“Chomsky still rocks!” This comment on Twitter refers to a recent paper in PNAS by David M. Gómez et al. entitled “Language Universals at Birth”. Indeed, the question Gómez et al. address is one of the most hotly debated questions in linguistics: Does children’s language learning draw on innate capacities that evolved specifically for linguistic purposes – or rather on domain-general skills and capabilities?
Lbifs, Blifs, and Brains
Gómez and his colleagues investigate these questions by studying how children respond to different syllable structures:
It is well known that across languages, certain structures are preferred to others. For example, syllables like blif are preferred to syllables like bdif and lbif. But whether such regularities reflect strictly historical processes, production pressures, or universal linguistic principles is a matter of much debate. To address this question, we examined whether some precursors of these preferences are already present early in life. The brain responses of newborns show that, despite having little to no linguistic experience, they reacted to syllables like blif, bdif, and lbif in a manner consistent with adults’ patterns of preferences. We conjecture that this early, possibly universal, bias helps shaping language acquisition.
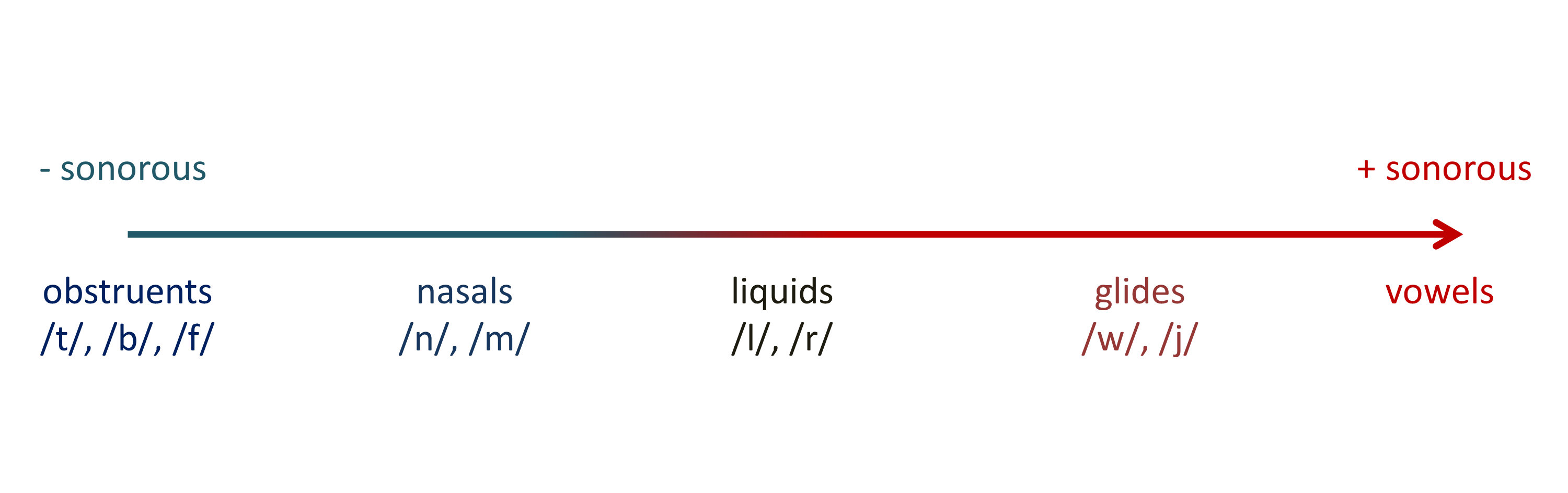
More specifically, they assume a restriction on syllable structure known as the Sonority Sequencing Principle (SSP), which has been proposed as “a putatively universal constraint” (p. 5837). According to this principle, “syllables maximize the sonority distance from their margins to their nucleus”. For example, in /blif/, /b/ is less sonorous than /l/, which is in turn less sonorous than the vowel /i/, which constitues the syllable’s nucleus. In /lbif/, by contrast, there is a sonority fall, which is why this syllable is extremely ill-formed according to the SSP.
