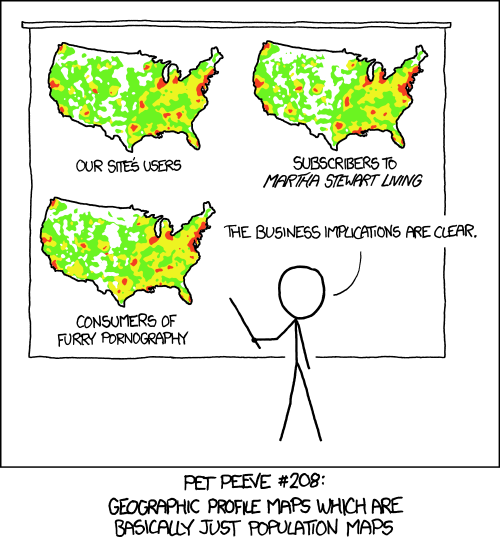
Today’s XKCD was good enough to share. As both Sean’s spurious correlations and my pixel maps are relevant, I figure some of you might get a good laugh, too.
As always, the alt-text might be the best part.
Culture, its evolution and anything inbetween
Today’s XKCD was good enough to share. As both Sean’s spurious correlations and my pixel maps are relevant, I figure some of you might get a good laugh, too.
As always, the alt-text might be the best part.
This is a side project I’ve been working on with Rory Turnbull and Alexis Palmer I recently presented a paper with the same title at the European Association of Computational Linguistics conference, in the Visualisation of Linguistic Patterns Workshop in Avignon (You can read about another paper presented by Gerhard Jäger in this workshop here in Sean’s post). We’ve set up an email group and a website (still a work in progress) after the conference for people wanting to explore language visualisation – hopefully, if you like this or Sean’s post you’ll join us. You can download my paper here, and the slides are available here.
With that having been said, let’s start.
This project is basically preoccupied with understanding how we can use human pattern finding abilities to deal with data where a machine or statistical analysis doesn’t help. Put another way, is there a way of showing language relatedness easily without relying on statistical techniques? And finally, can we use those visualisations to cut down on research time, and to illuminate new areas of research? We tried to approach this problem by using pixel or heat maps on WALS data. As far as we know, this is the first published paper looking at language typology, geography, and phylogeny altogether in one (although there is another paper coming out soon from Michael Cysouw’s ‘Quantitative Language Comparison’ group using similar techniques.) There are other lines of research in this vein, though. One line of recent work brings computational methods to bear on the formation and use of large typological databases, often using sophisticated statistical techniques to discover relations between languages (Cysouw, 2011; Daumé III and Campbell, 2007; Daume ́ III, 2009, among others), and another line of work uses typological data in natural language processing (Georgi et al., 2010; Lewis and Xia, 2008, for example). We are also aware of some similar work (Mayer et al., 2010; Rohrdantz et al., 2010) in visualising dif- ferences in linguistic typology, phylogeny (Mul- titree, 2009), and geographical variation (Wieling et al., 2011). Here, we just try to combine these as well as we can.
The World Atlas of Language Structures has information for 2,678 languages, which is roughly a third of the amount of languages in the world – so, not bad. There are 144 available features – in the actual database, which is freely available, there are actually 192 available feature options. However, only 16% of this 2678 x 192 table is actually filled. Here’s a pretty graph (made before breakfast by Rory).

You can see the ocean at the top of the graph above – clearly New Guinea. Each of these languages is shown by their geographical coordinates. You can also see how good each language is represented in WALS by the size of the circles. We couldn’t use all of these languages as there weren’t enough features to display in a graph. So we cut down WALS to 372 languages that all had at least 30% of their features filled. We then used two different approaches to decide which languages to place near each other in a graph.

One of those approaches, seen above, was to draw a 500km radius around each language, and see how many languages fit in that ring, post-cleaning. There were surprisingly little rings that had enough to fill the graph above – we ended up with around six for the amount of cleaning we did, and even here, above, you can see white spaces where there is no value for that feature for that language. After drawing this ring, we took the centre language – here, Yimas, a Trans New Guinean language – and put the closest language next to it, and then the next closest next to it on the other side, and so on. This is a problem – it means that languages close to each other might be in a totally different cardinal direction – a northern language that is 500 km away from Yimas might be situated next to a southern one. So, for these graphs, you have more pattern-seeking success if you look at the languages in the middle.
