Or, Speculations in Computational Evolutionary Psychology
Note: This version of the post has been revised from an earlier version in which I suggested that the distribution in the first chart followed a power law. Cosma Shalizi checked it for me and it’s not a power law distribution. It’s an exponential distribution.
So, I’ve been exploring Conrad’s Heart of Darkness. In the last two posts I’ve examined one paragraph in the text, the so-called nexus. It’s the longest paragraph in the text, it’s structurally central, and it covers a lot of semantic territory.
OK, but what about the other paragraphs.
What about them?
Aren’t you going to look at them?
Well, yeah, but I sure don’t have time to troll through them like I did the nexus. I mean, that post stretched from here to Sunday.
I get your point. Why don’t you do the Moretti thing?
Moretti thing?
You know, distant reading.
Distant reading? You mean count something? Count what?
How about paragraph length?
What’ll that get me?
I don’t know. Just do it. I mean, you already know that the nexus is the longest paragraph in the text. There must be something going on with that. Mess around and see if something turns up.
* * * * *
I used the MSWord word-count tool to count the words in every paragraph in the text. All 198 of them. One at a time. Real tedious stuff. Then I loaded the results into a spreadsheet and created a bar chart showing paragraph length from longest to shortest:

Whoa!
I didn’t have any hunches about the shape of this distribution before I began this work, much less any actual knowledge about paragraph length in, say, late 19th and early 20th century British fiction, or in any other population of texts for that matter. But I don’t think I’d have guessed a distribution like that. Given that 200 words is a pretty long paragraph – at least it is these days, though I’ve read lots of long paragraphs in 19th century novels – I’d probably have guessed a much flatter distribution with the maximum somewhere above 200 but less than, say, 300. And I’d still make a guess like that for most books. Even for books where paragraphs of 500, 600 words were not uncommon, I’d guess that there’d be a bunch of paragraphs close to one another at the upper end and a pretty slow drop-off to the lower end. Instead we have one paragraph that’s distinctly longer than its nearest neighbors, 1502 vs. 1129 and 1103, and a pretty quick drop to below 400.
I’d like to know two things: 1) what’s typical about the distribution of paragraph length, if indeed anything is typical, 2) In this text, what does that distribution imply about the mind? What’s the mind doing inside of a paragraph in Heart of Darkness that’s different from what it’s doing between one paragraph and the next?
* * * * *
So, what happens between paragraphs?
Well, let’s see. If we’re integrating within a paragraph, what do we do when we’re done? Integration means something like gathering together and wrapping it up in a package. What do we do with the package?
Pass it on? Tell it to someone else, like in a conversation.
Hmmmm . . . I don’t know whether that’s going to get us anything. But let’s give it a try.
Here’s another chart:
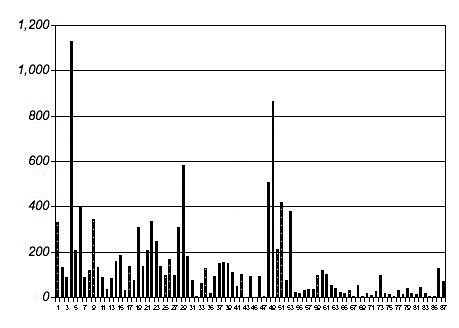
It looks very different from the first one. It’s very, well, spiky. What is it?
It’s paragraph lengths in the third section of the text, the last one.
So the long paragraphs aren’t all bunched together, are they? They’re spread out.
Yes.
Whatever’s going on inside a really long paragraph only has to get done every once in awhile.
Seems that way.
What’s going on there at the end, with all those short paragraphs?
That’s the conversation between Marlow and the Intended.
Oh, he said, she said. Each paragraph is one person speaking.
Yes. And one person passes it on to the other from one paragraph to the next, like you said.
Turn taking.
Hmmmm . . . But you know, this isn’t a REAL conversation. It’s imaginary. It’s all going on inside one person.
Joseph Conrad.
Well, yeah, he wrote the text. But, you know, like the man said, Mistah Conrad—he dead. Now, it’s you and me. We’re the heads in which this conversation’s taking place.
So, those imaginary people, they’re like ‘places’ in the mind, like registers in a computer? And we’re passing information from one to the other.
Something like that.
Well, you know those evolutionary psychologists keep arguing
Don’t they ever!
… keep arguing that the last spurt of brain evolution
The Big One!
Yeah, the big one. It was about social communication. We grew this brain so we could manage our social life.
