
In scientific prognostication we have a condition analogous to a fact of archery—the farther back you draw your longbow, the farther ahead you can shoot.
– Buckminster Fuller
The following remarks are rather speculative in nature, as many of my remarks tend to be. I’m sketching large conclusions on the basis of only a few anecdotes. But those conclusions aren’t really conclusions at all, not in the sense that they are based on arguments presented prior to them. I’ve been thinking about cultural evolution for years, and about the need to apply sophisticated statistical techniques to large bodies of text—really, all the texts we can get, in all languages—by way of investigating cultural evolution.
So it is no surprise that this post arrives at cultural evolution and concludes with remarks on how the human sciences will have to change their institutional ways to support that kind of research. Conceptually, I was there years ago. But now we have a younger generation of scholars who are going down this path, and it is by no means obvious that the profession is ready to support them. Sure, funding is there for “digital humanities” and so deans and department chairs can get funding and score points for successful hires. But you can’t build a profound and a new intellectual enterprise on financially-driven institutional gamesmanship alone.
You need a vision, and though I’d like to be proved wrong, I don’t see that vision, certainly not on the web. That’s why I’m writing this post. Consider it sequel to an article I published back in 1976 with my teacher and mentor, David Hays: Computational Linguistics and the Humanist. This post presupposes the conceptual framework of that vision, but does not restate nor endorse its specific recommendations (given in the form of a hypothetical program for simulating the “reading” of texts).
The world has changed since then and in ways neither Hays nor I anticipated. This post reflects those changes and takes as its starting point a recent web discussion about recovering the history of literary studies by using the largely statistical techniques of corpus linguistics in a kind of digital archaeology. But like Tristram Shandy, I approach that starting point indirectly, by way of a digression.
Who’s Kemp Malone?
Back in the ancient days when I was still an undergraduate, and we tied an onion in our belts as was the style at the time, I was at an English Department function at Johns Hopkins and someone pointed to an old man and said, in hushed tones, “that’s Kemp Malone.” Who is Kemp Malone, I thought? From his Wikipedia bio:
Born in an academic family, Kemp Malone graduated from Emory College as it then was in 1907, with the ambition of mastering all the languages that impinged upon the development of Middle English. He spent several years in Germany, Denmark and Iceland. When World War I broke out he served two years in the United States Army and was discharged with the rank of Captain.
Malone served as President of the Modern Language Association, and other philological associations … and was etymology editor of the American College Dictionary, 1947.
Who’d have thought the Modern Language Association was a philological association?
And just what is philology? Does anyone do it anymore? Again from the Wikipedia:
Philology is the study of language in written historical sources; it is a combination of literary studies, history and linguistics. It is also more commonly defined as the study of literary texts and written records, the establishment of their authenticity and their original form, and the determination of their meaning.
Michael Bérubé, the current president of the MLA, tells me that the discipline adopted philology in the early days “because teachers and scholars in the modern languages were concerned that their subjects were too ‘soft’ compared to Latin and Greek, and Anglo-Saxon philology was the hardest, most obscure thing they could offer” (private email).
Kemp Malone was a superb philologist who had achieved a legend-sized reputation before World War II. He remained active after retiring from Hopkins in 1956 and was in charge of etymology for the Random House Dictionary of the English Language, which was first published in 1966, the year the French landed in Baltimore and rocked the house in the famous structuralist conference: The Languages of Criticism and the Sciences of Man. But who among the current crop of literary luminaries would be caught dead doing anything so pedestrian as riding herd on etymology for a dictionary?
There’s a brief biographical sketch accompanying his papers at The Johns Hopkins Library. It’s worth a quick read.
They did things differently back in days of old, which were pretty much gone by the time I entered Hopkins in the 60s. By that time language study, aka linguistics, and literary studies had pretty much parted ways, with linguistic study increasingly taking up residence in autonomous departments rather than existing as an aspect of anthropology or of philology. There was a brief flirtation with linguistics during the early structuralist phase of the linguistic turn—remember that?— but it didn’t last. The linguistic turn had little use for linguistics as a discipline and certainly not with Chomskian and post-Chomskian linguistics. No as capital-Tee Theory rounded the turn and headed toward the finish line linguistics was completely forgotten.
