
A recent paper in PLOS ONE by Caleb Everett looks at whether geography can affect phoneme inventories. Everett finds that language communities that live at higher altitudes are more likely to have ejective sounds in their phoneme inventories. One of Everett’s hypotheses is that the lower air pressure at higher altitudes makes ejectives easier to produce, and drier climates at higher altitudes “may help to mitigate rates of water vapor loss through exhaled air”. While I don’t have anything against this kind of theory in principle, and I’m not going to comment on the plausibility of this theory, I wanted to check whether the stats held up.
This sounds suspiciously like one of our spurious correlations – links between cultural features that come about by accidents of cultural history rather than being causally related. Although Everett notes that the tests he uses include languages from many language families, there’s no real control for historical descent. James and I have also submitted a paper to PLOS ONE about this phenomenon more generally, and we suggest a few statistical tests that should be applied to this kind of claim. These include comparing the correlation of the variables of interest with similar variables that you don’t think are related, and controlling for historical descent by using, for example, phylogenetic generalised least squares. In this post, I apply these tests.
First, I test whether the link between ejectives and elevation is stronger than the link between elevation and many other linguistic features. I ran a correlation for each variable in the WALS database. Elevation (altitude) does indeed significantly predict the presence of ejectives. Surprisingly, only 2 other variables resulted in stronger predictors of elevation. That is, the presence of ejectives is in the top 1.4% of variables for predicting elevation. The presence of ejectives resulted in a correlation that was significantly stronger than 94.4% of variables (above 1.98 standard deviations). This is surprisingly good news for Everett!
Below is a histogram of the results (F-score of the model fit), with a red line indicating the strength of the ejectives variable :
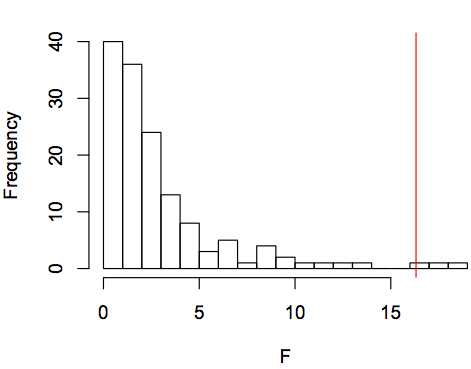
The linguistic variables that gave better results than ejectives were the Order of Object and Verb and the Relationship between the Order of Object and Verb and the Order of Adjective and Noun. I can’t think of a good reason that these would be linked. See below:
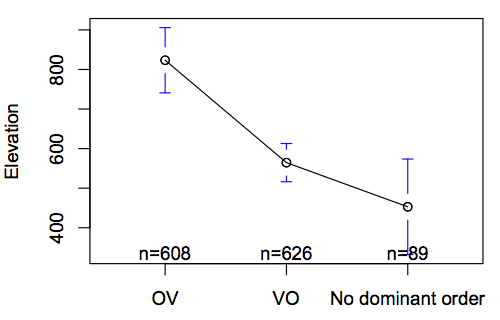
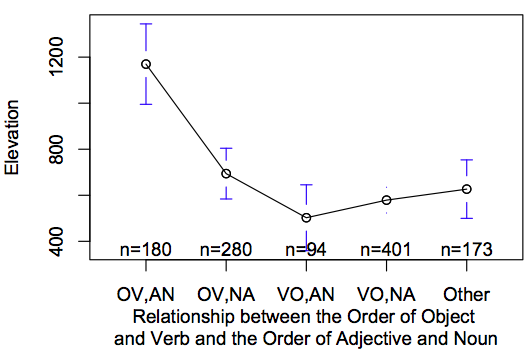
The next test involved controlling for common descent of languages. I built a phylogenetic tree from the linguistic classifications from the Ethnologue. We’re predicting elevation (continuous) given the presence of ejectives (discrete), so we’ll use a phylogenetic generalised least squares test (you can learn more about doing this at the excellent tutorials by Charles Nunn and others, here). This weights the observations by how related they are, given a particular model of trait evolution. The elevation variable has a strong phylogenetic signal (Pagel’s lambda = 0.3, sig. > 0, p<0.00001; sig. different from 1, p<0.00001), so we’ll use Pagel’s covarience matrix.
