This is a guest post by Hedvig Skirgård.
The Great Language Game, have you heard of it? It’s an online game where players compete in matching audio clips to the correct language. The game was created by Lars Yencken earlier this year and has become very popular. Data generated by the game can be used to map what languages the players find hardest to tell apart and support what we’ve known all along: Portuguese does sound a bit slavic!
The game works like this: you are played a 20 second audio clip of natural speech and your task is to match the audio clip to one of the alternatives provided. As you advance in the game you are given more alternatives. You have three lives and when you fail completely you are given information about the three languages you failed at recognizing (thus invoking an appropriate feeling of shame and guilt). You don’t get more points for recognizing the correct alternative quicker, you can even replay the clip as many times as you wish.
The audio clips and alternatives are generated randomly. You might be given a set of languages that belong to very different language families, most likely making your task easier. You might also be give a set of very closely related languages, a much harder task. Here’s an example of a potential scenario:
The game has been played 16,511,224 times! This week, the creator of the game, Lars Yencken, made the results available for download. His blog post reveals several interesting things, for instance the likelihood of guessing a language correctly is related to the number of speakers of that language (probably due to the probability of being a native speaker of that language, or people’s exposure to that language, rather than the language adapting to L2 speakers etc.). Out of all the 78 languages currently featured in the game, players find it easiest to recognize French (Romance, Indo-European) and the hardest to tease out is Shona (Bantu, Atlantic-Congo).
There is so much data, that, at some point, every language has been confused with every other language. So, what languages do players confuse the most and are there any patterns? First, some preliminaries about the set-up.
The audio samples
The collection of audio clips has grown since the game was first launched, the game currently features 78 languages. The clips are taken from Australia’s Special Broadcasting Service (SBS), Voice Of America (VOA) and collection of samples aimed at preserving linguistic diversity. SBS and VOA are both broadcasting services of radio and television that aim at providing news in many different languages, reflecting the linguistic diversity of Australia and America respectively. VOA provides broadcasts in 43 languages and SBS in 74. English is not featured in the game even though SBS and VOA broadcast in English.
The clips we’ve heard so far all feature quite informal speech, sometimes even laughter and overlapping dialogue. There are many radio interviews and some speakers are calling in from telephones, reducing the frequency span.
There is a clear bias, for obvious reasons, towards languages that are spoken by a significant population in the United States or Australia.
The players
We don’t know much about the players except for their location, that they know English, can operate a computer and have some sort of interest in language. They might not be citizens of that location or even actually physically there, and we know nothing of their native languages. Still, it is important to keep in mind that we are mainly dealing with computer-operating anglophone Westerners who probably have an interest in languages.
The game has gone viral on certain blogs and newspapers, especially among the nerdier part of the internet. We do not know if there has been any large event where many players have been invited to participate or if there are groups of friends who have become a bit obsessed, if that was the case then that would explain the very high activity in some of the locations.
Potential sources for errors in analysis
We don’t know much about the players nor the speakers of the audio clips, there are many sources for errors.
Player-behaviour: there is the possibility of answering before the time period is up, but you can also wait and replay the clip if you want. Though it isn’t preferable in the game, many players liekly try and answer quickly. The behaviour of the players here is unknown and might affect the results.
Recognizing speakers/clips rather than languages: It is also possible that frequent players learn certain recurring individuals speech and recognizes their voice rather than the language. Players have described this in blog posts about the game.
Lack of data about the speakers: Finally, we should recognize that there might be odd audio samples or speakers with foreign accents that might be problematic.