A simplified version of the sonority scale
In a first experiment, Gómez et al. investigated “whether the brains of newborns react differentially to syllables that are well- or extremely ill-formed, as defined by the SSP” (p. 5838). They had 24 newborns listen to /blif/- and /lbif/-type syllables while measuring the infant’s brain activities. In the left temporal and right frontoparietal brain areas, “well-formed syllables elicited lower oxyhemoglobin concentrations than ill-formed syllables.” In a second experiment, they presented another group of 24 newborns with syllables either exhibiting a sonority rise (/blif/) or two consonants of the same sonority (e.g. /bdif/) in their onset. The latter option is dispreferred across languages, and previous behavioral experiments with adult speakers have also shown a strong preference for the former pattern. “Results revealed that oxyhemoglobin concentrations elicited by well-formed syllables are significantly lower than concentrations elicited by plateaus in the left temporal cortex” (p. 5839). However, in contrast to the first experiment, there is no significant effect in the right frontoparietal region, “which has been linked to the processing of suprasegmental properties of speech” (p. 5838).
In a follow-up experiment, Gómez et al. investigated the role of the position of the CC-patterns within the word: Do infants react differently to /lbif/ than to, say, /olbif/? Indeed, they do: “Because the sonority fall now spans across two syllables (ol.bif), rather than a syllable onset (e.g., lbif), such words should be perfectly well-formed. In line with this prediction, our results show that newborns’ brain responses to disyllables like oblif and olbif do not differ.”
How much linguistic experience do newborns have?
Taken together, these results indicate that newborn infants are already sensitive for syllabification (as the follow-up experiment suggests) as well as for certain preferences in syllable structure. This leads Gómez et al. to the conclusion “that humans possess early, experience-independent linguistic biases concerning syllable structure that shape language perception and acquisition” (p. 5840). This conjecture, however, is a very bold one. First of all, seeing these preferences as experience-independent presupposes the assumption that newborn infants do not have linguistic experience at all. However, there is evidence that “babies’ language learning starts from the womb”. In their classic 1986 paper, Anthony DeCasper and Melanie Spence showed that “third-trimester fetuses experience their mothers’ speech sounds and that prenatal auditory experience can influence postnatal auditory preferences.” Pregnant women were instructed to read aloud a story to their unborn children when they felt that the fetus was awake. In the postnatal phase, the infants’ reactions to the same or a different story read by their mother’s or another woman’s voice were studied by monitoring the newborns’ sucking behavior. Apart from the “experienced” infants who had been read the story, a group of “untrained” newborns were used as control subjects. They found that for experienced subjects, the target story was more reinforcing than a novel story, no matter if it was recited by their mother’s or a different voice. For the control subjects, by contrast, no difference between the stories could be found. “The only experimental variable that can systematically account for these findings is whether the infants’ mothers had recited the target story while pregnant” (DeCasper & Spence 1986: 143).
In a perhaps even more well-known study, Mampe et al. (2009) found that newborns’ cry melodies are influenced by the main intonation pattern of their respective surrounding language. In their experiment, Mampe and colleagues investigated the cry patterns of 30 French and 30 German newborns. They found that
“French newborns preferentially produced rising (low to high) contours, whereas German newborns preferentially produced falling (high to low) contours (for both melody and intensity contours).” (Mampe et al. 2009: 1994)
This is consistent with the predominant intonation patterns in both languages. Rather than invoking an innate, specifically linguistic bias, Mampe et al. (2009: 1996) conclude that “the observed performances are based on biological predispositions, particularly for melody perception and production.”
Gómez et al.’s findings are very much in line with the above-mentioned studies, which are complemented by numerous other studies indicating that infants show remarkably efficient language-learning propensities already at birth (cf. Werker & Gervain 2013: 910). But do these studies really reveal specifically linguistic propensities? Do they even lend support to the existence of an innate faculty of language?
Concerning the more general finding that human infants prefer to listen to human speech over similarly complex nonspeech sounds (Voloumanos & Werker 2007), Rosen & Iverson (2007) argue that this bias “arises from the strikingly different saliency of voice melody in the two kinds of sounds” used in the aforementioned study. More generally, one could argue that speech in general is fundamentally different from other kinds of sound – and it has to be in order to “signal signalhood”, to borrow Scott-Phillips et al.’s (2009) term, and in order to stand out against other kinds of noise.
Werker & Gervain (2013: 911), while seeing findings such as those discussed above as evidence for experience-independent, innate biases, concede that these findings “cannot rule out a role for listening experience in utero“. They argue that experience-dependent abilities complement experience-expectant ones, i.e. “capabilities that are simply waiting for almost guaranteed environmental input to be set” (Werker & Gervain 2013: 910).