Another problem was that the colours don’t actually correspond to anything except within their feature line – so, that there is so much green here doesn’t mean that the features are related – just that many languages share similar correspondances. A final problem was that the selection of features from WALS may seem a bit random – we selected those that fit most. Now, having said those disclaimers, we can still see some cool features in these graphs.
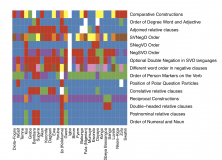
For instance, You’ll notice the red square in the adjectival ordering features. It looks like Kewa, Alambak, Hua and Yagara might be related, either geographically or phylogenetically, as they share that feature. However, if we look at the top stripe, we can see that Alambak is blue, while the others are all orange. This stripe is meant to show language family – so, Alambak is not phylogenetically related. It is possible that it has been influenced by it’s neighbours, then. If you’re interested, here are the language family of the languages in that column: Pink = Border; Red = Trans-New Guinea; Blue = Sepik; Brown = Lower Sepik-Ramu; Purple = Torricelli; Green = Skou; and Orange = Sentani.
Another cool thing one can see in these graphs is checkerboard patterns, like is almost seen in the negative morpheme feature lines. When a feature regularly avoids the other, it shows some sort of negative correspondance. The opposite would be true for features that regularly co-occur.

In order to not just focus on geography, we also did a couple of graphs looking at phylogenetic relations. So, the one above is of the Niger-Congo family, arranged from west to east, because that looked like the most obvious way to plot them, after looking at the geographical relations on WALS – there was less distances between languages on a north to south line than from west to east. These are all in one family, so there’s no bar at the top.
There’s some pretty fun stuff to draw from this graph, too. For instance, not all features have the same diversity. Comparative constructions are a lot more variable than the order of the numeral and the noun. Second, you can see pretty interesting clusters. For instance, the top left seems to cluster quite a bit, as does the bottom right. That means that languages to the west and languages to the east are more like their neighbours, which is expected. Remember that the colours are arbitrary per feature, so the most interesting clusters are defined by not being too noisy, like we see in the top right.
There’s at least one interesting thing to take away from this graph. For Bambara and Supyire, we see clusters of shared features. Given the importance of Bambara for syntactic argumentation – it was one of the languages that challenged the Chomskyan language hierarchy by being shown to follow a context-sensitive grammar (Culy, 1985) – this means that it might be worth looking into Supyire for the same phenomena. And that is the entire point of these visualisations – finding ways of finding research easier, without depending too much on the poor stats that can be scraped from sparse databases.
So, what I’d like to do now is keep running with this idea. Hopefully, this means working with Ethnologue, Multitree for better phylogenetic relations, with Wikipedia for better geographical coordinates, and with WALS more closely for better picking of features and languages. If you have any comments or suggestions, I’d love to hear them.
![]() I went to a good talk almost a year ago at the Interfaces III conference at the University of Kent, and I said I’d write about it, but I never got around to it. The slides have been on my desktop ever since. Now that I have a couple hours to kill on the train coming back from the MPI in Nijmegen, here’s that promise fulfilled. I’m going mostly from the slides, so nicely sent to me, and any errors in the transcription from those are my own.
I went to a good talk almost a year ago at the Interfaces III conference at the University of Kent, and I said I’d write about it, but I never got around to it. The slides have been on my desktop ever since. Now that I have a couple hours to kill on the train coming back from the MPI in Nijmegen, here’s that promise fulfilled. I’m going mostly from the slides, so nicely sent to me, and any errors in the transcription from those are my own.
Vipas Pothipath, Dept. of Thai, Chulalongkorn University
The talk was based on work done at both Chulalongkorm and the MPI for Evo. Anthr. in Leipzig, as well as on (then unpublished, although it might be now) Pothipath’s PhD thesis.