The confusion
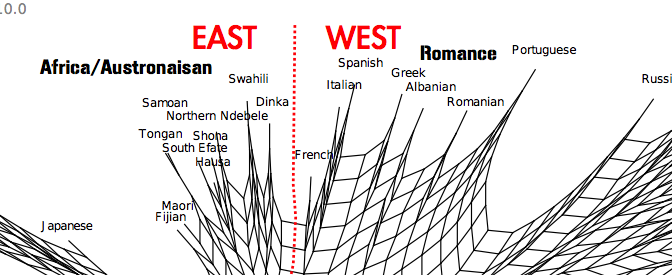
Below is a Neighbour Net graph showing how the languages are related based on what they get confused for in the game, the closer they are the more times have payers mistaken them for each other.
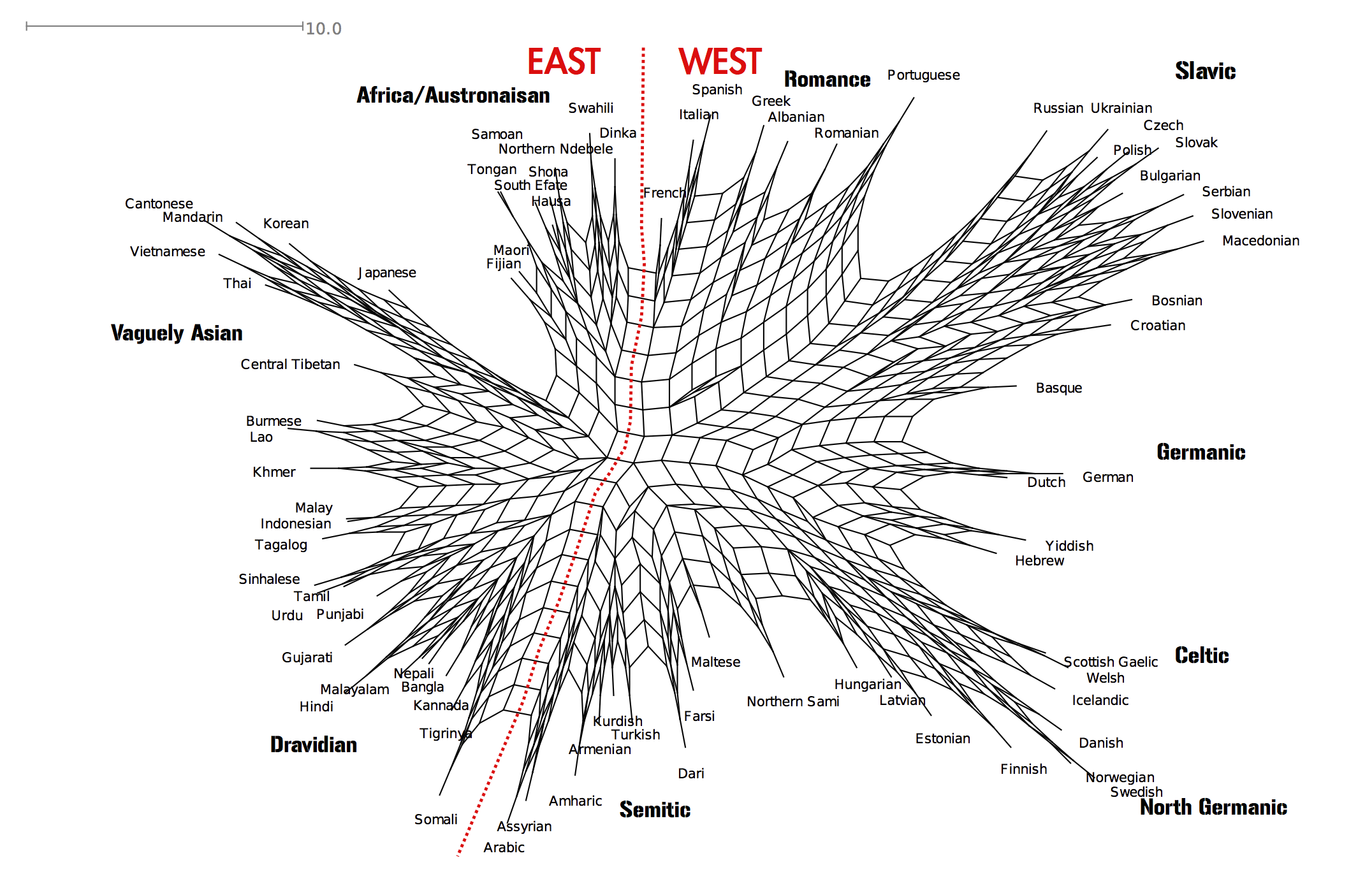
It would seem, to no-one’s surprise, that there are patterns reflecting that more closely related languages are more easily confused with each other. The biggest split in the data appears to be between ‘Western’ languages and Non-Western languages. This makes sense if the majority of the players are from the West.