But it’s creeping back in a strange form. I’m not thinking of cognitive rhetoric—which is very like traditional rhetoric in conceptual mode, only with a different set of figures. I’m thinking of so-called digital humanities, which utilize a variety of computational techniques, corpus linguistics among them.
Corpus Linguistics,
like everything, has a history. And while it has roots in computational work done in the 1950s and 60s it didn’t really flourish until somewhat later, but I’m not clear about the chronology (which could be checked easily enough, but it really doesn’t matter for my argument). It relies on two things: 1) large bodies of digital texts (the corpus) and 2) the ready availability of significant computing power. Those two things began emerging in linguistics in the 1970s and migrated to the humanities somewhat later, though the humanities does have it’s own computational tradition that does extend back into the 1960s.
There are lots of things one can do with a big pile of words and lots of computing power. We’re interested in techniques for content analysis. So, we’ve got a million, two million words of text: what’re people talking about in those texts? Let’s start with the observation that words that consistently occur together in the same textual environment probably have some stable semantic relationship. This does not, however, necessarily imply that they have the same or even similar meanings.
Such pairs as (1) bat and ball, (2) horse and track, (3) star and galaxy, do not mean the same or even similar things; nor do such pairs as (4) bat and cave, (5) horse and buggy, (6) star and Hollywood. But if they occur together consistently in a given body of texts, that may be an indicator of a topic under discussion in those texts. In my (completely made-up) examples, those topics might be (1) baseball, (2) racing, (3) astronomy, (4) exploration, (5) 19th Century life, and (6) entertainment.
And so we have a technique called topic analysis. I’m not at all expert in its operational details, nor have I played around with it. Pretty much all I know is that, like most corpus work, you need a large body of texts and some powerful computing power, power that, during my undergraduate and graduate years, existed only in large systems housed in air-conditioned rooms with raised floors and controlled access. Comparable, if not more, computing power is now common in desktop and laptop computers.
I also know that, like most such techniques, you’ve got to set certain parameters when you run the analysis and that the results you get will depend on those parameters. The process isn’t one where you press the ON button, let ‘er rip, and you get your results in a few minutes or hours, whatever. You play around with your materials, set various parameters and see what kind of results you get. Do they make some kind of sense? If not, change the parameters and try again.
The interpretive process is critical. The software, in effect, proposes topics. They may or may not make sense. If they do, the sense they make may be illusory. If they don’t, there may be something deep there anyhow, but you haven’t yet figured out how to think about it. The topics thus identified may not correspond to what we think of as typical topics. That doesn’t mean they don’t exist as coherent verbal/conceptual entities.
In topic analysis the software’s likely to identify each topic by a number. Along with that number you’ll have a list of the words that belong to that topic. It’s up to you to figure out why those words seem to occur together in a given corpus.
Thus we’re back to our old friend interpretation. But not in the sense of hermeneutics and its familiar circle. You aren’t interpreting a single text, or related group of texts, against some sense of authorial intention. You are interpreting an artifact computed over a large collection to texts which, more likely than not, were written by many people over a possibly long period of time. Physicists have to interpret dots and lines on a photographic plate; digital humanists have to interpret topic lists. In both cases they’re trying to figure out what’s going on out there in the world that produces such traces when examined by this procedure.
As Natalia Cecire recently remarked, it’s one thing to use topic modeling as a tool for discovery, where you then read specific texts and draw your own conclusions, the old-fashioned way, if you will. However,
I feel like I’d want to understand topic modeling inside and out before I would ever attempt to use the topic model itself to make an argument, though. Not just the math, but a convincing theory of what the math has to do with the structure of (English) language, which I’m not altogether sure is something that has been nailed down by anyone. “It works” is not persuasive to me; I need to understand why; I need to understand what it is, exactly, that’s “working. And that depth of understanding (that is, the understanding I would need to attempt justification) would involve an enormous learning curve for me…
I suspect she is right that the understanding she seeks has not quite “been nailed down by anyone” and I fear that really nailing it down will take us deep into the cognitive sciences. But I can’t help but wonder whether or not Kemp Malone, with his deep philological learning, would have been in a better position to undertake such study than any students trained in the last half-century or so. The study of literature is ipso facto the study of language, but linguistics education was jettisoned from literary studies years ago.