Surprisingly, the correlation holds up, even when controlling for phylogeny (491 languages, df = 419, residual df = 489, estimated lambda = 0.2787271, coef = 358.9542, t = 3.51, p = 0.0005). Edit: If you use ejectives as the dependent variable, the result is similar (estimated lambda = 0.8169142, coef = 0.00003975, t = 2.42, p = 0.0157).
I’d like to make two points: First, this kind of analysis is easy to do, and makes the test more rigorous (I did the above analyses at Singapore airport). Secondly, while the stats might hold up, this kind of approach can only point towards future research, rather than supplying definitive proof of the hypothesis. It’s an interesting proposal, and I look forwards to some modelling or experimental evidence.
EDIT:
The phylogenetic tree assumed languages within families evolved over 6,000 years and there was a common ancestor for all language families 60,000 years ago. You can see a diagram of the tree here, with WALS codes.
The altitude data I used comes from the 90-meter NASA database (SRTM3), extracted using the GPS Visualiser, while Everett uses surveys by Google Earth and ArcGIS v. 10.0. I checked some points and there are very slight differences in the order of a few meters.
Thanks for this analysis. I have a question though. Why did you pot elevation as the dependent variable? Theoretically this makes no sense to me, wouldn’t it make more sense to make a logistic regression with “has.ejectives” as a binary dependent variable and elevation as independent? When I run the model I do get a strong correlation. I guess that since there are only two variables it’s not very relevant, but I’m still curious.
Good point. The reason I did it this way was mainly because I was adapting some code for another project. If you run it the other way around, so that the presence of ejectives is the dependent variable, then the correlation is still significant (estimated lambda = 0.8169142, coef = 0.00003975, t = 2.42, p = 0.0157). This makes the effect look weaker, but it’s still difficult to dismiss.
Thanks very much for this very illuminating analysis. Everett’s hypothesis doesn’t strike me as totally outlandish, but, leaving to one side the possibility that pure chance is probably(?) the best explanation of this correlation, an alternative hypothesis strikes me as considerably more plausible: that there is a truly causal link between a language having ejectives and its speakers living in regions of relatively little contact between speakers of different languages, of which high-altitude regions would be just one type. Actually the (hypothesized) causal link is probably better stated the other way round: that contact tends to make languages lose ejectives, if they ever had them. The reasoning here would be that a language’s having (contrastive) ejectives implies that it has a large consonant inventory, which implies that it does not have a history of significant numbers of people having learnt it as a second language, since this tends to lead to the elimination of typologically rare features.
Crosschecking correlations between high altitude and many other linguistic variables (handily available in WALS), as you have done here, is clearly necessary. But how feasible do you think it would be to crosscheck presence of ejectives with numerous other cultural variables, among them something like ‘geographical accessibility’, or some reasonable proxy thereof?
Great post. It is not entirely clear for me what are the F-scores calculated in the first figure; would you please share an external link on the procedure or perhaps comment a bit on what you did there? Thanks a lot
The f-scores come from an ANOVA with elevation as the dependent variable and the linguistic feature as the independent variable. I did it this way so that all types of variables could be compared, although adapting the test for the particular variable would be a good idea.
That’s a very good point. I’m not sure I know of a variable that measures geographic isolation that’s easy to get hold of and is not related to altitude. However, you could look at the number of languages in the surrounding region, or distance to the nearest language – you could work that out via the information in WALS. That would give you a proxy of how much language contact there was.
Oh, I see. So, how did you converted the continuous variable altitude into a discrete one? Which criterion did you use? Thanks Sean, and I hope to see more of this in the future!
The elevation is still continuous. So, if there are two factors to a linguistic variable, it’s essentially a t-test.
Hi Chris, I followed your suggestion and looked at some proxies for langauge contact: see here
Great, sorry for the dumb questions and keep on the good work!