The Slavic languages form a cluster and so do the Germanic and Romance to a certain degree. There are however exceptions, Portuguese is for example closer to the Slavic than Romance (this conforms to one of the authors intuition). Interestingly, Romanian and Portuguese appear to be further from Spanish and Italian than Albanian and Greek.
As for the non-indo european languages in the sample it would appear to be much more confusion in general and potentially areal patterns emerging. The worst confusion is between African and Austronesian languages. Hindi and Nepali are indo-european languages, but end up closer to their Dravidian geographical neighbours. The most clear example of the geographical associations is perhaps that Mandarin, Cantonese, Korean and Japanese are confounded even though they are very different structurally. Perhaps this is what Mental Floss calls your “Gut Instinct” in their description of the game.
We can also compare graphs made from judgements by players from the West (Europe and North America) and Asia.
Responses from players in Western countries:
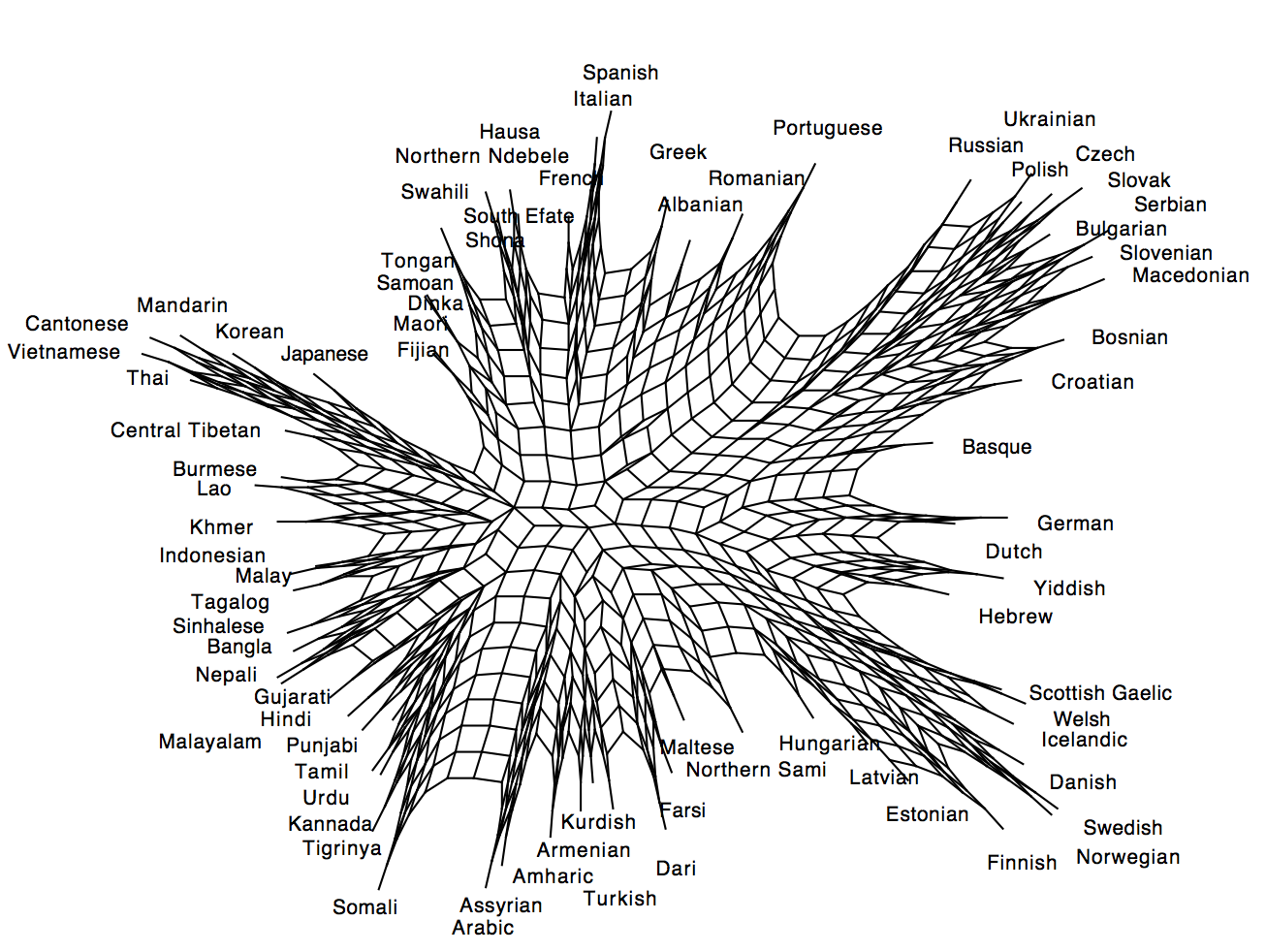
Responses from players in non-Western countries:
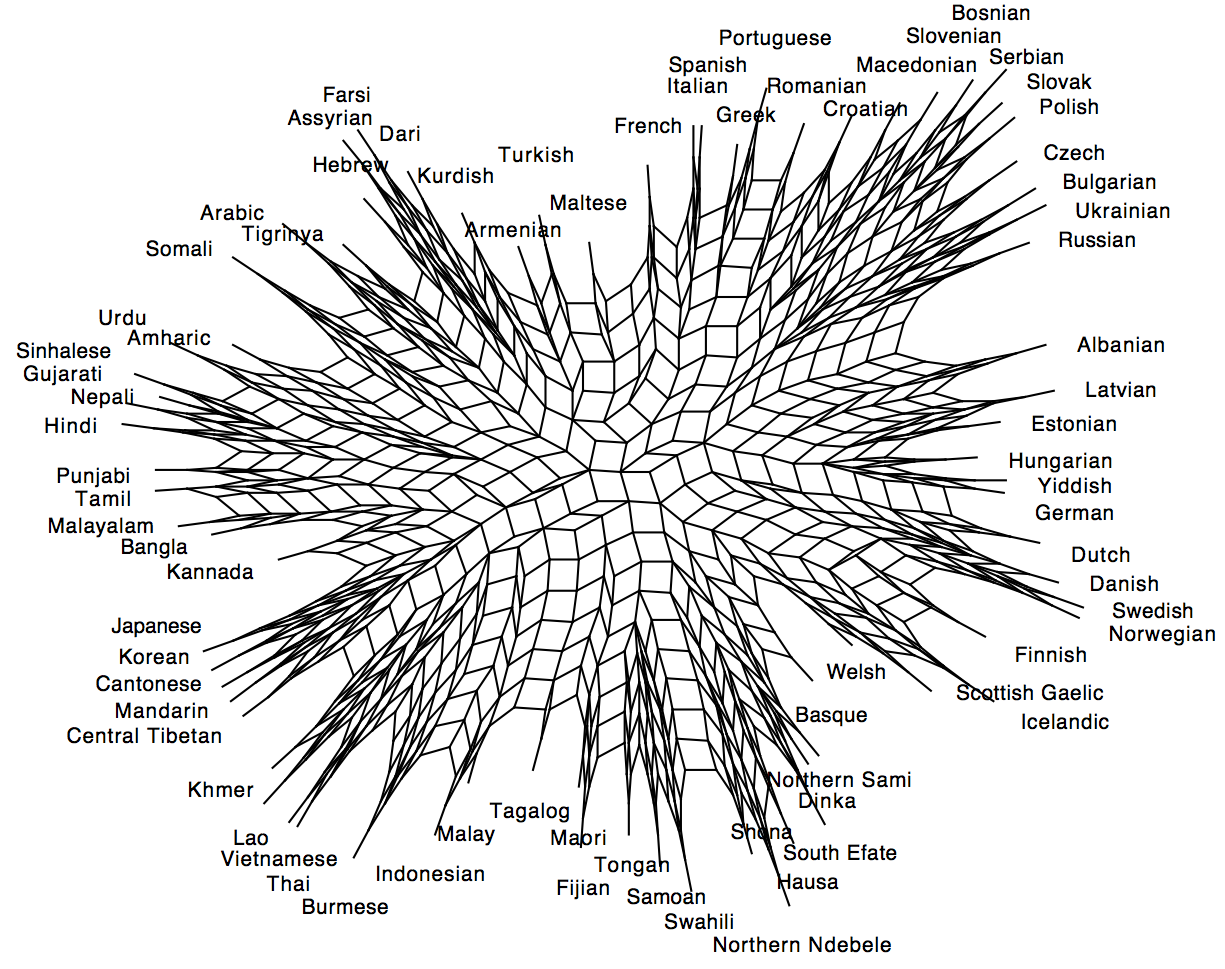
There aren’t big differences here – the cluster of Japanese, Korean, Cantonese and Mandarin are confused in both graphs. But it’s interesting to note that players from the West place Hebrew and Yiddish together with germanic languages, while players from Asia place Yiddish with German, but Hebrew with semitic languages. Yiddish is a germanic language spoken by jews in the diaspora in europe, mainly Germany. Hebrew is a newly revived semitic language spoken mainly by citizens of Israel.
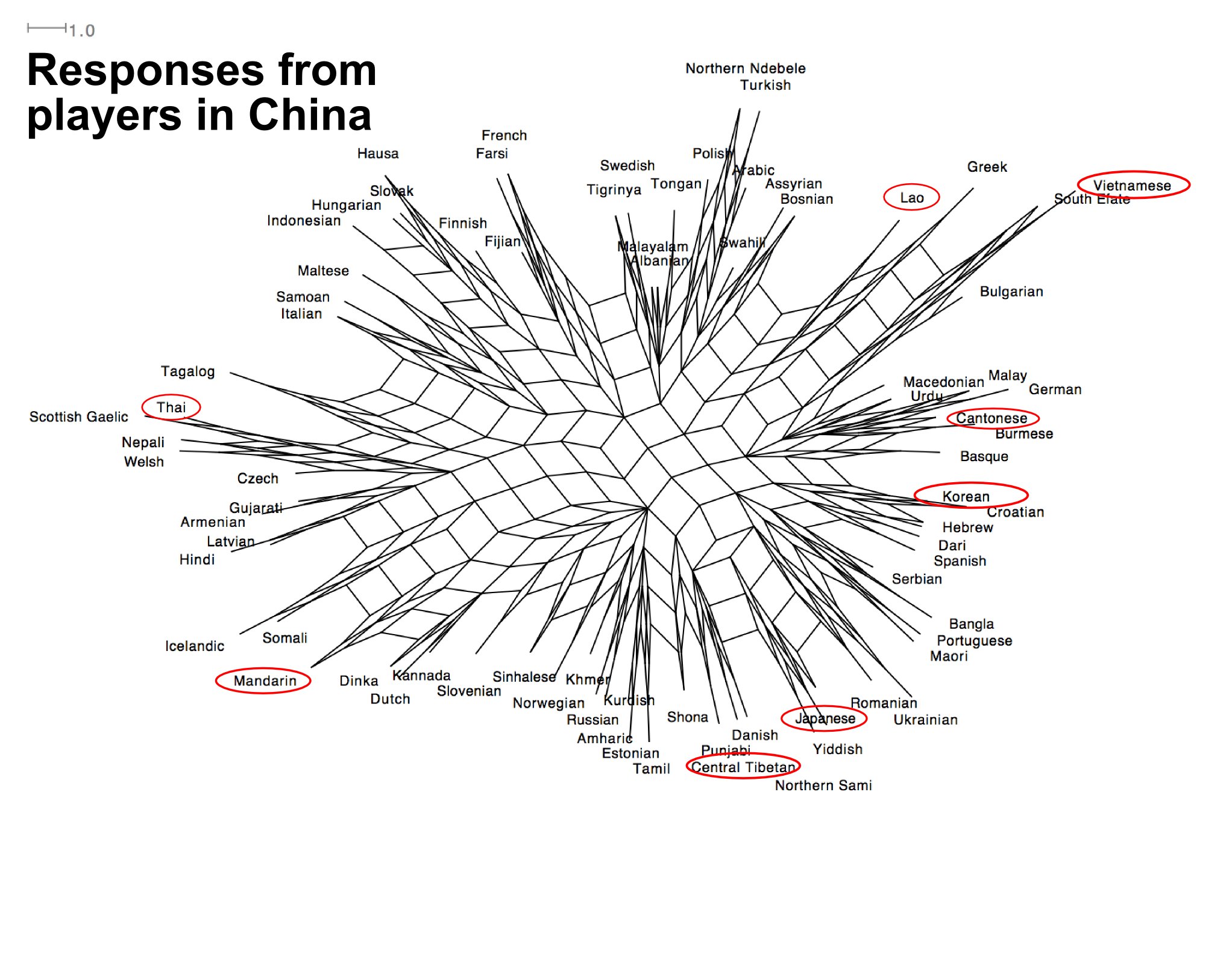
But the general similarity between the graphs above doesn’t mean that people confuse the same language, regardless of their background. Below is the graph produced by the 63,129 responses from players in China (there’s much less data, so the