While hardly anyone would disagree with the idea that language learning indeed draws on innate, “experience-expectant” capabilities along with experience-dependent ones, the question remains to what extent those are specifically linguistic. This leads us back to Gómez et al.’s interpretation of their neurophysiological findings. As pointed out above, they see their results as evidence for “the presence of biological linguistic constraints on language acquisition.” (p. 5837) Hence, the Sonority Sequencing Principle (SSP) is seen as a both biological and specifically linguistic constraint. However, they provide no arguments why this constraint is specifically linguistic in nature – apart from the fact that it seems to be universal-ish and can thus, from a generativist point of view, be seen as a factor shaping the human language faculty.
An alternative account
From a non-generativist, non-modular, and usage-based perspective, this line of reasoning is of course less than convincing. Instead, it seems fairly obvious that the SSP arises through articulation (and perhaps also perception) biases. /blif/ is easier to pronounce than /lbif/. This issue has been explicitly addressed by Berent et al. (2008) who presented Korean speakers with items of the /blif/ and /lbif/ type. The gist is that Korean doesn’t allow for two consonants at the beginning of a word. Since Korean tends to “repair” such patterns in loanwords with a schwa-like vowel, the experimenters expected that the participants would misperceive /lbif/ as a disylabbic word, /le.bif/. If the supposedly universal preference for greater sonority distance is active in their linguistic knowledge, they should more often misperceive a monosyllabic (non-)word as a disyllabic one when sonority distance is smaller. This is exactly what Berent et al. found. Since they controlled for a broad variety of factors such as the participants’ proficiency in second languages that allow initial CC sequences, they interpret their results as “consistent with the hypothesis that adult human brains possess knowledge of universal properties of linguistic structures absent from their language.” (Berent et al. 2008: 5324)
As you might expect, I am still not convinced. Berent et al. (2008: 5323) admit that participants might engage in some kind of covert articulation, “(a possibility for which we have no evidence)”. Although the classic “Translation Hypothesis” states that visual items are “translated” by covert articulation to an acoustic form (probably even obligatorily, cf. Eiter & Inhoff 2008), while auditory items, being already in acoustic form, are stored in short-term memory independently of articulation (cf. Levy 1971: 130), Pickering & Garrod (2013: 15) cite much evidence pointing towards covert imitation in (auditory) language comprehension. This is consistent with the usage-based hypothesis that imitation plays a pivotal role in language acquisition (cf. e.g. Tomasello 2003). The Motor Theory of Speech Perception (e.g. Liberman et al. 1967) suggests that speech perception “is based on a recoding of the sensory input in terms of articulatory gestures” (Schwartz et al. 2012: 337). While a strong version of this hypothesis cannot be upheld since “[p]eople with severely impaired speech motor capacity often have intact speech perception” (Hurford 2014: 99), the assumption that covert imitation does play a role in language comprehension and hence influences language users’ preference patterns even in purely auditory language perception seems not too far-fetched.
According to Berent et al. (2008: 5323), such explanations cannot account for their finding that participants respond slower and less accurately to the disyllabic counterparts of well-formed monosyllables (e.g. /belif/ as counterpart of /blif/) than to disyllabic counterparts of ill-formed monosyllables (e.g. /lebif/ as counterpart of /lbif/). According to their interpretation, this is due to the participants’ “persistent aversion to these ill-formed sequences, even when they are not physically present”. In a usage-based perspective, however, one could argue that /blif/ violates the Korean constraint prohibiting CC onsets less gravely than /lbif/ since /l/ is closer to the [+sonorous] pole than /b/. Usage-based theory assumes that phonological categorization works very much like all other kinds of categorization (cf. Taylor 2003), and in categorization, everything’s a matter of degree. (Note in this regard that “Korean does allow initial CG sequences where G is a glide” (Berent et al. 2008: 5321)). Thus, it seems reasonable to assume that /blif/ is perceived as less obviously “wrong” by Korean speakers – drawing on their linguistic experience with a significant predominance of CV onsets – than /lbif/, which might cause the delayed (and distorted) response to the well-formed counterpart.
In a more recent study, Berent et al. (2014) performed an fMRI study with English native speakers, again using the same kind of stimuli.
“Results showed that syllable structure monotonically modulated hemodynamic response in Broca’s area, and its pattern mirrored participants’ behavioral preferences. In contrast, ill-formed syllables did not systematically tax sensorimotor regions — while such syllables engaged primary auditory cortex, they tended to deactivate (rather than engage) articulatory motor regions.”