A number classifier is a morpheme typically appearing next to a numeral or a quantifier, categorizing the noun with which it co-occurs on a semantic basis. An example would be the Thai, where tua is the classifier:
These can also be bound morphemes, and can co-occur with ordinal numerals or definitive markers. Pothipath focused on cardinal numerals, and defined numeral classifier constructions (NCCs) as syntactic constructions basically consisting of two core constituents, namely a cardinal numeral X and a numeral classifier Y. This case would be exemplified by the above Thai example, which is just as grammatical when mǎ: ‘dog’ is dropped and only the numeral and classifier remain. Now, based on WALS, these exist in many languages across the world (although not so much in Europe), and are sometimes optional and occasionally obligatory. The sample size was only 56 languages, so there might be more widespread variation. Pothipath claims that the optional/obligatory split shows a possibility of a typologial continuum, and that the evolution can be shown using an evolutionary ladder.
This continuum wouldn’t work if there weren’t different types of NCCs. He outlines these (although the names given here are mostly my own):
Now, among the languages Pothipath looked at, some showed more than one morphological type of NCC. This might be a sign that, under the theory of grammaticalisation, free forms develop into the final lexically closed type of classifier. He goes on to show, using diachronich examples, where different languages show this change. Interestingly, he cites Hurford (2001) as a justification for the affixation of classifiers when they are numerals less than 4, as these behave differently than the other numeral words (as they are used more, among other reasons). I wonder if this has any implications for the broad use of the Swadesh list, especially in cases like in the ASJP database which only has around 40 words per language in it. Later, he also mentions Corbett (2000), as the Animacy Hierarchy influences the lexicalisation of classifiers in Warekena.
The argument stands on the idea that a cline of grammaticality in current systems may show a hypothetical evolutionary ladder, which Pothipath rightfully notes as tentative thikning. He also gives a counter example from Beijing Mandarin, which only had limited scope. But, in essence, this is another cyclic case for grammaticalisation theory. Overall, it’s good research, and adds a bit more to the puzzle.
——
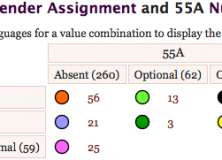
There was at least one open question for me after the talk, which a little WALSing was able to corroborate – is the link between gender assignment and numeral classifiers clear? How do they influence each other? Here’s the WALS markup for that.

As can be seen here, classifiers don’t appear when there is semantic and formal gender assignment. I think that’s interesting. I’d like to take a closer look and see if there are any cases where the numeral classifiers and semantic gender assignments clash – I suspect that they are linked, but that the evolutionary grammaticalisation cycle might be too complex to evolve easily. As I’ve got other evolutionary morphological processes on my mind (cf. my evolang talk), I won’t be looking into this soon, but it is an open question that might have some nice low hanging fruit.
I seem to be the comic poster on this blog, but hey – Mark Liberman often quotes comics on Languagelog, and it’s before breakfast for me. So I feel ok with that.
(Update: I did beat Mark Liberman! By almost 5 hours! CF. http://languagelog.ldc.upenn.edu/nll/?p=3856)
Anyway, I was reading Saturday Morning Breakfast Cereal this morning, a comic that is occasionally quite good, and I came upon this gem. I wonder who exactly he is taking a jibe at with the physicist-turned-linguist mention. Any bets?

I’m glad he said first language, and not protolanguage. Proto-world isn’t the most likely thing we’re going to find – at best, we’ll be able to get half a dozen cognates, like Ruhlen did in 1994. Ruhlen is, of course, not a physicist, but a Greenbergian linguist, so he couldn’t have been the butt of the above joke. For that matter, I can’t be either – not because I am a linguist, but because I don’t believe there was one language, and I think it isn’t theoretically sound to stipulate that there was one language at any point in our history. My argument for this view (which I learned last week isn’t necessarily common) is that a) languages don’t exist outside of their host’s minds, anyway, so language needs to be redefined as a collaborative, shared signalling system b) this wouldn’t have occurred at any point in our history, excepting perhaps for the Adam and Eve time zones c) even then, we’d have different, contacting communities that would keep ‘language’ as such as a constantly changing system that would need to be defined most clearly in relation to the other contrasting systems, and d) even within the group, there would have been considerably idiolectic variation that would have, in my unfounded opinion, been much more rife in early language than today. I’m still working on backing that up theoretically, and hopefully one day with models.
Back to the comic, I hope you didn’t miss the reference to ‘tensors’ as well. Every time I see that word, I think of The Demolished Man, a truly fantastic science fiction book where a key point in the plot is that a man can block out psychics by repeating an annoying commercial meme – Tenser, said the tensor – in his head over and over again. Since we’re talking about science fiction, the comic above also reminds me of that one Star Trek episode where it is revealed that all Kaelon’s must commit mandatory suicide so that they don’t stress society by being elderly, sort of like Sarah Palin’s ‘death panels’.