Digital Archaeology: Topics in PMLA
Meanwhile, exciting work is being done. One bit of that work is the occasion for this essay.
Over at The Stone and the Shell Andrew Goldstone and Ted Underwood report preliminary results of investigation of PMLA (Publications of the Modern Language Association), the oldest journal of philology and, ahem, literary studies in the United States. The linguistics aspect of philology has had so few pages in the journal since the middle of the 20th century (if not before) that almost no one in the profession realizes that PMLA began as a philology journal nor do they realize that academic literary studies shares institutional roots with linguistics. These days scholars think of PMLA and the disciplines it serves as being about literature. Period.
Using slightly different computational tools, Goldstone and Underwood have undertaken topic analyses of articles in PMLA. Think of it as digital archaeology: what topics appeared when in the journal over its century and a quarter run? The post contains a number of results; a number of topics have been identified and tracked over time. Philology is only one of them. The others are interesting as well. But, for this that and the other reason, I want to focus on philology.
This graph depicts the behavior of Goldstone’s topic 40 over time:
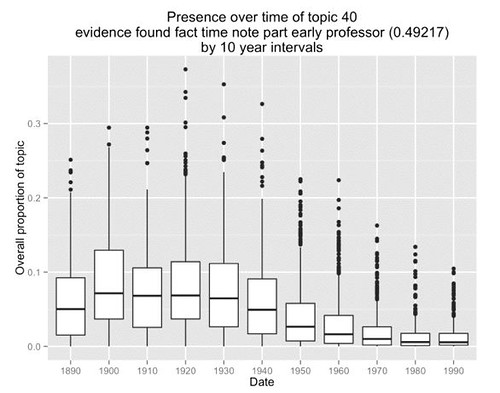
As the legend at the top of the graph indicates, topic 40 consists of the words: evidence found fact time note part early professor. As you can see, first of all, the occurrence of the topic is relatively continuous; we don’t see any sharp breaks or discontinuities in the distribution. Second, the distribution is relatively higher from 1890 through 1940 and then tapers off from 1950 to 1980, where the topic almost disappears.
The topic doesn’t identify itself as philology: in itself it is just that list of co-occurring words. Nor do Goldstone and Underwood talk about the topic as philology in their main discussion, where its significance appears as something of a mystery. But subsequent discussion reveals that Goldstone and Underwood had been thinking and talking about philology. The online discussion also included a number of other scholars: Jonathan (Goodwin), Scott Weingart, Matt Wilkens, and me.
I reported that, in a discussion about the profession with my undergraduate teacher and mentor from Hopkins, Richard Macksey, he’d pointed out that philology was a major concern in the early decades of the profession and that the interpretation of textual meaning didn’t become a focal concern until the mid-20th Century. I also remarked, as I’ve indicated above, that it’s only after World War II that linguistics became well-recognized as an independent discipline. Prior to that it had been coupled with anthropology or philology.
And I did one other thing. I ran a query on Google Ngram on the words “philology” and “linguistics.” Why? Given that the institutionalization of linguistics as an academic discipline is relatively recent, I wanted to see if the world itself increased in use as the institutionalization proceeded.
But I had something else in mind. I wanted independent verification of Goldstone’s result. Independent verification reduces the likelihood that a result is merely an artifact of the analytic technique.
So, on the one hand, a Google Ngram query is a much cruder indicator than topic analysis. It’s only two words, not a constellation of co-occurring words. But it’s also run over a different corpus. Goldstone and Underwood are looking at a corpus of consisting of articles in a single academic journal. The Google corpus consists of every book the digital behemoth could lay its digital hands and eyes on. That’s a much bigger slice of the intellectual, and not-so-intellectual, world.