The fact that the ill-formed structure differentially engages traditional language areas compared to its well-formed counterpart is taken as evidence that these constraints have to be attributed to the language faculty itself rather than to sensory-motor pressures. However, they concede that phonological rules are grounded in the sensorimotor system. Remarkably, “ill-formed monosyllables were associated with deactivation, rather than activation” of articulatory motor areas. Again, in a usage-based perspective, it is not very surprising that nonwords consisting of syllables that do occur in English (or are at least similar to syllables that do occur in English) are processed differently by English native speakers than nonwords consisting of infelicitous syllables.
Berent et al. (2014) are very much aware that their findings can be interpreted in different ways and that some of them have to be treated with caution. As is well-known, the function of different brain areas and, hence, the significance of neuroimaging results is still a matter of considerable debate. In my view, their paper still does not provide convincing evidence that “the brain is hardwired for language.” What all studies mentioned in this post do provide, however, is abundant support for the Sonority Sequencing Principle. Thus, perhaps the most crucial question is: Why does the SSP exist, and why does it apply in so many different languages?
How do (phonological) universals emerge?
In a usage-based perspective, languages are learnt via generalizations and abstractions over actual instances of language use (cf. Goldberg 2006; Taylor 2012). As pointed out above, language learning is tightly connected to categorization; language itself is seen as “a structured set of meaningful categories” (Geeraerts & Cuyckens 2007: 5). What makes language learnable are skewed frequencies – just as in the case of any other category system: As Rosch (1978: 29) observes, “the perceived world is not an unstructured total set of equiprobable co-occuring attributes”. The same goes for language. Concerning phonology, Taylor (2012: 161) points out:
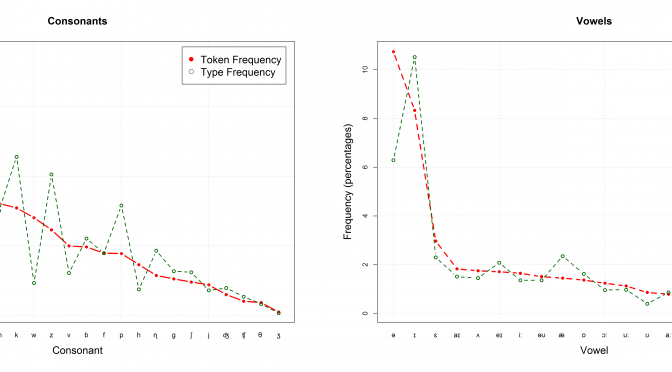
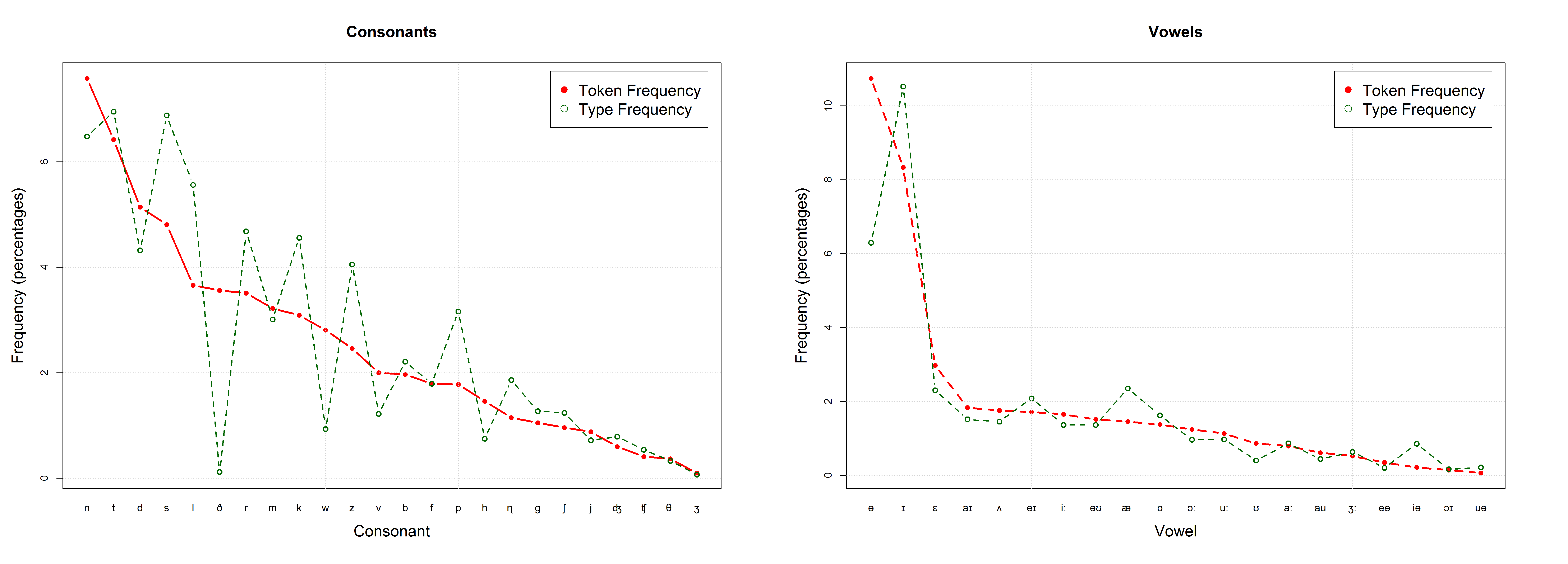
One might suppose that a language will tend to make the most efficient use of the available phonological resources, with each of its vowels and consonants being exploited to an equal degree in the make-up of its words and morphemes. This, however, is not what we find. Skewed frequencies are manifest in each of the ninety-five languages surveyed by Tambovtsev and Martindale (2007), the skewing being particularly evident in languages with large phoneme inventories.
Skewed frequencies in phonology. Data from Fry (1947), based on an analysis of 17,000 sounds of transcribed British English text; cited in Taylor (2012: 162f.). “Token frequencies refer to the occurrences of the sounds in the text comprising the corpus; type frequencies are the number of occurrences in the word types in the text.”
