he suggested that the genetic material for cultural evolution was in the external world. Why? Because it is public, open for everyone to see. If the genetic material was out there in the world, I reasoned, then the selective environment must be social, something like a collective mind. That made sense because, after all, isn’t that how books and movies and records survive? Many are published, but only a few are taken up and kept in active circulation over the years.
That’s not much of a conception, but I stuck with it. It’s taken almost two decades for me to refine those initial intuitions into a technical conception that feels good. That’s what I managed to achieve in the process of writing the posts I’ve collected and edited into this working paper.
All of which is to say that I’ve been working on two levels. On the one hand I’ve been making specific proposals about specific phenomena. But those specific proposals are in service of a more abstract project: crafting a framework in which to conceptualize cultural evolution. By way of comparison, consider chapter eleven of Richard Dawkins, The Selfish Gene. That’s where he proposes the concept of memes in thinking about cultural evolution: “Memes: the new replicators” (pp. 189-201). He gives a few examples, but mostly he’s focused on the concept of the meme itself. The examples are there to support the concept. None of them are developed very extensively or in detail; he says just enough to give some sense of what he has in mind.
THAT’s what I’m doing, though proportions and quantities are different. It is the concept of cultural evolution that most interests me: what’s it like, what kind of entities does it involve? The example from Matthew Jockers’ Macroanalysis in the first two posts is just that, an example. In subsequent posts I introduce further examples, but they are just that, examples. Continue reading “Cultural Evolution: Literary History, Popular Music, Cultural Beings, Temporality, and the Mesh”