Here’s what I got:

The philology curve (blue) looks pretty much like Goldstone’s. And the linguistics curve rises sharply after 1950, which is pretty much what I expected. In fact, the rise of that linguistics curve looks a bit like the rise on a curve that Underwood got for his topic 109 (structure pattern form unity order structural whole central) which he and Goldstone characterized as “new Critical interest in formal unity” (quotes in the original). So we’ve got the appearance of the world “linguistics” tracking the institutionalization of the discipline running in parallel with the emergence of the New Criticism as a dominant methodology.
And then there’s Scott Weingart’s remark:
I was curious how ‘philology’ played out over the years in Literature studies in particular, using JSTOR’s DfR Literature sub-category, which is available here: Philology ratio per year. Though it’s quite a slow decline, it seems to fit your narrative.
Though I don’t know quite what the “DfR Literature sub-category” is, here’s Wingart’s graph:
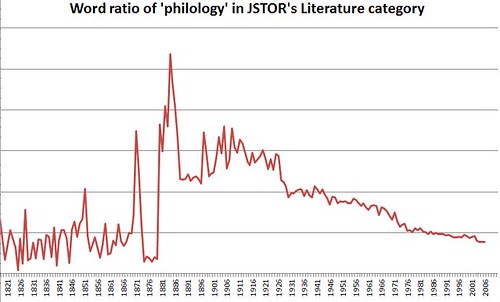
It starts back in 1821 and peaks in the 1880s, right after the MLA was founded and about the time MLN (Modern Language Notes) started publication out of the newly founded The Johns Hopkins University (yes, that initial “the” is part of the official name). It then shows a steady decline more or less down to the present.
Now we’ve got three ‘snapshots’ of what appears to be aspects of the same beast.
Let’s return to Goldstone and Underwood. Here’s a graph of Goldstone’s topic 38: time experience reality work sense.
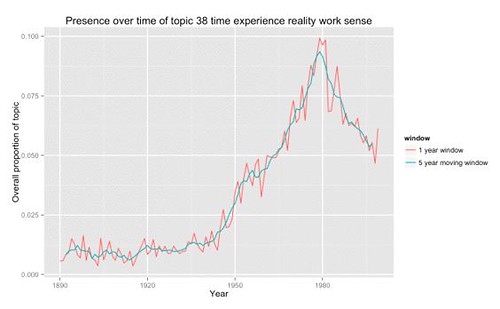
If you read their full post you’ll see it tracks Underwood’s topic 109. Moreover, the rise is pretty much at the same time as the rise in the ngram curve for linguistics.
Are these three curves, Goldstone 38, Underwood 109, and Ngram linguistics, tracking the SAME THING? If so, what could that be?
Let me take a wild-ass guess and suggest that they ARE tracking the same thing, namely that differentiation of philology into linguistics on the one hand, and literary interpretation on the other. Literary interpretation, in turn, became something called “Theory” within the profession. Furthermore, as linguistics developed in the 1960s it became part of the emergence of an interdisciplinary movement known as cognitive science. And I’ve got an old post in which I track the parallel development of cognitive science and (literary) Theory through some major publications.
What about them apples?
Stalking the Wild Meme: Cultural Evolution
Well, what about them? After all, the existence of philology as a genealogical predecessor of contemporary literary studies is pretty well known. Bérubé tells me that Gerald Graff’s Professing Literature (which I’ve not read) discusses it. And the rise of contemporary linguistics is a well-known story. This clever computational sleuthing hasn’t really recovered anything new, has it?
Nothing yet.
But let’s not be so hasty to reject it. For one thing, despite the existence of Graff’s book, it’s not at all clear to me that the existence of the philological past means much to anyone these days. As Underwood remarked in the discussion
This is not actually something that lit people know about our history. We tend to imagine that the constitution of our discipline as “interpretive” rather than “evidentiary” is a time-honored “humanistic value.”
Here “evidentiary” is an index of philology. So Underwood’s suggesting that, in misconceiving its past, the profession is misconceiving its “nature” or “essence” (my words).