I was sitting around on a park bench somewhere between Shibuya and Shinjuku, killing time between editing my talk slides and actually going to Evolang in Kyoto. I had worked 17 hours on the computer the day before, and had worked around five hours that morning and afternoon, and this was my time to relax and enjoy the sights. So I took off my headphones, and tried to relax. Sadly, ’twas not to be.
For there were crows. Hundreds of crows. A murder of crows. And they kept quorking. The sound was at first soothing, and then perplexing. You see, a hawk flew by, and suddenly the woods exploded went up in raucous derision, before receding again. Later, they were all quorking at the same time. In short, there was some sort of self-maintenance in both the sound levels and in the timing. It didn’t seem like random effects, and I’m willing to bet it’s not.
I tried to record it, but my computer was nowhere near good enough. To prove my point, try and listen to this: crows. Or take a look at how messy this is.

So, I have two requests for you, O reader: Do you have any long, relatively clean sound files of multiple crows cawing for minutes at a time? Or have you heard of any research on self-regulation of sound volume in corvids? If not, I’ll buy a recorder at some point, and see if I can do this study when I’m next hanging around a constable of ravens again.
Evolang is busy this year – 4 parallel sessions and over 50 posters. We’ll be positing a series of previews to help you decide what to go and see. If you’d like to post a preview of your work, get in touch and we’ll give you a guest slot.
Richard Littauer The Evolution of Morphological Agreement
Every lecture theatre but Lecture Theatre 1, all times except 14:45-15:05, and certainly not on Friday 16th
In this talk I’m basically outlining the debate as I see it about the evolution of morphology, focusing on agreement as a syntactic phenomenon. There are three main camps: Heine and Kuteva forward grammaticalisation, and say that agreement comes last in the process, and therefore probably last in evolution; Hurford basically states that agreement is part of semantic neural mapping in the brain, and evolved at the same time as protomorphology and protosyntax; and then there’s another, larger camp who basically view agreement as the detritus of complex language. I agree with Hurford, and I propose in this paper that it had to be there earlier, as, quite simply put, there is too much evidence for the use of agreement than for its lack. Unfortunately, I don’t have any empirical or experimental results or studies – this is all purely theoretical – and so this is both a work in progress and a call to arms. Which is to say: theoretical.
First, I define agreement and explain that I’m using Corbett’s (who wrote the book Agreement) terms. This becomes relevant up later. Then I go on to cite Carstairs-McCarthy, saying that basically there’s no point looking at a single language’s agreement for functions, as it is such varied functions. It is best to look at all languages. So, I go on to talk about various functions: pro-drop, redundancy, as an aid in parsing, and syntactic marking, etc.
Carstairs-McCarthy is also important for my talk in that he states that historical analyses of agreement can only go so far, because grammaticalisation basically means that we have to show the roots of agreement in modern languages in the phonology and syntax, as this is where they culturally evolve from in today’s languages. I agree with this – and I also think that basically this means that we can’t use modern diachronic analyses to look at proto-agreement. I think this is the case mainly due to Lupyan and Dale, and other such researchers like Wray, who talk about esoteric and exoteric languages. Essentially, smaller communities tend to have larger morphological inventories. Why is this the case? Because they don’t have as many second language learners, for one, and there’s less dialectical variation. I think that today we’ve crossed a kind of Fosbury Flop in languages that are too large, and I think that this is shown in the theories of syntacticians, who tend to delegate morphology wherever it can’t bother their theories. I’m aware I’m using a lot of ‘I think’ statements – in the talk, I’ll do my best to back these up with actual research.
Now, why is it that morphology, and in particular agreement morphology, which is incredibly redundant and helpful for learners, is pushed back after syntax? Well, part of the reason is that pidgins and creoles don’t really have any. I argue that this doesn’t reflect early languages, which always had an n-1 generation (I’m a creeper, not a jerk*), as opposed to pidgins. I also quote some child studies which show that kids can pick up morphology just as fast as syntax, nullifying that argument. There’s also a pathological case that supports my position on this.