It is therefore not too surprising that languages do not exploit all possible sound combinations in all different syllable positions. Strong universals such as the SSP can be assumed to arise due to “evolutionarily stable strategies, local minima as it were, that are recurrent solutions across time and space” (Evans & Levinson 2009: 444). This ties in with Christiansen & Chater’s (2008) assumption that in the course of cultural evolution, languages adapt to domain-general learning and processing biases. A very similar account has already been proposed by Deacon (1997: 107): “Over countless generations languages should have become better and better adapted to people”. Deacon (1997: 117-120) further demonstrates with the example of focal color terms how even tiny biases can produce near-universal language features. “If tiny biases can produce near-universal language features, then imagine what strong biases can do!” (Deacon 1997: 120) It can be assumed that the SSP has emerged due to such domain-general biases, although the exact nature of these biases has yet to be determined. Bickerton (2013: 113) has recently taken issue with Christiansen & Chater’s position, arguing that “it logically entails that earlier versions of language must have been harder to learn to produce and understand than present-day versions!” But this criticism clearly misses the point. Christiansen and Chater do not assume that earlier stages of language, or a protolanguage, were more complex than present-day languages (e.g. in terms of morphology and syntax). However, it does make sense to assume that in its early stages, language was less structured than modern language – just because it was less complex. If you only have a limited number of units, you don’t need a lot of structuring principles to memorize them efficiently. As language gets more complex, it has to adapt to its learners: “Languages are under powerful selection pressure to fit children’s likely guesses, because children are the vehicle by which a language gets reproduced.” (Deacon 1997: 109)
These considerations are also consistent with Lbevins’ Blevins’ (2004) hypothesis that phonological universals arise through non-teleological diachronic processes of phonetic change. Taken together, then, the idea that newborn infants’ different responses to well-formed vs. ill-formed syllable structures provide evidence for innate language universals might mix up cause and effect in two respects: On the one hand, the assumption that the infants’ responses are experience-independent possibly underestimates the role of prenatal linguistic experience. Phonological preferences (effect) are seen as hardwired in the brain (cause). According to the alternative and, in my view, more plausible account, by contrast, the “hardwiring” of linguistic features (effect) occurs as a result of early learning processes (cause), which in turn benefit from the fact that languages have evolved a broad variety of statistical preferences to be highly learnable. On the other hand, universals are seen as factors that shape the human language faculty. The alternative account proposed here suggests that, on the contrary, it is language itself as well as the domain-general processes that shape language that give rise to language universals.