A number of the discussants brought up the point that literary scholars tend to think of the profession’s history as a succession of more or less discontinuous schools but that the topic modeling shows evidence of more or less continuous change along side of or underlying that narrative. The standard narrative, of course, is based on the sort of anecdotal case-by-case evidence that is typical of humanistic scholarship about intellectual history. This is not to demean that work, after all, until recently that’s all anyone could do: read a whole bunch of stuff and make the best case you can by presenting example after example after example.
Matt Wilkens offered this observation:
On the question of periodization, I don’t disagree with the renewed emphasis on continuity. But I’d add that small and/or gradual shifts aren’t a priori incompatible with models of punctuated equilibrium. Sometimes small absolute differences really matter. And then there’s what Marx or Jameson would call the reality of the illusion; standing narratives about eras and schools affect the kinds of work we do, even when they don’t line up with the objects they’re supposed to organize.
But none of this is to disagree with the original point, which was that we’re getting a much better feel for the kinds and magnitudes of changes that have happened in past literature and scholarship.
On that last sentence: Yes, I believe so. I also want to emphasize this point: “standing narratives about eras and schools affect the kinds of work we do, even when they don’t line up with the objects they’re supposed to organize.”
That is, if we think that the profession is centered on a sort of interpretation that is disjoint with a philological concern for language structure, then that’s how we’re going to conceive the future of the profession: more interpretation. But if we realize that, hey! back in the old days our predecessors worried a lot about the details of language, then maybe the profession will entertain a new interest in carefully constructed linguistic description and analysis. And maybe scholars will even be open to new kinds of evidence, like that from corpus linguistics.
And then there’s the general discussion about the discontinuities of periodization on the one hand, and continuous change on the other. Matt’s not the only one who spoke to that. We all did.
And there are ways of thinking about that, that is, ways of thinking about how continuous change in underlying “stuff” can give rise to discontinuities in observed phenomena. Given that corpus linguistics is based on mathematical techniques perhaps future work could call on catastrophe theory in conceptualizing intellectual change.
As mathematician Steven Strogatz puts it:
The ancient proverb about the straw that broke the camel’s back is meant as a lesson about the nature of precipitous change. It reminds us that big changes don’t necessarily require big forces. If the conditions are just right (or wrong), a tap can push a system over the brink.
In the mid-20th century, mathematicians updated this proverb by turning it into a picture, a graph of the interplay between input and output, force and response. A field known as catastrophe theory explores how slow continuous changes in the force applied to a system (like the gradually increasing load on a camel’s back) can trigger rapid discontinuous jumps in its response.
Strogatz then goes on to illustrate catastrophe theory with examples from the study of sleep behavior and economics.
Remarkably, scientists in disparate fields have uncovered this same general picture, again and again. It’s there in the thermodynamics of water heated past the boiling point; in the optical focusing that creates intense webs of light at the bottom of a swimming pool; in sociological models of mobs and mass movements like the sudden revolts that became the Arab Spring; and in ecological models for the collapse of a forest from an outbreak of insects.
In some of these cases (boiling water, optical patterns), the picture from catastrophe theory agrees rigorously with observations. But when applied to economics, sleep, ecology or sociology, it’s more like the camel story — a stylized scenario that shouldn’t be taken for more than it is: a speculation, a hint of something deeper, a glimpse into the darkness.
Are Goldstone, Underwood, and colleagues giving us a glimpse of a glimpse into the darkness? We don’t really know, but I’m betting that they are.
Consider this recent article in Critical Inquiry by Bernard Dionysius Geoghegan: From Information Theory to French Theory: Jakobson, Lévi-Strauss, and the Cybernetic Apparatus. Geoghegan looks at the period during and immediately after World War II when Jakobson, Lévi-Strauss and Lacan picked up ideas about information theory and cybernetics from American thinkers at MIT and Bell Labs.
Those ideas led to deconstruction and post-modernism when they come back across the Atlantic and crashed into the New Criticism in the middle and late 1960s—think of that 1966 structuralism conference at Johns Hopkins. But another stream from those currents hits land in Boston where it becomes Chomksian linguistics, which in turn drove the expansion of linguistics into a fully autonomous intellectual disciplines.