Going back to Corbett, I try to show that canonical agreement – the clearest cases, but not necessarily the most distributed cases – would be helpful on all counts for the hearer. I’d really like to back this up with empirical studies, and perhaps in the future I’ll be able to. I got through some of the key points of Corbett’s hierarchy, and even give my one morphological trilinear gloss example (I’m short on time, and remember, historical analyses don’t help us much here.) I briefly mention Daumé and Campbell, as well, and Greenberg, to mention typological distribution – but I discount this as good evidence, given the exoteric languages that are most common, and complexity and cultural byproducts that would muddy up the data. I actually make an error in my abstract about this, so here’s my first apology for that (I made one in my laryngeal abstract, as well, misusing the word opaque. One could argue Sean isn’t really losing his edge.)
So, after all that, what are we left with? No solid proof against the evolution of morphology early, but a lot of functions that would seem to stand it firmly in the semantic neural mapping phase, tied to proto-morphology, which would have to be simultaneous to protosyntax. What I would love to do after this is run simulations about using invisible syntax versus visible morphological agreement for marking grammatical relations. The problem, of course, is that simulations probably won’t help for long distance dependencies, I don’t know how I’d frame that experiment, and using human subjects would be biased towards syntax, as we all are used to using that more than morphology, now, anyway. It’s a tough pickle to crack (I’m mixing my metaphors, aren’t I?)
—
And that sums up what my talk will be doing. Comments welcomed, particularly before the talk, as I can then adjust accordingly. I wrote this fast, because I’ll probably misspeak during the talk as well – so if you see anything weird here, call me out on it. Cheers.
*I believe in a gradual evolution of language, not a catastrophic one. Thank Hurford for this awesome phrase.
Selected References
Carstairs-McCarthy, A. (2010). The Evolution of Morphology. Oxford, UK: Oxford University Press.
Corbett, G. (2006). Agreement. Cambridge, UK: Cambridge University Press.
Heine, B., and Kuteva, T. (2007). The Genesis of Grammar. Oxford, UK: Oxford University Press.
Hurford, J.R. (2002). The Roles of Expression and Representation in Language Evolution. In A. Wray (Ed.) The Transition to Language (pp. 311–334). Oxford, UK: Oxford University Press.
Lupan, G. & Dale, R (2009). Language structure is partly determined by social structure Social and Linguistic Structure.
I was perusing the backlogs of the ecology blog Oikos, when I ran into this post on how to cite blogs. As we pride ourselves here at Replicated Typo on bring changers-of-the-field, movers of literary mountains, sifters through the dregs of boring research, and general key-holders and gatekeepers to evolutionary linguistics and cultural science (arguably justifiable or not) – I figured I should probably put links as to how to cite us here, too.
So, here’s a good link at PLoS about how to cite blogs. – in BibTeX, MLA, Chicago, and APA styles. That’s most of what you’ll probably need.
So, go ahead and get citing.
Full disclosure: I am a struggling academic, and would like more citations. That may or may not have influenced the writing of this post.
Continuing with the theme of ravens, I’d thought I’d quickly point out this pretty cool video of a crow snowboarding down a roof using a small disc it found. When it gets to the bottom, the crow goes back up and does it again. This reminds me of the New Zealand orcas which have learned to surf the waves there. Hopefully, the crow teaches this to its young.
On an only tangentially related note, I’m still trying to decide if this is the use of a tool or not. If so, it’s a major win for dogs.

So, I got a request from a friend of mine to make an abstract on the fly for a poster for Friday. I stayed up until 3am and banged this out. Tonight, I hope to write the poster justifying it into being. A lot of the work here builds on Bart de Boer’s work, with which I am pretty familiar, but much of it also started with a wonderful series of posts over on Tetrapod Zoology. Rather than describe air sacs here, I’m just going to link to that – I highly suggest the series!
Here’s the abstract I wrote up, once you’ve read that article on air sacs in primates. Any feedback would be greatly appreciated – I’ll try to make a follow-up post with the information that I gather tonight and tomorrow morning on the poster, as well.