will be more noise). In this graph, the languages in the ‘vaguely Asian’ group in the first graph (highlighted in red) are clearly separated. But so are Swedish and Norwegian. And Welsh and Nepali are often confused, as are Samoan and Italian or Portuguese and Maori. This might seem strange to Westerners, but is no stranger than confusing Japanese and Mandarin for people who are familiar with those languages.
Conclusions
Phonology seems to matters more than lexicon in this task, why else would Portuguese end up as slavic and Hindi among the Dravidians? Westerns confuse languages that they have less experience with with other languages from the same geographical area

Hedvig Skirgård is Swedish and has a name that is hard to pronounce even for her fellow countrymen and that never fails to generate a mention of the great works of JK Rowling. It is actually a compound of two germanic roots, both meaning war/battle. This means that a ‘Hedvig’ is someone who fights, a valkyria/shieldmaiden. This is something she likes to point out in a very serious manner when the owl is brought up for the n-th time.
She did her MA in General linguistics at Stockholm University and is interested in grammatical typology, contact linguistics and linguistic complexity. She is currently occupied with reading grammars of African languages at the Max Planck Institute of Psycholinguistics in Nijmegen and writing posts on Humans Who Read Grammars.
What precisely is the meaning of the grid(?) within the graph and what is the significance of the distance from the “center”?
The graph is a Neighbour Net produced with the program Splitstree (http://www.splitstree.org/). It was originally developed to look at phylogenetic similarity of genetic species. It shows how languages are related both by vertical and horizontal transmission. The further a language is away from others, the easier it is to classify. If there is a lot of ‘webbing’ between languages, it suggests that they are easily confused.