At this point we are, of course, thinking about considerably more than a single journal in a single discipline. While Jonathan Goodwin is looking at topics in other literary theory journals, we need to look at topics in linguistics, anthropology and probably psychology and even philosophy, and who knows what else. We’re now thinking about a very large “region” of scholarly activity.
What I’m thinking is that we’re looking at the cultural analog to biological evolution, that is, cultural evolution. The elements in those topics are something like genes—Richard Dawkins coined the term “meme” for that purpose, though most of what’s been said in the name of memes is regrettably simplistic. While the discontinuous periods, schools of thought, and institutional formations—e.g. New Criticism, structuralism, deconstruction, the linguistic turn, post-modernism, etc.—may be something like cultural phenotypes. So we have continuous change in the “cultural genome” being expressed as discontinuous “species,” that is populations of “phenotypes”, in formal academic life.
Of course, these techniques can certainly be applied to the primary texts themselves, as these and other scholars are doing. And there, as Ted Underwood remarked in the discussion, we’re going to have the same problem of continuity and discontinuity:
We rely on a discretized rhetoric, most obviously by organizing history into “periods”. But our insistence on discontinuity goes beyond period boundaries to a whole rhetoric of “turns,” “movements,” “formations,” “case studies,” etc. Because we just haven’t had any way to represent continuous change.
Well, now we do. We can graph the time course of topics in a body of texts. Just how we relate those slow-moving flows of collective mentation to the perceived emergence of movements, that’s an issue we have to face with literature itself and not just critical examination of it. And, as I’ve indicated above, there are mathematical techniques for dealing with this kind of problem.
Finally, I’d like to offer a comment on the trope of distance in reading. In using that trope we say that the New Critics, and others, practiced CLOSE reading, and Franco Moretti has proposed DISTANT reading, then topic analysis is somewhere in the MIDDLE, though, frankly, I think “reading” is a poor term that should be retired from use in any sense but the common one, that of simply reading a text without the supplement of hermeneutic or other apparatus. But that’s another issue, one I’ve considered in a number of posts, including Distant Reading in Lévi-Strauss and Moretti.
Through a Glass Distantly
Let us assume, then, if only for the sake of argument, that these methods are in fact quite useful and will give us new kinds of information about literary phenomena, not only academic discourse about literature, but as Underwood indicated, about literature itself. What’s that future look like?
Here’s what I see when I put on my Spectacles of Utopian Prophesy: A bunch of scholars of varying skills working together on a given corpus. Some are doing topics models and such on the whole corpus and place results in a common online repository. Others look things over and “matters of concern” are identified (to use a phrase from Bruno Latour) while others investigate them by good old-fashioned reading: Select a sample of texts a read them to see what’s actually going on.
Depending on this that and the other some of this joint work will prove really interesting and articles will be written that combine the corpus computational work with the more traditional sleuthing; those articles will be signed by two, three, a half-dozen on so authors, whatever it takes to get the work done. These articles will be discussed by the wider community etc etc more corpus work more actual reading etc etc and in time some of these matters of concern will make their way toward becoming what Latour calls “matters of fact” (everyone else simply calls them facts).
Meanwhile, still other investigators will be developing computational tools that are more fine-grained (‘smart’) than corpus tools, but not so sophisticated as, you know, actual human readers.
If THAT, or something like it, is where we want to go, then we’re going to have to change the way we conduct intellectual business. Not only are we going to have to become conversant in sophisticated computational techniques, but we’re going to have to reorganize the way we do our work.
When will busy scholars have the time needed to learn these new techniques? But it’s not only the computational techniques of corpus linguistics, as Natalia Cecire indicated. What about learning some linguistics in order better to understand what these tools are doing? Not only that, but such knowledge would facilitate working with scholars in the cognitive sciences in developing ideas and concepts for understanding and interpreting the results produced by these tools.
While I’ve read a fair amount of web discussion about the need for theory in connection with digital humanities, those discussions all presuppose that critical theory, and it’s sclerotic variants in capital-Tee Theory, is the only relevant body of theory. The presumption is that digital humanists really ought to be using off-the-shelf (OTS) theory in interpreting their results.