Of course, this does not mean that we can rule out the existence of language-specific biological adaptations (cf. also Christiansen & Chater 2008). However, given the fact that seeming universals of language are mere statistical tendencies and given a variety of findings in the domains of language acquisition and change (cf. e.g. Croft 2001; Tomasello 2003), it has become increasingly clear that the assumption of a domain-specific language faculty is highly questionable. In addition, a more pessimistic stance on the age-old “nature” vs. “nurture” question would hold that it simply cannot be answered because “nurture” can never be eliminated as a confounding factor. However, that is all the more reason to do away with theoretical preconceptions and non-falsifiable assumptions such as Universal Grammar. Instead, we should try to find answers to the key question what (a) language actually is in a bottom-up, data-driven way.
Having seen a couple of his talks, I do admit that Chomsky still rocks. But when it comes to linguistics, I prefer evidence from actual language data to the theories and hypotheses of an intellectual rock star.
References
Berent, Iris; Lennertz, Tracy; Jun, Jongho; Moreno, Miguel A.; Smolensky, Paul (2008): Language Universals in Human Brains. In: Proceedings of the National Academy of Sciences of the United States of America 105, 5321–5325.
Berent, Iris; Pan, Hong; Zhao, Xu; Epstein, Jane; Bennett, Monica L.; Deshpande, Vibhas; Seethamraju, Ravi Teja; Stern, Emily (2014): Language Universals Engage Broca’s Area. In: PLoS One 9. doi 10.1371/journal.pone.0095155.
Bickerton, Derek (2013): More than Nature Needs. Language, Mind, and Evolution. Harvard: Hardvard University Press.
Blevins, Juliette (2004): Evolutionary Phonology. The Emergence of Sound Patterns. Cambridge: Cambridge University Press.
Christiansen, Morten H.; Chater, Nick (2008): Language as Shaped by the Brain. In: Behavioral and Brain Sciences 31, 489–558.
Croft, William (2001): Radical Construction Grammar. Syntactic Theory in Typological Perspective. Oxford: Oxford University Press.
Deacon, Terrence W. (1997): The Symbolic Species. The Co-Evolution of Language and the Brain. New York, London: Norton.
DeCasper, Anthony J.; Spence, Melanie J. (1986): Prenatal Maternal Speech Influences Newborns’ Perception of Speech Sounds. In: Infant Behavior and Development 9, 133-150.
Eiter, Brianna M.; Inhoff, Albrecht W. (2008): Visual Word Recognition is Accompanied by Covert Articulation. Evidence for a Speech-Like Phonological Representation. In: Psychological Research 72.
Evans, Nicholas; Levinson, Stephen C. (2009): The Myth of Language Universals. Language Diversity and its Importance for Cognitive Science. In: Behavioral and Brain Sciences 32, 429–492.
Fry, Dennis (1947): The Frequency of Occurrence of Speech Sounds in Southern English. In: Archives Néerlandaises de Phonétique Expérimentale 20, 103–106.
Geeraerts, Dirk; Cuyckens, Hubert (2007): Introducing Cognitive Linguistics. In: Geeraerts, Dirk; Cuyckens, Hubert (eds.): The Oxford Handbook of Cognitive Linguistics. Oxford: Oxford University Press, 3–21.
Goldberg, Adele E. (2006): Constructions at Work. The Nature of Generalization in Language. Oxford: Oxford University Press.
Gómez, David Maximiliano; Berent, Iris; Benavides-Varela, Silvia; Bion, Ricardo A.H.; Cattarossi, Luigi; Nespor, Mariana; Mehler, Jacques (2014): Language Universals at Birth. In: Proceedings of the National Academy of Sciences of the United States of America 111, 5837-841. doi 10.1073/pnas.1318261111
Hurford, James R. (2014): The Origins of Language. A Slim Guide. Oxford: Oxford University Press.
Levy, Betty Ann (1971): Role of Articulation in Auditory and Visual Short-Term Memory. In: Journal of Verbal Learning and Verbal Behavior 10, 123–132.
Liberman, Alvin M.; Cooper, F. S.; Shankweiler, D. P.; Studdert-Kennedy, Michael (1967): Perception of the Speech Code. In: Psychological Review 74, 431–461.