So, you’re saying that, like, we’ve got this big computational space let’s call it, this computational space just for dealing with one another. And that’s what’s going on in this text, computing in that space and, like, different people are different registers in that space.
Something like that, something like that.
And when we’re looking at these paragraph lengths, we’re looking at traces—maybe even traces in the Derridean sense of the word
No no no no no! Don’t you dare, don’t you dare mix deconstruction with evolutionary psychology. I forbid it. I forbid it. Can’t happen! Don’t do it! The horror! the horror!
… we’re looking at traces of those computations. The barest traces. Just hints.
Except that we CAN look at what’s going on in those paragraphs, each one of them and analyze it.
But what about Moretti, distant reading? You’re the one who brought it up, remember?
Oh, yeah. But, well, aren’t we going to somehow find our way back to the text? I mean, distance is distance, but . . .
I suppose. But now that you got me on the Moretti kick I’d like to run with it for awhile.
OK, so how about another chart and then let’s call it quits.
I’m tired.
OK, I’m getting a little fried too. Here’s another chart. It’s the whole text, all the paragraphs, from beginning to end in order.
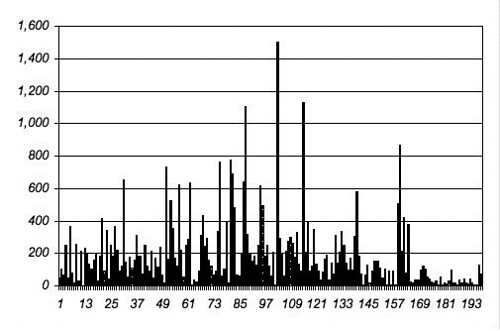
Spiky, spiky, spiky!
Yep, there’s the nexus, right there in the middle. And the final conversation off there to the right. And the distribution before the nexus seems to be a bit different from the one after.
I wonder what’s going on in those other two mega paragraphs, the other ones above 1000?
Well, notice that they’re pretty close to the nexus, one before, the other after. They’re not, like, way on the outside. The whole thing looks a bit like a pyramid.
But what’s going on INSIDE them?
The first one’s about Marlow’s crew on the boat. And the other one, the one after the nexus, that’s about the Russian and his relationship to Kurtz. But we’re getting too close, too close for distant reading.
Yeah, but don’t we have to sooner or later?
Maybe later, but not now.
OK, not now.
Appendix: Authorial Intention
That’s a standard issue in literary criticism: What did the author intend? For some critics it’s crucial. For others, it’s beside the point.
Whatever.
But, did Conrad intend for the distribution of paragraph length in Heart of Darkness to follow a power law? If you mean conscious intention, that seems very unlikely. But those paragraphs were surely written to be as Conrad wanted them. Whatever it was that he was consciously intending, it left an unconscious trace in the text in the form of a most interesting distribution of paragraph lengths.
Update: There’s an interesting conversation about this a Language Log. Nostromo has a similar distribution.
Update 2: Mark Liberman has posted a distribution of paragraph lengths by length for Nostromo and it’s exponential. He’s also done a distribution by order in the text, and that appears to be pretty random. In particular the longest paragraphs are not toward the center. One is toward the beginning, the other toward the end. So, whatever’s “driving” the length distribution seems to be independent of position. (For these two texts.)
* * * * *
There is a lot of this kind of analysis done explicitly in the literature on writing formula screen plays.
“I used the MSWord word-count tool to count the words in every paragraph in the text. All 198 of them. One at a time. Real tedious stuff.”
Cool science. But I get the heebie-jeebies when I read about data analysis being done with MS-word cut-and-paste. If you mark paragraph boundaries with a unique character, something like *!*, a python/perl/awk hacker-friend could crank out that spreadsheet in 15 minutes, and they’d *enjoy* it, and you could use the same method on any text. So, marking the boundaries is tedious, sure, but cut-and-paste is error-prone and difficult to repeat as well as being tedious.
Reason #385 why ever scientist should be friends with >0 hackers 🙂
xian — I’ll look around. I’ve already got a pilot study roughed out.
& paragraph boundaries are already marked in Project Gutenberg text files. Just look for a double line break.
ohwilleke — analysis of shot-length (& perhaps shots/scene) is standard in some corners of the film study community.
Go to Language Log:
http://languagelog.ldc.upenn.edu/nll/?p=3277#comment-130237
Scroll down to a pair of comments by ENKI-][. The second one contains a link to almost 500 plots of paragraph length ordered by text order.