Color me skeptical, deeply skeptical.
As the discussion about continuity and discontinuity indicates, we don’t have OTS theories that can deal with these results. I think that we are going to have to develop a new body of theory to deal with these and other results. While I mentioned cultural evolution above, the term cultural evolution is a bit of a fancy term piggy-backing on biology for its concepts. We have a long way to go to understand culture as an evolutionary phenomenon.
Digital humanists HAVE to be in the thick of developing those concepts and models. We need time to become conversant in other disciplines, not only so we can use their ideas in our thinking, but so we can more effectively collaborate with scholars whose central concern IS language structure, or cognitive semantics, or ecological modeling, or complex dynamics, whatever it takes to understand the phenomena that arise as thousands of people interact with one another through a large body of literary (and theoretical) texts.
This takes time, and it takes institutional support. Such work will necessarily be cooperative and collaborative—witness the online discussion of Goldstone’s and Underwood’s work. How should promotion and tenure committees evaluate articles signed by half a dozen people? The sciences have experience with that, but the humanities do not. How do we evaluate the work of creating the infrastructure necessary to do this work—the text repositories, the software tools, and so forth. The scholarship cannot be done without that infrastructure, but creating the infrastructure doesn’t yield papers publishable in PMLA.
It’s all well and good for deans and department chairs to grab the Federal funding that’s available for digital humanities. But are they willing to create the new institutional arrangements that WILL be necessary to support the new scholarship that CAN emerge through using these tools?
Alas, color me skeptical.
Re: “most of what’s been said in the name of memes is regrettably simplistic”
I’ve spent quite a while attempting to simplify memetics and explain it in common language so that people can understand it. We do already have a tremendously complex strain of cultural evolution in academia, which is often so heavily laced with complex and impressive mathematics that few outside the inner circle and understand it. In science, simplicity is favoured by the principle of Occam’s razor. Cultural evolution is too important to be shrouded in obscure mathematics to the point where most people are incapable of understanding it.
“The study of literature is ipso facto the study of language, but linguistics education was jettisoned from literary studies years ago.” — There might be some hope, even if it’s not to be found in Britain and the US, but in places like Belgium, where both linguistics and literature graduates are reasonably well-versed in these respective disciplines. My housemate, for instance, who happens to be one of these Belgian graduates, did his main degree in literature, but is quite capable of holding a conversation on corpus analysis and linguistics (having done modules in these). Still, it’s one thing to have a grasp of the basics, and another to then have the imagination to apply such skills in ways that are fruitful.
“…tremendously complex strain of cultural evolution in academia…”
You mean Boyd and Richerson?
“Still, it’s one thing to have a grasp of the basics, and another to then have the imagination to apply such skills in ways that are fruitful.”
However, I’ve been thinking. One of my main hobbyhorses these days is description. Literary studies has to get a lot more sophisticated about description, which is mostly taken for granted and so is not done very rigorously. There isn’t even a sense that there’s something there to be rigorous about. Perhaps corpus linguistics is a way to open up that conversation.
Why? Because corpus techniques ARE descriptive. They tell you what’s there, but it’s up to you to make sense of it. And to do that you have to know something about how the description is done. And if we can get THAT going, then, who knows, maybe grammar’s next. For a grammar is a description of a language, but it’s very different from ‘ordinary’ description, whatever that is. Grammars tend to look like explanations rather than descriptions, but . . . There’s Chomsky’s old stuff on descriptive vs. explanatory adequacy in Aspects of a Theory of Syntax, which still seems relevant to me. Is that kind of discussion still kicking around?
Many of the “inclusive phenotype crowd. For example: Feldman, M. W. and Zhivotovsky L. A. (1992) Gene-culture coevolution: toward a general theory of vertical transmission. Proc Natl Acad Sci U S A. Dec 15;89(24):11935-8 – http://www.pnas.org/content/89/24/11935.full.pdf
OK, Boyd and Richerson are in that bunch.