Mampe, Birgit; Friederici, Angela D.; Christophe, Anne; Wermke, Kathleen (2009): Newborns’ Cry Melody Is Shaped by Their Native Language. In: Current Biology 19, 1994-1997. doi 10.1016/j.cub.2009.09.064
Pickering, Martin J.; Garrod, Simon (2013): An Integrated Theory of Language Production and Comprehension. In: Behavioral and Brain Sciences 36, 329–347.
Rosch, Eleanor (1978): Principles of Categorization. In: Rosch, Eleanor; Lloyd, Barbara B. (eds.): Cognition and Categorization. Hillsdale, NJ: Erlbaum, 27–48.
Rosen, Stuart; Iverson, Paul (2007): Constructing Adequate Non-Speech Analogues. What is special about speech anyway? In: Developmental Science 10, 165-168.
Schwartz, Jean-Luc; Basirat, Anahita; Ménard, Lucie; Sato, Marc (2012): A Perceptuo-Motor Theory of Speech Perception. In: Journal of Neurolinguistics 25, 336–354.
Scott-Phillips, Thomas C.; Kirby, Simon; Ritchie, Graham R.S. (2009): Signalling Signalhood and the Emergence of Communication. In: Cognition 113, 226–233.
Tambovtsev, Yuri; Martindale, Colin (2007): Phoneme Frequencies Follow a Yule Distribution. In: SKASE Journal of Theoretical Linguistics 4. www.skase.sk/Volumes/JTL09/pdf_doc/1.pdf.
Taylor, John R. (2003): Linguistic Categorization. 3rd ed. Oxford: Oxford University Press.
Taylor, John R. (2012): The Mental Corpus. How Language is Represented in the Mind. Oxford: Oxford University Press.
Tomasello, Michael (2003): Constructing a Language. A Usage-Based Theory of Language Acquisition. Cambridge, London: Harvard University Press.
Voloumanos, Athena; Werker, Janet F. (2007): Listening to Language at Birth. Evidence for a Bias for Speech in Neonates. In: Developmental Science 10, 159–164.
Werker, Janet F.; Gervain, Judit (2013): Speech Perception in Infancy. A Foundation for Language Acquisition. In: Zelazo, Philip David (ed.): The Oxford Handbook of Developmental Psychology. Vol. 1: Body and Mind. Oxford: Oxford University Press, 909–925.
3 thoughts on “The Myth of Language Universals at Birth”
Interesting paper. The link to Chomsky is surprising though. It is an enormous leap from the SPP (even if it were an innate learning bias) to Chomsky’s recent ideas about FLN (faculty of language in the narrow sense), which is hypothesized to be either empty or to consist solely of recursion.
Virtually everyone agrees that there needs to be some prestructuring of our mental abilities. The question is: is it uniquely linguistic? As Stefan Hartmann points out here, the authors of this paper do not show this. Additionally, they appear to overlook the possible role of experience even at this early age.
Quoting Levinson 2006: “What is right about simple nativism is that it insists on the prestructuring of our mental abilities. What is wrong about it is that it minimizes or ignores the role of ontogeny and learning, and minimizes the very stuff of our evolutionary success, namely, the cultural variation that is our special system for rapid adaptation to differing environments.”
Levinson, Stephen C. 2006. Introduction: The evolution of culture in a microcosm. In Evolution and culture, ed by. Stephen C. Levinson and P. Jaisson, 1–41. Cambridge, MA: MIT Press.
I would love to have a PDF copy of Gomez’s study, if anybody has one?
Interesting paper. The link to Chomsky is surprising though. It is an enormous leap from the SPP (even if it were an innate learning bias) to Chomsky’s recent ideas about FLN (faculty of language in the narrow sense), which is hypothesized to be either empty or to consist solely of recursion.
Virtually everyone agrees that there needs to be some prestructuring of our mental abilities. The question is: is it uniquely linguistic? As Stefan Hartmann points out here, the authors of this paper do not show this. Additionally, they appear to overlook the possible role of experience even at this early age.
Quoting Levinson 2006: “What is right about simple nativism is that it insists on the prestructuring of our mental abilities. What is wrong about it is that it minimizes or ignores the role of ontogeny and learning, and minimizes the very stuff of our evolutionary success, namely, the cultural variation that is our special system for rapid adaptation to differing environments.”
Levinson, Stephen C. 2006. Introduction: The evolution of culture in a microcosm. In Evolution and culture, ed by. Stephen C. Levinson and P. Jaisson, 1–41. Cambridge, MA: MIT Press.
I would love to have a PDF copy of Gomez’s study, if anybody has one?