Laryngeal air sacs are a product of convergent evolution in many different species of primates, cervids, bats, and other mammals. In the case of Homo sapiens, their presence has been lost. This has been argued to have happened before Homo heidelbergensis, due to a loss of the bulla in the hyoid bone from Austrolopithecus afarensis (Martinez, 2008), at a range of 500kya to 3.3mya. (de Boer, to appear). Justifications for the loss of laryngeal air sacs include infection, the ability to modify breathing patterns and reduce need for an anti-hyperventilating device (Hewitt et al, 2002), and the selection against air sacs as they are disadvantageous for subtle, timed, and distinct sounds (de Boer, to appear). Further, it has been suggested that the loss goes against the significant correlation of air sac retention to evolutionary growth in body mass (Hewitt et al., 2002).
I argue that the loss of air sacs may have occurred more recently (less than 600kya), as the loss of the bulla in the hyoid does not exclude the possibility of airs sacs, as in cervids, where laryngeal air sacs can herniate between two muscles (Frey et al., 2007). Further, the weight measurements of living species as a justification for the loss of air sacs despite a gain in body mass I argue to be unfounded given archaeological evidence, which suggests that the laryngeal air sacs may have been lost only after size reduction in Homo sapiens from Homo heidelbergensis.
Finally, I suggest two further justifications for loss of the laryngeal air sacs in homo sapiens. First, the linguistic niche of hunting in the environment in which early hominin hunters have been posited to exist – the savannah – would have been better suited to higher frequency, directional calls as opposed to lower frequency, multidirectional calls. The loss of air sacs would have then been directly advantageous, as lower frequencies produced by air sac vocalisations over bare ground have been shown to favour multidirectional over targeted utterances (Frey and Gebler, 2003). Secondly, the reuse of air stored in air sacs could have possibly been disadvantageous toward sustained, regular heavy breathing, as would occur in a similar hunting environment.
References:
Boer, B. de. (to appear). Air sacs and vocal fold vibration: Implications for evolution of speech.
Fitch, T. (2006). Production of Vocalizations in Mammals. Encyclopedia of Language and Linguistics. Elsevier.
Frey, R, & Gebler, A. (2003). The highly specialized vocal tract of the male Mongolian gazelle (Procapra gutturosa Pallas, 1777–Mammalia, Bovidae). Journal of anatomy, 203(5), 451-71. Retrieved June 1, 2011, from http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=1571182&tool=pmcentrez&rendertype=abstract.
Frey, Roland, Gebler, Alban, Fritsch, G., Nygrén, K., & Weissengruber, G. E. (2007). Nordic rattle: the hoarse vocalization and the inflatable laryngeal air sac of reindeer (Rangifer tarandus). Journal of Anatomy, 210(2), 131-159. doi: 10.1111/j.1469-7580.2006.00684.x.
Martínez, I., Arsuaga, J. L., Quam, R., Carretero, J. M., Gracia, a, & Rodríguez, L. (2008). Human hyoid bones from the middle Pleistocene site of the Sima de los Huesos (Sierra de Atapuerca, Spain). Journal of human evolution, 54(1), 118-24. doi: 10.1016/j.jhevol.2007.07.006.
Hewitt, G., MacLarnon, A., & Jones, K. E. (2002). The functions of laryngeal air sacs in primates: a new hypothesis. Folia primatologica international journal of primatology, 73(2-3), 70-94. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/12207055.
Sound good? I hope so! That’s all for now.
 In what is sure to be a more cited paper than Gould and Lewontin (1979), Douglas Ochs at Columbia University, together with a team of internationally renowned scientists (and probably a few internationally unknown graduate students), has found that all of humanity can be traced back to a large Pliocene-era goat.
In what is sure to be a more cited paper than Gould and Lewontin (1979), Douglas Ochs at Columbia University, together with a team of internationally renowned scientists (and probably a few internationally unknown graduate students), has found that all of humanity can be traced back to a large Pliocene-era goat.
More interesting, for this blog at least, is the finding that the roots of early Indo-European language were in goat bleating. Unfortunately, I couldn’t track down the actual paper myself to find the details of this argument, but if you’re interested, I would suggest looking at the original article where I found this wonderful and groundbreaking study, on the popular peer-reviewed site the Onion.
Full disclosure: This post has been listed in the Irrelevant and Irreverent category, because it probably fits there. We’re not seriously suggesting that humans do in fact go back to a single large goat species in the Pliocene – that’s much too early. Rather, it’s more likely that the goat species was around in the Silurian period. It feasted mainly on trilobites.